 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats
Mar 12, 2026Autonomous Large Language Model (LLM) agents, exemplified by OpenClaw, demonstrate remarkable capabilities in executing complex, long-horizon tasks. However, their tightly coupled instant-messaging interaction paradigm and high-privilege execution capabilities substantially expand the system attack surface. In this paper, we present a comprehensive security threat analysis of OpenClaw. To structure our analysis, we introduce a five-layer lifecycle-oriented security framework that captures key stages of agent operation, i.e., initialization, input, inference, decision, and execution, and systematically examine compound threats across the agent's operational lifecycle, including indirect prompt injection, skill supply chain contamination, memory poisoning, and intent drift. Through detailed case studies on OpenClaw, we demonstrate the prevalence and severity of these threats and analyze the limitations of existing defenses. Our findings reveal critical weaknesses in current point-based defense mechanisms when addressing cross-temporal and multi-stage systemic risks, highlighting the need for holistic security architectures for autonomous LLM agents. Within this framework, we further examine representative defense strategies at each lifecycle stage, including plugin vetting frameworks, context-aware instruction filtering, memory integrity validation protocols, intent verification mechanisms, and capability enforcement architectures.
RF-MatID: Dataset and Benchmark for Radio Frequency Material Identification
Jan 28, 2026Accurate material identification plays a crucial role in embodied AI systems, enabling a wide range of applications. However, current vision-based solutions are limited by the inherent constraints of optical sensors, while radio-frequency (RF) approaches, which can reveal intrinsic material properties, have received growing attention. Despite this progress, RF-based material identification remains hindered by the lack of large-scale public datasets and the limited benchmarking of learning-based approaches. In this work, we present RF-MatID, the first open-source, large-scale, wide-band, and geometry-diverse RF dataset for fine-grained material identification. RF-MatID includes 16 fine-grained categories grouped into 5 superclasses, spanning a broad frequency range from 4 to 43.5 GHz, and comprises 142k samples in both frequency- and time-domain representations. The dataset systematically incorporates controlled geometry perturbations, including variations in incidence angle and stand-off distance. We further establish a multi-setting, multi-protocol benchmark by evaluating state-of-the-art deep learning models, assessing both in-distribution performance and out-of-distribution robustness under cross-angle and cross-distance shifts. The 5 frequency-allocation protocols enable systematic frequency- and region-level analysis, thereby facilitating real-world deployment. RF-MatID aims to enable reproducible research, accelerate algorithmic advancement, foster cross-domain robustness, and support the development of real-world application in RF-based material identification.
Towards Real-world Scenario: Imbalanced New Intent Discovery
Jun 05, 2024



New Intent Discovery (NID) aims at detecting known and previously undefined categories of user intent by utilizing limited labeled and massive unlabeled data. Most prior works often operate under the unrealistic assumption that the distribution of both familiar and new intent classes is uniform, overlooking the skewed and long-tailed distributions frequently encountered in real-world scenarios. To bridge the gap, our work introduces the imbalanced new intent discovery (i-NID) task, which seeks to identify familiar and novel intent categories within long-tailed distributions. A new benchmark (ImbaNID-Bench) comprised of three datasets is created to simulate the real-world long-tail distributions. ImbaNID-Bench ranges from broad cross-domain to specific single-domain intent categories, providing a thorough representation of practical use cases. Besides, a robust baseline model ImbaNID is proposed to achieve cluster-friendly intent representations. It includes three stages: model pre-training, generation of reliable pseudo-labels, and robust representation learning that strengthens the model performance to handle the intricacies of real-world data distributions. Our extensive experiments on previous benchmarks and the newly established benchmark demonstrate the superior performance of ImbaNID in addressing the i-NID task, highlighting its potential as a powerful baseline for uncovering and categorizing user intents in imbalanced and long-tailed distributions\footnote{\url{https://github.com/Zkdc/i-NID}}.
RoNID: New Intent Discovery with Generated-Reliable Labels and Cluster-friendly Representations
Apr 13, 2024



New Intent Discovery (NID) strives to identify known and reasonably deduce novel intent groups in the open-world scenario. But current methods face issues with inaccurate pseudo-labels and poor representation learning, creating a negative feedback loop that degrades overall model performance, including accuracy and the adjusted rand index. To address the aforementioned challenges, we propose a Robust New Intent Discovery (RoNID) framework optimized by an EM-style method, which focuses on constructing reliable pseudo-labels and obtaining cluster-friendly discriminative representations. RoNID comprises two main modules: reliable pseudo-label generation module and cluster-friendly representation learning module. Specifically, the pseudo-label generation module assigns reliable synthetic labels by solving an optimal transport problem in the E-step, which effectively provides high-quality supervised signals for the input of the cluster-friendly representation learning module. To learn cluster-friendly representation with strong intra-cluster compactness and large inter-cluster separation, the representation learning module combines intra-cluster and inter-cluster contrastive learning in the M-step to feed more discriminative features into the generation module. RoNID can be performed iteratively to ultimately yield a robust model with reliable pseudo-labels and cluster-friendly representations. Experimental results on multiple benchmarks demonstrate our method brings substantial improvements over previous state-of-the-art methods by a large margin of +1~+4 points.
