 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWI: Speaking with Intent in Large Language Models
Mar 27, 2025


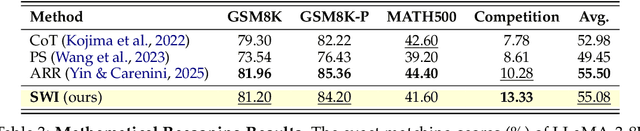
Intent, typically clearly formulated and planned, functions as a cognitive framework for reasoning and problem-solving. This paper introduces the concept of Speaking with Intent (SWI) in large language models (LLMs), where the explicitly generated intent encapsulates the model's underlying intention and provides high-level planning to guide subsequent analysis and communication. By emulating deliberate and purposeful thoughts in the human mind, SWI is hypothesized to enhance the reasoning capabilities and generation quality of LLMs. Extensive experiments on mathematical reasoning benchmarks consistently demonstrate the superiority of Speaking with Intent over Baseline (i.e., generation without explicit intent). Moreover, SWI outperforms answer-trigger prompting methods Chain-of-Thought and Plan-and-Solve and maintains competitive performance with the strong method ARR (Analyzing, Retrieving, and Reasoning). Additionally, the effectiveness and generalizability of SWI are solidified on reasoning-intensive question answering (QA) and text summarization benchmarks, where SWI brings consistent improvement to the Baseline generation. In text summarization, SWI-generated summaries exhibit greater accuracy, conciseness, and factual correctness, with fewer hallucinations. Furthermore, human evaluations verify the coherence, effectiveness, and interpretability of the intent produced by SWI. This proof-of-concept study creates a novel avenue for enhancing LLMs' reasoning abilities with cognitive notions.
ARR: Question Answering with Large Language Models via Analyzing, Retrieving, and Reasoning
Feb 07, 2025



Large language models (LLMs) achieve remarkable performance on challenging benchmarks that are often structured as multiple-choice question-answering (QA) tasks. Zero-shot Chain-of-Thought (CoT) prompting enhances reasoning in LLMs but provides only vague and generic guidance ("think step by step"). This paper introduces ARR, an intuitive and effective zero-shot prompting method that explicitly incorporates three key steps in QA solving: analyzing the intent of the question, retrieving relevant information, and reasoning step by step. Comprehensive