 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Collaboration for Multilingual Code Instruction Tuning
Feb 11, 2025Recent advancement in code understanding and generation demonstrates that code LLMs fine-tuned on a high-quality instruction dataset can gain powerful capabilities to address wide-ranging code-related tasks. However, most previous existing methods mainly view each programming language in isolation and ignore the knowledge transfer among different programming languages. To bridge the gap among different programming languages, we introduce a novel multi-agent collaboration framework to enhance multilingual instruction tuning for code LLMs, where multiple language-specific intelligent agent components with generation memory work together to transfer knowledge from one language to another efficiently and effectively. Specifically, we first generate the language-specific instruction data from the code snippets and then provide the generated data as the seed data for language-specific agents. Multiple language-specific agents discuss and collaborate to formulate a new instruction and its corresponding solution (A new programming language or existing programming language), To further encourage the cross-lingual transfer, each agent stores its generation history as memory and then summarizes its merits and faults. Finally, the high-quality multilingual instruction data is used to encourage knowledge transfer among different programming languages to train Qwen2.5-xCoder. Experimental results on multilingual programming benchmarks demonstrate the superior performance of Qwen2.5-xCoder in sharing common knowledge, highlighting its potential to reduce the cross-lingual gap.
CryptoX : Compositional Reasoning Evaluation of Large Language Models
Feb 08, 2025



The compositional reasoning capacity has long been regarded as critical to the generalization and intelligence emergence of large language models LLMs. However, despite numerous reasoning-related benchmarks, the compositional reasoning capacity of LLMs is rarely studied or quantified in the existing benchmarks. In this paper, we introduce CryptoX, an evaluation framework that, for the first time, combines existing benchmarks and cryptographic, to quantify the compositional reasoning capacity of LLMs. Building upon CryptoX, we construct CryptoBench, which integrates these principles into several benchmarks for systematic evaluation. We conduct detailed experiments on widely used open-source and closed-source LLMs using CryptoBench, revealing a huge gap between open-source and closed-source LLMs. We further conduct thorough mechanical interpretability experiments to reveal the inner mechanism of LLMs' compositional reasoning, involving subproblem decomposition, subproblem inference, and summarizing subproblem conclusions. Through analysis based on CryptoBench, we highlight the value of independently studying compositional reasoning and emphasize the need to enhance the compositional reasoning capabilities of LLMs.
Evaluating and Aligning CodeLLMs on Human Preference
Dec 06, 2024



Code large language models (codeLLMs) have made significant strides in code generation. Most previous code-related benchmarks, which consist of various programming exercises along with the corresponding test cases, are used as a common measure to evaluate the performance and capabilities of code LLMs. However, the current code LLMs focus on synthesizing the correct code snippet, ignoring the alignment with human preferences, where the query should be sampled from the practical application scenarios and the model-generated responses should satisfy the human preference. To bridge the gap between the model-generated response and human preference, we present a rigorous human-curated benchmark CodeArena to emulate the complexity and diversity of real-world coding tasks, where 397 