m3P: Towards Multimodal Multilingual Translation with Multimodal Prompt
Mar 26, 2024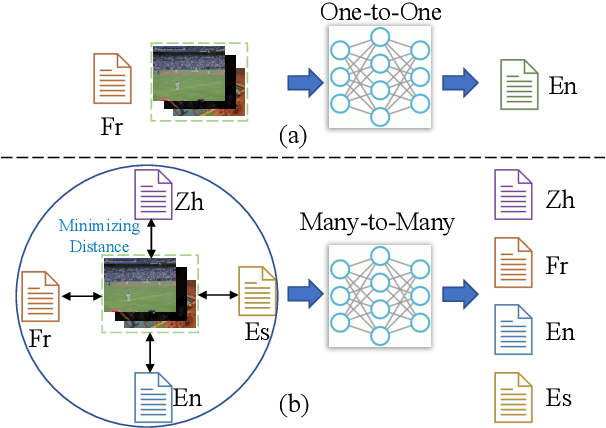
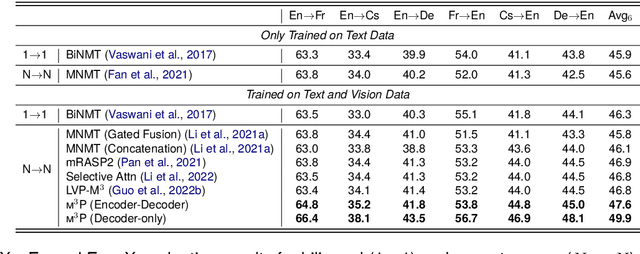
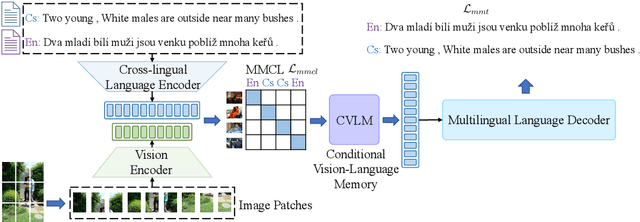
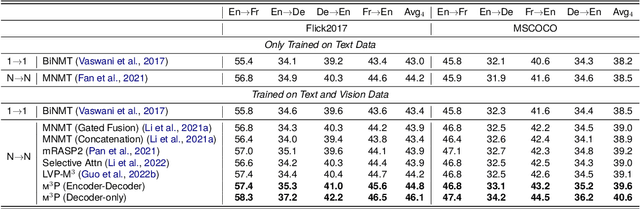
Multilingual translation supports multiple translation directions by projecting all languages in a shared space, but the translation quality is undermined by the difference between languages in the text-only modality, especially when the number of languages is large. To bridge this gap, we introduce visual context as the universal language-independent representation to facilitate multilingual translation. In this paper, we propose a framework to leverage the multimodal prompt to guide the Multimodal Multilingual neural Machine Translation (m3P), which aligns the representations of different languages with the same meaning and generates the conditional vision-language memory for translation. We construct a multilingual multimodal instruction dataset (InstrMulti102) to support 102 languages. Our method aims to minimize the representation distance of different languages by regarding the image as a central language. Experimental results show that m3P outperforms previous text-only baselines and multilingual multimodal methods by a large margin. Furthermore, the probing experiments validate the effectiveness of our method in enhancing translation under the low-resource and massively multilingual scenario.