experiments across diverse and challenging QA tasks demonstrate that ARR consistently improves the Baseline (without ARR prompting) and outperforms CoT. Ablation and case studies further validate the positive contributions of each component: analyzing, retrieving, and reasoning. Notably, intent analysis plays a vital role in ARR. Additionally, extensive evaluations across various model sizes, LLM series, and generation settings solidify the effectiveness, robustness, and generalizability of ARR.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024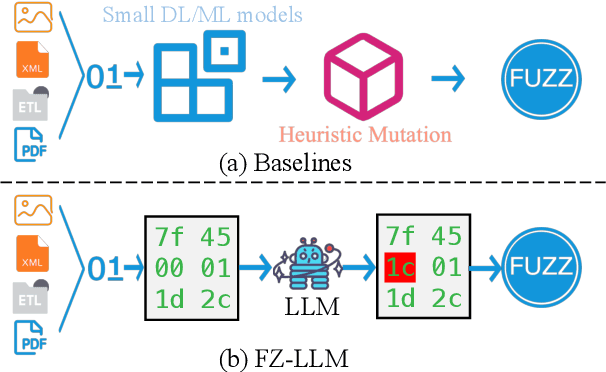
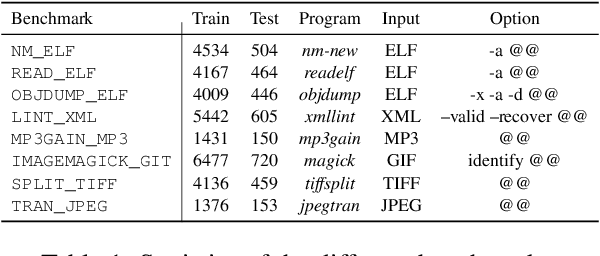
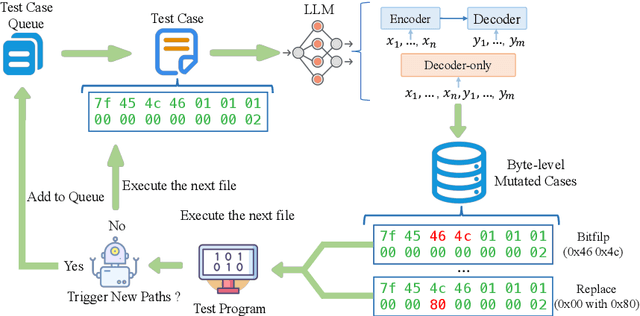
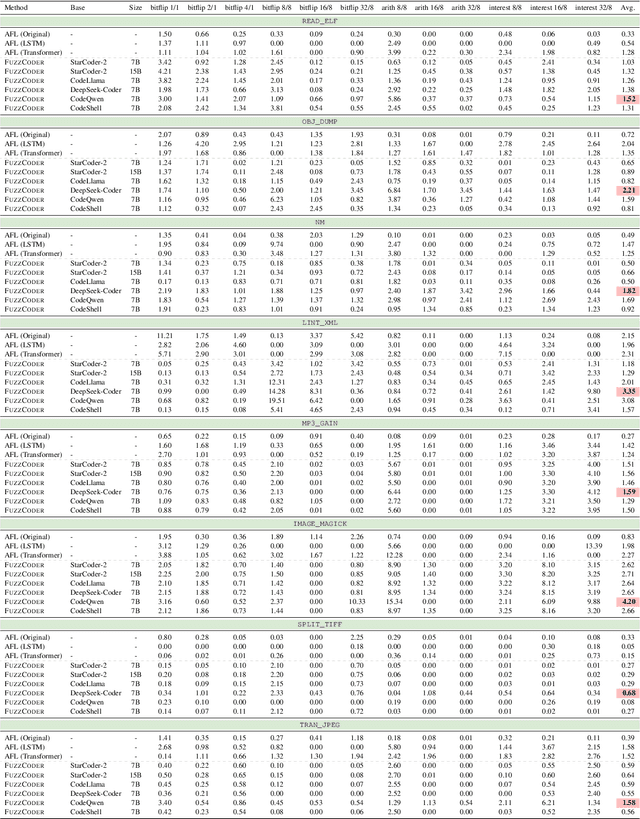
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
UniCoder: Scaling Code Large Language Model via Universal Code
Jun 24, 2024



Intermediate reasoning or acting steps have successfully improved large language models (LLMs) for handling various downstream natural language processing (NLP) tasks. When applying LLMs for code generation, recent works mainly focus on directing the models to articulate intermediate natural-language reasoning steps, as in chain-of-thought (CoT) prompting, and then output code with the natural language or other structured intermediate steps. However, such output is not suitable for code translation or generation tasks since the standard CoT has different logical structures and forms of expression with the code. In this work, we introduce the universal code (UniCode) as the intermediate representation. It is a description of algorithm steps using a mix of conventions of programming languages, such as assignment operator, conditional operator, and loop. Hence, we collect an instruction dataset UniCoder-Instruct to train our model UniCoder on multi-task learning objectives. UniCoder-Instruct comprises natural-language questions, code solutions, and the corresponding universal code. The alignment between the intermediate universal code representation and the final code solution significantly improves the quality of the generated code. The experimental results demonstrate that UniCoder with the universal code significantly outperforms the previous prompting methods by a large margin, showcasing the effectiveness of the structural clues in pseudo-code.