high-quality samples spanning 40 categories and 44 programming languages, carefully curated from user queries. Further, we propose a diverse synthetic instruction corpus SynCode-Instruct (nearly 20B tokens) by scaling instructions from the website to verify the effectiveness of the large-scale synthetic instruction fine-tuning, where Qwen2.5-SynCoder totally trained on synthetic instruction data can achieve top-tier performance of open-source code LLMs. The results find performance differences between execution-based benchmarks and CodeArena. Our systematic experiments of CodeArena on 40+ LLMs reveal a notable performance gap between open SOTA code LLMs (e.g. Qwen2.5-Coder) and proprietary LLMs (e.g., OpenAI o1), underscoring the importance of the human preference alignment.\footnote{\url{https://codearenaeval.github.io/ }}
MdEval: Massively Multilingual Code Debugging
Nov 04, 2024



Code large language models (LLMs) have made significant progress in code debugging by directly generating the correct code based on the buggy code snippet. Programming benchmarks, typically consisting of buggy code snippet and their associated test cases, are used to assess the debugging capabilities of LLMs. However, many existing benchmarks primarily focus on Python and are often limited in terms of language diversity (e.g., DebugBench and DebugEval). To advance the field of multilingual debugging with LLMs, we propose the first massively multilingual debugging benchmark, which includes 3.6K test samples of 18 programming languages and covers the automated program repair (APR) task, the code review (CR) task, and the bug identification (BI) task. Further, we introduce the debugging instruction corpora MDEVAL-INSTRUCT by injecting bugs into the correct multilingual queries and solutions (xDebugGen). Further, a multilingual debugger xDebugCoder trained on MDEVAL-INSTRUCT as a strong baseline specifically to handle the bugs of a wide range of programming languages (e.g. "Missing Mut" in language Rust and "Misused Macro Definition" in language C). Our extensive experiments on MDEVAL reveal a notable performance gap between open-source models and closed-source LLMs (e.g., GPT and Claude series), highlighting huge room for improvement in multilingual code debugging scenarios.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
Sep 03, 2024
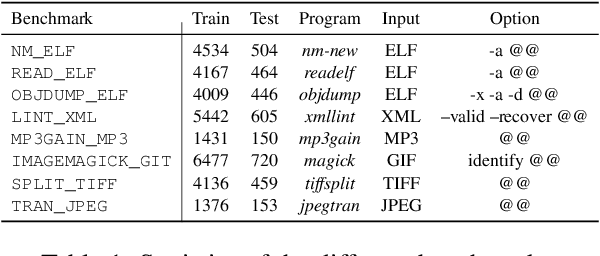
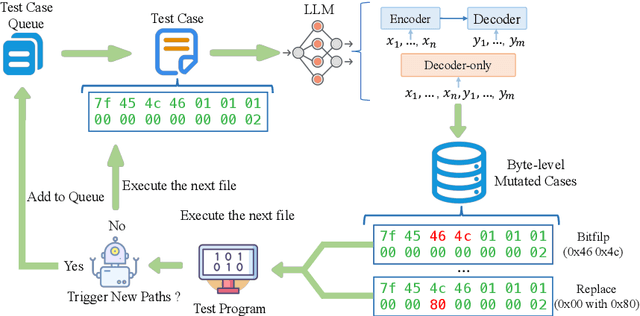
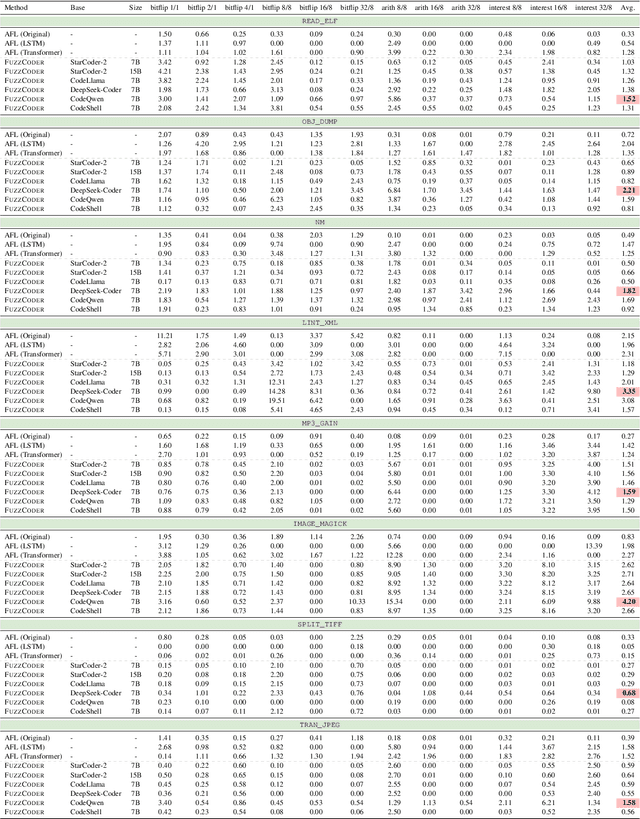
Fuzzing is an important dynamic program analysis technique designed for finding vulnerabilities in complex software. Fuzzing involves presenting a target program with crafted malicious input to cause crashes, buffer overflows, memory errors, and exceptions. Crafting malicious inputs in an efficient manner is a difficult open problem and the best approaches often apply uniform random mutations to pre-existing valid inputs. In this work, we propose to adopt fine-tuned large language models (FuzzCoder) to learn patterns in the input files from successful attacks to guide future fuzzing explorations. Specifically, we develop a framework to leverage the code LLMs to guide the mutation process of inputs in fuzzing. The mutation process is formulated as the sequence-to-sequence modeling, where LLM receives a sequence of bytes and then outputs the mutated byte sequence. FuzzCoder is fine-tuned on the created instruction dataset (Fuzz-Instruct), where the successful fuzzing history is collected from the heuristic fuzzing tool. FuzzCoder can predict mutation locations and strategies locations in input files to trigger abnormal behaviors of the program. Experimental results show that FuzzCoder based on AFL (American Fuzzy Lop) gain significant improvements in terms of effective proportion of mutation (EPM) and number of crashes (NC) for various input formats including ELF, JPG, MP3, and XML.