New Intent Discovery with Attracting and Dispersing Prototype
Mar 25, 2024
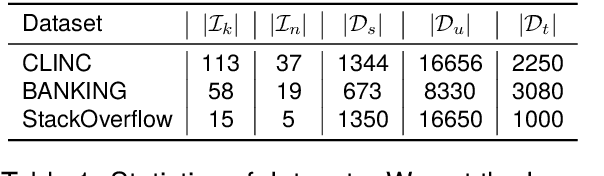

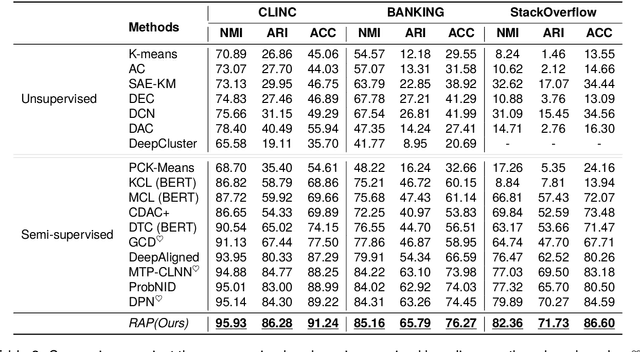
New Intent Discovery (NID) aims to recognize known and infer new intent categories with the help of limited labeled and large-scale unlabeled data. The task is addressed as a feature-clustering problem and recent studies augment instance representation. However, existing methods fail to capture cluster-friendly representations, since they show less capability to effectively control and coordinate within-cluster and between-cluster distances. Tailored to the NID problem, we propose a Robust and Adaptive Prototypical learning (RAP) framework for globally distinct decision boundaries for both known and new intent categories. Specifically, a robust prototypical attracting learning (RPAL) method is designed to compel instances to gravitate toward their corresponding prototype, achieving greater within-cluster compactness. To attain larger between-cluster separation, another adaptive prototypical dispersing learning (APDL) method is devised to maximize the between-cluster distance from the prototype-to-prototype perspective. Experimental results evaluated on three challenging benchmarks (CLINC, BANKING, and StackOverflow) of our method with better cluster-friendly representation demonstrate that RAP brings in substantial improvements over the current state-of-the-art methods (even large language model) by a large margin (average +5.5% improvement).
xCoT: Cross-lingual Instruction Tuning for Cross-lingual Chain-of-Thought Reasoning
Jan 13, 2024Chain-of-thought (CoT) has emerged as a powerful technique to elicit reasoning in large language models and improve a variety of downstream tasks. CoT mainly demonstrates excellent performance in English, but its usage in low-resource languages is constrained due to poor language generalization. To bridge the gap among different languages, we propose a cross-lingual instruction fine-tuning framework (xCOT) to transfer knowledge from high-resource languages to low-resource languages. Specifically, the multilingual instruction training data (xCOT-INSTRUCT) is created to encourage the semantic alignment of multiple languages. We introduce cross-lingual in-context few-shot learning (xICL)) to accelerate multilingual agreement in instruction tuning, where some fragments of source languages in examples are randomly substituted by their counterpart translations of target languages. During multilingual instruction tuning, we adopt the randomly online CoT strategy to enhance the multilingual reasoning ability of the large language model by first translating the query to another language and then answering in English. To further facilitate the language transfer, we leverage the high-resource CoT to supervise the training of low-resource languages with cross-lingual distillation. Experimental results on previous benchmarks demonstrate the superior performance of xCoT in reducing the gap among different languages, highlighting its potential to reduce the cross-lingual gap.
LogFormer: A Pre-train and Tuning Pipeline for Log Anomaly Detection
Jan 09, 2024



Log anomaly detection is a key component in the field of artificial intelligence for IT operations (AIOps). Considering log data of variant domains, retraining the whole network for unknown domains is inefficient in real industrial scenarios. However, previous deep models merely focused on extracting the semantics of log sequences in the same domain, leading to poor generalization on multi-domain logs. To alleviate this issue, we propose a unified Transformer-based framework for Log anomaly detection (LogFormer) to improve the generalization ability across different domains, where we establish a two-stage process including the pre-training and adapter-based tuning stage. Specifically, our model is first pre-trained on the source domain to obtain shared semantic knowledge of log data. Then, we transfer such knowledge to the target domain via shared parameters. Besides, the Log-Attention module is proposed to supplement the information ignored by the log-paring. The proposed method is evaluated on three public and one real-world datasets. Experimental results on multiple benchmarks demonstrate the effectiveness of our LogFormer with fewer trainable parameters and lower training costs.