m3P: Towards Multimodal Multilingual Translation with Multimodal Prompt
Mar 26, 2024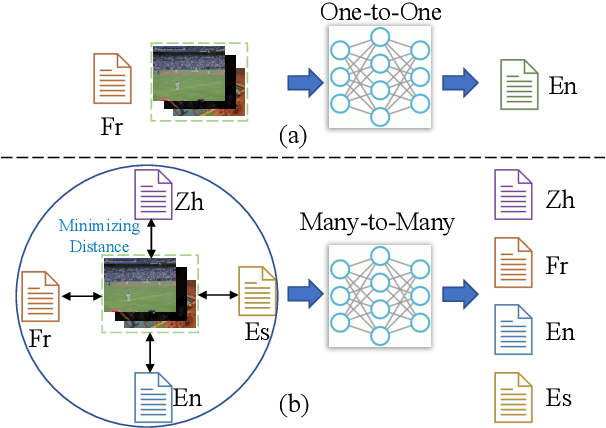
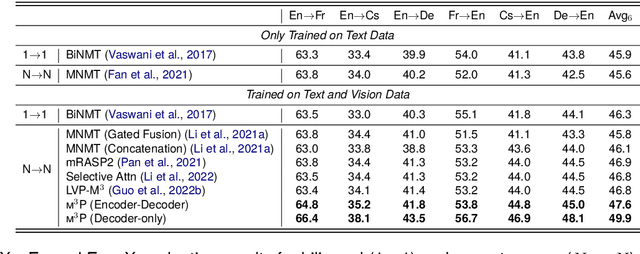
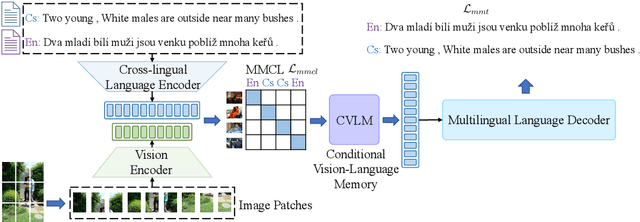
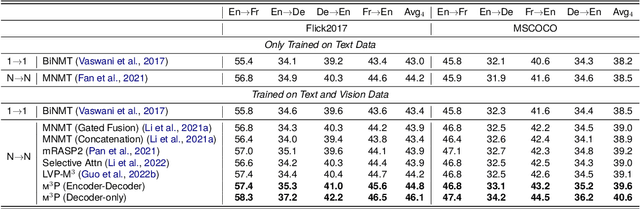
Multilingual translation supports multiple translation directions by projecting all languages in a shared space, but the translation quality is undermined by the difference between languages in the text-only modality, especially when the number of languages is large. To bridge this gap, we introduce visual context as the universal language-independent representation to facilitate multilingual translation. In this paper, we propose a framework to leverage the multimodal prompt to guide the Multimodal Multilingual neural Machine Translation (m3P), which aligns the representations of different languages with the same meaning and generates the conditional vision-language memory for translation. We construct a multilingual multimodal instruction dataset (InstrMulti102) to support 102 languages. Our method aims to minimize the representation distance of different languages by regarding the image as a central language. Experimental results show that m3P outperforms previous text-only baselines and multilingual multimodal methods by a large margin. Furthermore, the probing experiments validate the effectiveness of our method in enhancing translation under the low-resource and massively multilingual scenario.
Red Teaming Visual Language Models
Jan 23, 2024



VLMs (Vision-Language Models) extend the capabilities of LLMs (Large Language Models) to accept multimodal inputs. Since it has been verified that LLMs can be induced to generate harmful or inaccurate content through specific test cases (termed as Red Teaming), how VLMs perform in similar scenarios, especially with their combination of textual and visual inputs, remains a question. To explore this problem, we present a novel red teaming dataset RTVLM, which encompasses 10 subtasks (e.g., image misleading, multi-modal jail-breaking, face fairness, etc) under 4 primary aspects (faithfulness, privacy, safety, fairness). Our RTVLM is the first red-teaming dataset to benchmark current VLMs in terms of these 4 different aspects. Detailed analysis shows that 10 prominent open-sourced VLMs struggle with the red teaming in different degrees and have up to 31% performance gap with GPT-4V. Additionally, we simply apply red teaming alignment to LLaVA-v1.5 with Supervised Fine-tuning (SFT) using RTVLM, and this bolsters the models' performance with 10% in RTVLM test set, 13% in MM-Hal, and without noticeable decline in MM-Bench, overpassing other LLaVA-based models with regular alignment data. This reveals that current open-sourced VLMs still lack red teaming alignment. Our code and datasets will be open-source.