UniCoder: Scaling Code Large Language Model via Universal Code
Jun 24, 2024



Intermediate reasoning or acting steps have successfully improved large language models (LLMs) for handling various downstream natural language processing (NLP) tasks. When applying LLMs for code generation, recent works mainly focus on directing the models to articulate intermediate natural-language reasoning steps, as in chain-of-thought (CoT) prompting, and then output code with the natural language or other structured intermediate steps. However, such output is not suitable for code translation or generation tasks since the standard CoT has different logical structures and forms of expression with the code. In this work, we introduce the universal code (UniCode) as the intermediate representation. It is a description of algorithm steps using a mix of conventions of programming languages, such as assignment operator, conditional operator, and loop. Hence, we collect an instruction dataset UniCoder-Instruct to train our model UniCoder on multi-task learning objectives. UniCoder-Instruct comprises natural-language questions, code solutions, and the corresponding universal code. The alignment between the intermediate universal code representation and the final code solution significantly improves the quality of the generated code. The experimental results demonstrate that UniCoder with the universal code significantly outperforms the previous prompting methods by a large margin, showcasing the effectiveness of the structural clues in pseudo-code.
m3P: Towards Multimodal Multilingual Translation with Multimodal Prompt
Mar 26, 2024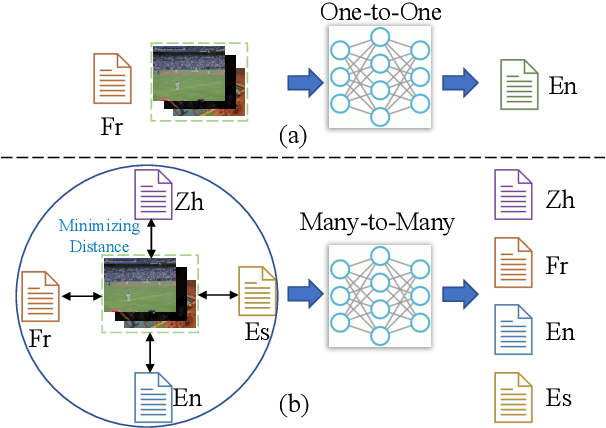
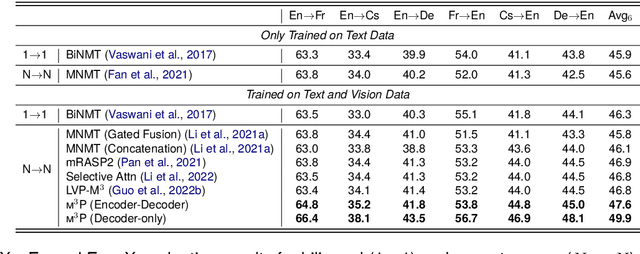
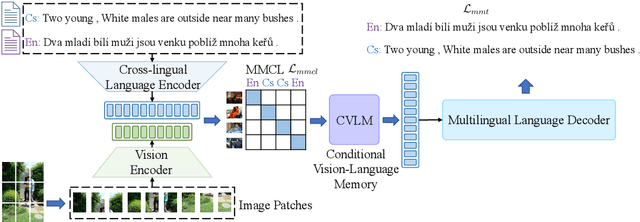
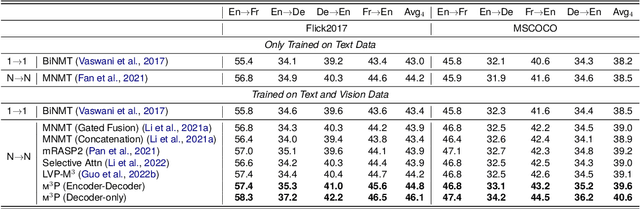
Multilingual translation supports multiple translation directions by projecting all languages in a shared space, but the translation quality is undermined by the difference between languages in the text-only modality, especially when the number of languages is large. To bridge this gap, we introduce visual context as the universal language-independent representation to facilitate multilingual translation. In this paper, we propose a framework to leverage the multimodal prompt to guide the Multimodal Multilingual neural Machine Translation (m3P), which aligns the representations of different languages with the same meaning and generates the conditional vision-language memory for translation. We construct a multilingual multimodal instruction dataset (InstrMulti102) to support 102 languages. Our method aims to minimize the representation distance of different languages by regarding the image as a central language. Experimental results show that m3P outperforms previous text-only baselines and multilingual multimodal methods by a large margin. Furthermore, the probing experiments validate the effectiveness of our method in enhancing translation under the low-resource and massively multilingual scenario.