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Dec 26, 2023
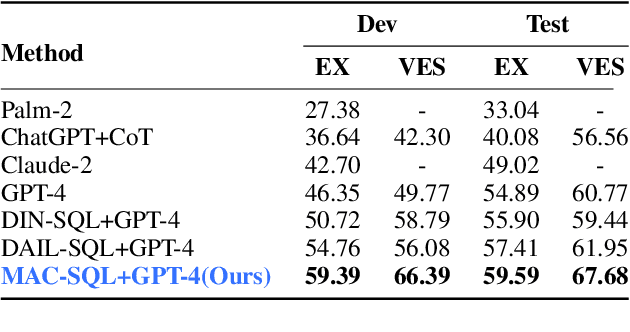
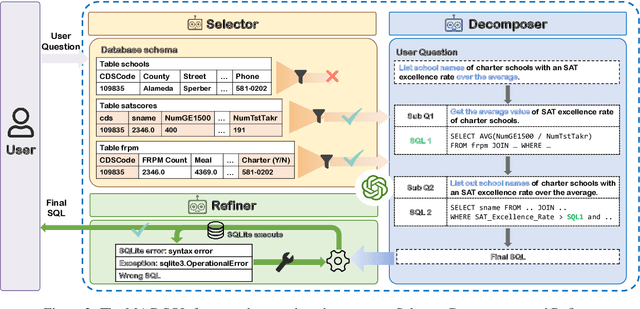

Recent advancements in Text-to-SQL methods employing Large Language Models (LLMs) have demonstrated remarkable performance. Nonetheless, these approaches continue to encounter difficulties when handling extensive databases, intricate user queries, and erroneous SQL results. To tackle these challenges, we present \textsc{MAC-SQL}, a novel LLM-based multi-agent collaborative framework designed for the Text-to-SQL task. Our framework comprises three agents: the \textit{Selector}, accountable for condensing voluminous databases and preserving relevant table schemas for user questions; the \textit{Decomposer}, which disassembles complex user questions into more straightforward sub-problems and resolves them progressively; and the \textit{Refiner}, tasked with validating and refining defective SQL queries. We perform comprehensive experiments on two Text-to-SQL datasets, BIRD and Spider, achieving a state-of-the-art execution accuracy of 59.59\% on the BIRD test set. Moreover, we have open-sourced an instruction fine-tuning model, SQL-Llama, based on Code Llama 7B, in addition to an agent instruction dataset derived from training data based on BIRD and Spider. The SQL-Llama model has demonstrated encouraging results on the development sets of both BIRD and Spider. However, when compared to GPT-4, there remains a notable potential for enhancement. Our code and data are publicly available at https://github.com/wbbeyourself/MAC-SQL.
M2C: Towards Automatic Multimodal Manga Complement
Oct 26, 2023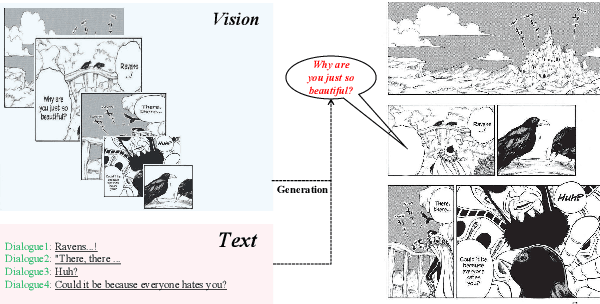
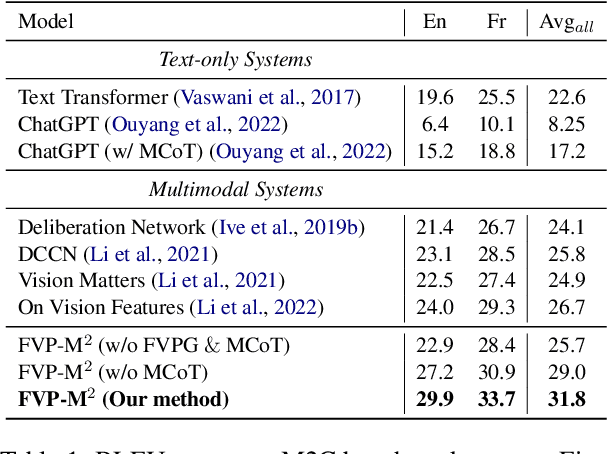
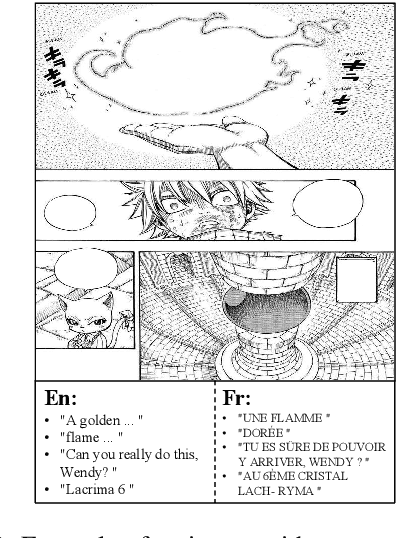

Multimodal manga analysis focuses on enhancing manga understanding with visual and textual features, which has attracted considerable attention from both natural language processing and computer vision communities. Currently, most comics are hand-drawn and prone to problems such as missing pages, text contamination, and aging, resulting in missing comic text content and seriously hindering human comprehension. In other words, the Multimodal Manga Complement (M2C) task has not been investigated, which aims to handle the aforementioned issues by providing a shared semantic space for vision and language understanding. To this end, we first propose the Multimodal Manga Complement task by establishing a new M2C benchmark dataset covering two languages. First, we design a manga argumentation method called MCoT to mine event knowledge in comics with large language models. Then, an effective baseline FVP-M$^{2}$ using fine-grained visual prompts is proposed to support manga complement. Extensive experimental results show the effectiveness of FVP-M$^{2}$ method for Multimodal Mange Complement.