MT4CrossOIE: Multi-stage Tuning for Cross-lingual Open Information Extraction
Aug 12, 2023



Cross-lingual open information extraction aims to extract structured information from raw text across multiple languages. Previous work uses a shared cross-lingual pre-trained model to handle the different languages but underuses the potential of the language-specific representation. In this paper, we propose an effective multi-stage tuning framework called MT4CrossIE, designed for enhancing cross-lingual open information extraction by injecting language-specific knowledge into the shared model. Specifically, the cross-lingual pre-trained model is first tuned in a shared semantic space (e.g., embedding matrix) in the fixed encoder and then other components are optimized in the second stage. After enough training, we freeze the pre-trained model and tune the multiple extra low-rank language-specific modules using mixture-of-LoRAs for model-based cross-lingual transfer. In addition, we leverage two-stage prompting to encourage the large language model (LLM) to annotate the multi-lingual raw data for data-based cross-lingual transfer. The model is trained with multi-lingual objectives on our proposed dataset OpenIE4++ by combing the model-based and data-based transfer techniques. Experimental results on various benchmarks emphasize the importance of aggregating multiple plug-in-and-play language-specific modules and demonstrate the effectiveness of MT4CrossIE in cross-lingual OIE\footnote{\url{https://github.com/CSJianYang/Multilingual-Multimodal-NLP}}.
FinPT: Financial Risk Prediction with Profile Tuning on Pretrained Foundation Models
Jul 22, 2023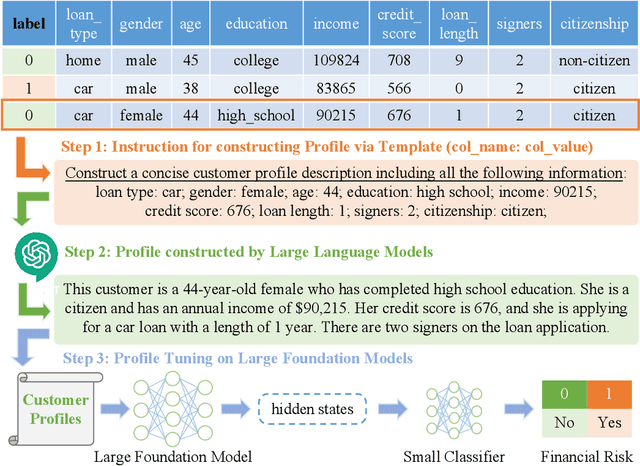
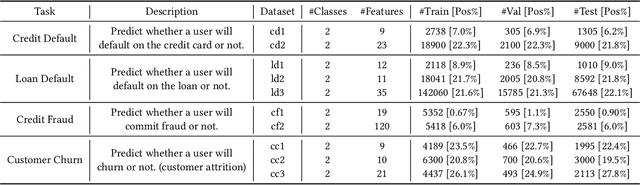
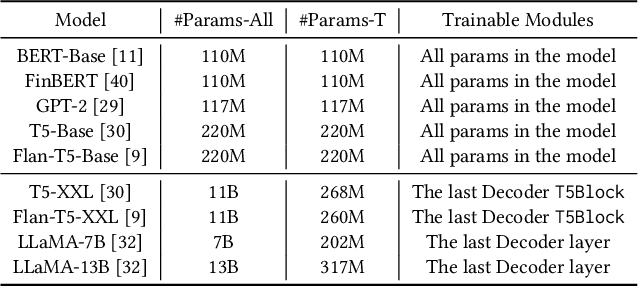
Financial risk prediction plays a crucial role in the financial sector. Machine learning methods have been widely applied for automatically detecting potential risks and thus saving the cost of labor. However, the development in this field is lagging behind in recent years by the following two facts: 1) the algorithms used are somewhat outdated, especially in the context of the fast advance of generative AI and large language models (LLMs); 2) the lack of a unified and open-sourced financial benchmark has impeded the related research for years. To tackle these issues, we propose FinPT and FinBench: the former is a novel approach for financial risk prediction that conduct Profile Tuning on large pretrained foundation models, and the latter is a set of high-quality datasets on financial risks such as default, fraud, and churn. In FinPT, we fill the financial tabular data into the pre-defined instruction template, obtain natural-language customer profiles by prompting LLMs, and fine-tune large foundation models with the profile text to make predictions. We demonstrate the effectiveness of the proposed FinPT by experimenting with a range of representative strong baselines on FinBench. The analytical studies further deepen the understanding of LLMs for financial risk prediction.