OWL: A Large Language Model for IT Operations
Sep 17, 2023



With the rapid development of IT operations, it has become increasingly crucial to efficiently manage and analyze large volumes of data for practical applications. The techniques of Natural Language Processing (NLP) have shown remarkable capabilities for various tasks, including named entity recognition, machine translation and dialogue systems. Recently, Large Language Models (LLMs) have achieved significant improvements across various NLP downstream tasks. However, there is a lack of specialized LLMs for IT operations. In this paper, we introduce the OWL, a large language model trained on our collected OWL-Instruct dataset with a wide range of IT-related information, where the mixture-of-adapter strategy is proposed to improve the parameter-efficient tuning across different domains or tasks. Furthermore, we evaluate the performance of our OWL on the OWL-Bench established by us and open IT-related benchmarks. OWL demonstrates superior performance results on IT tasks, which outperforms existing models by significant margins. Moreover, we hope that the findings of our work will provide more insights to revolutionize the techniques of IT operations with specialized LLMs.
MT4CrossOIE: Multi-stage Tuning for Cross-lingual Open Information Extraction
Aug 12, 2023



Cross-lingual open information extraction aims to extract structured information from raw text across multiple languages. Previous work uses a shared cross-lingual pre-trained model to handle the different languages but underuses the potential of the language-specific representation. In this paper, we propose an effective multi-stage tuning framework called MT4CrossIE, designed for enhancing cross-lingual open information extraction by injecting language-specific knowledge into the shared model. Specifically, the cross-lingual pre-trained model is first tuned in a shared semantic space (e.g., embedding matrix) in the fixed encoder and then other components are optimized in the second stage. After enough training, we freeze the pre-trained model and tune the multiple extra low-rank language-specific modules using mixture-of-LoRAs for model-based cross-lingual transfer. In addition, we leverage two-stage prompting to encourage the large language model (LLM) to annotate the multi-lingual raw data for data-based cross-lingual transfer. The model is trained with multi-lingual objectives on our proposed dataset OpenIE4++ by combing the model-based and data-based transfer techniques. Experimental results on various benchmarks emphasize the importance of aggregating multiple plug-in-and-play language-specific modules and demonstrate the effectiveness of MT4CrossIE in cross-lingual OIE\footnote{\url{https://github.com/CSJianYang/Multilingual-Multimodal-NLP}}.
QURG: Question Rewriting Guided Context-Dependent Text-to-SQL Semantic Parsing
May 16, 2023Context-dependent Text-to-SQL aims to translate multi-turn natural language questions into SQL queries. Despite various methods have exploited context-dependence information implicitly for contextual SQL parsing, there are few attempts to explicitly address the dependencies between current question and question context. This paper presents QURG, a novel Question Rewriting Guided approach to help the models achieve adequate contextual understanding. Specifically, we first train a question rewriting model to complete the current question based on question context, and convert them into a rewriting edit matrix. We further design a two-stream matrix encoder to jointly model the rewriting relations between question and context, and the schema linking relations between natural language and structured schema. Experimental results show that QURG significantly improves the performances on two large-scale context-dependent datasets SParC and CoSQL, especially for hard and long-turn questions.