 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Paper and Code
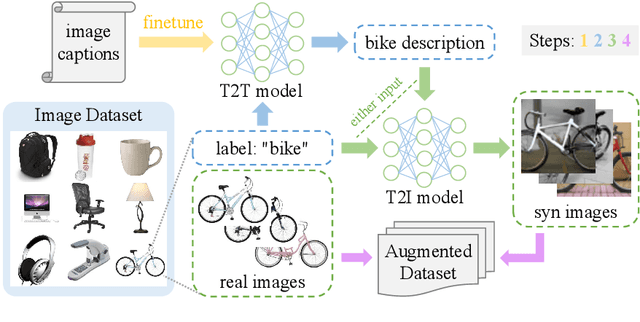
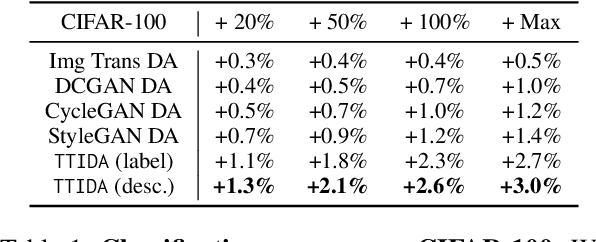
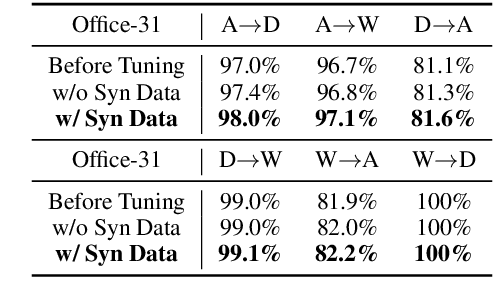
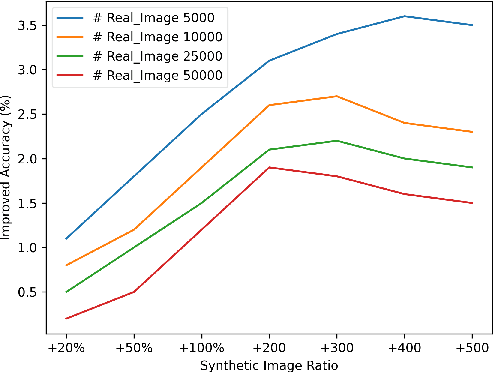
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.