M$^3$IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
Jun 08, 2023Instruction tuning has significantly advanced large language models (LLMs) such as ChatGPT, enabling them to align with human instructions across diverse tasks. However, progress in open vision-language models (VLMs) has been limited due to the scarcity of high-quality instruction datasets. To tackle this challenge and promote research in the vision-language field, we introduce the Multi-Modal, Multilingual Instruction Tuning (M$^3$IT) dataset, designed to optimize VLM alignment with human instructions. Our M$^3$IT dataset comprises 40 carefully curated datasets, including 2.4 million instances and 400 manually written task instructions, reformatted into a vision-to-text structure. Key tasks are translated into 80 languages with an advanced translation system, ensuring broader accessibility. M$^3$IT surpasses previous datasets regarding task coverage, instruction number and instance scale. Moreover, we develop Ying-VLM, a VLM model trained on our M$^3$IT dataset, showcasing its potential to answer complex questions requiring world knowledge, generalize to unseen video tasks, and comprehend unseen instructions in Chinese. We have open-sourced the dataset to encourage further research.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023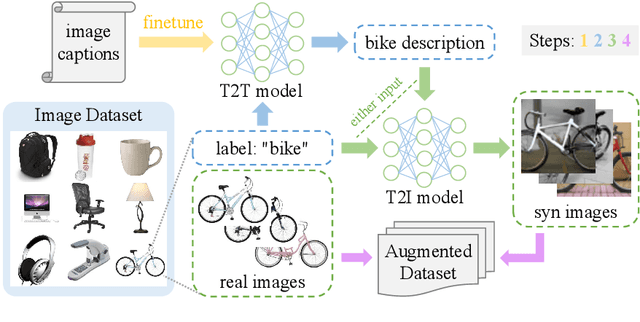
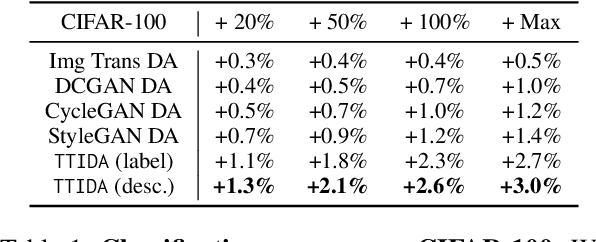
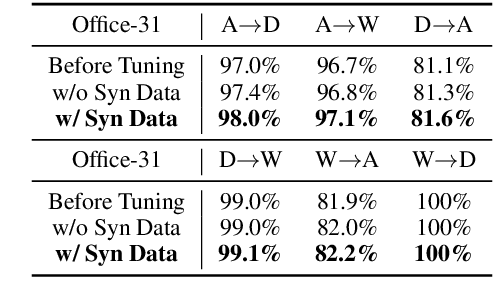
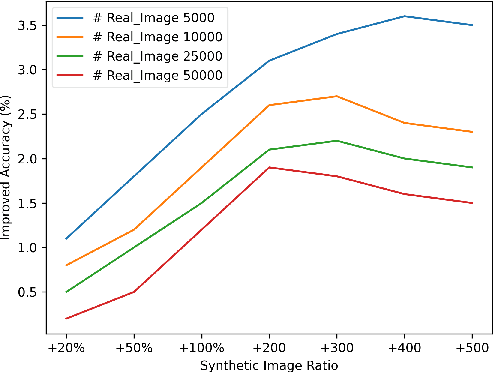
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.