 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Latent Reasoning via Looped Language Models
Oct 29, 2025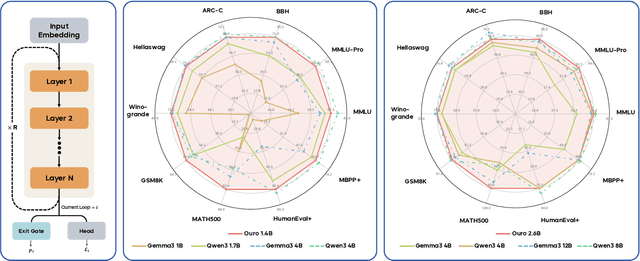
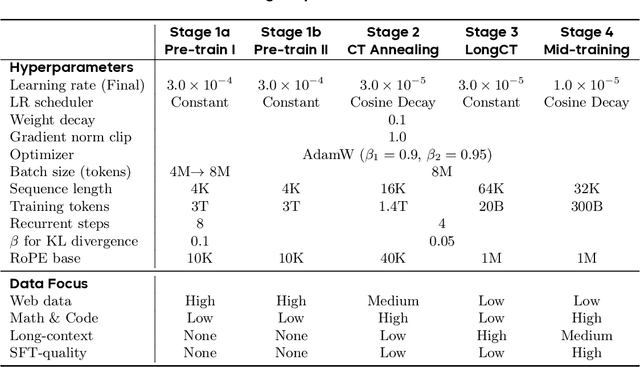
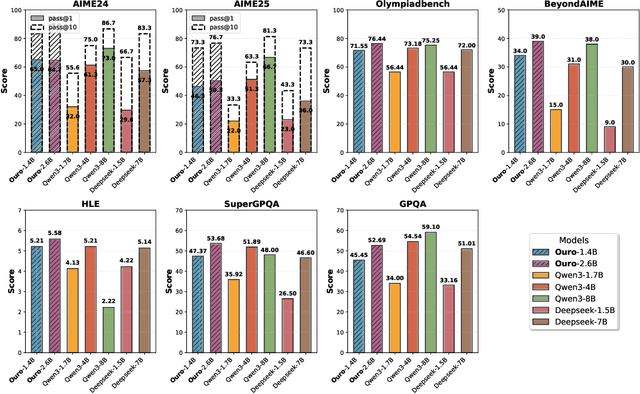

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
P2P: Automated Paper-to-Poster Generation and Fine-Grained Benchmark
May 21, 2025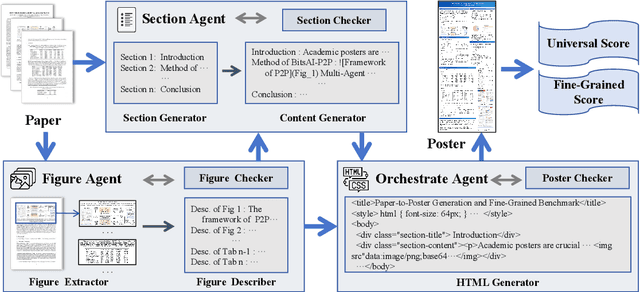
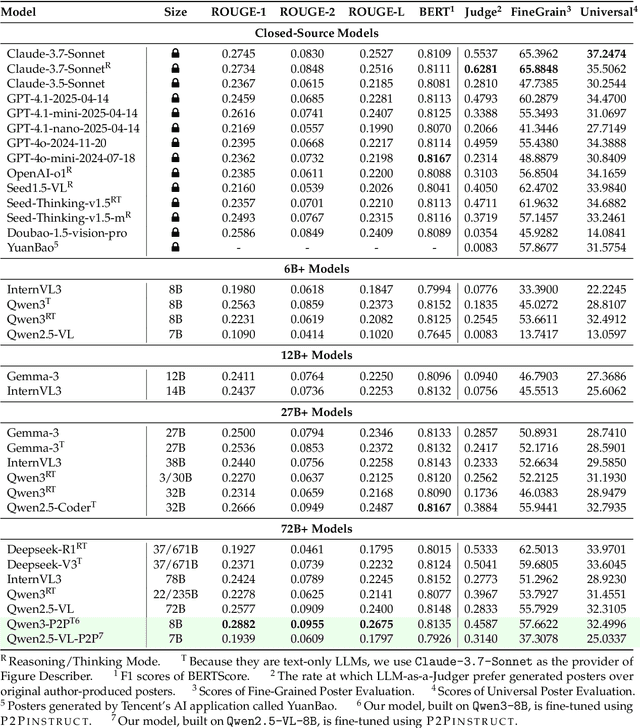


Academic posters are vital for scholarly communication, yet their manual creation is time-consuming. However, automated academic poster generation faces significant challenges in preserving intricate scientific details and achieving effective visual-textual integration. Existing approaches often struggle with semantic richness and structural nuances, and lack standardized benchmarks for evaluating generated academic posters comprehensively. To address these limitations, we introduce P2P, the first flexible, LLM-based multi-agent framework that generates high-quality, HTML-rendered academic posters directly from research papers, demonstrating strong potential for practical applications. P2P employs three specialized agents-for visual element processing, content generation, and final poster assembly-each integrated with dedicated checker modules to enable iterative refinement and ensure output quality. To foster advancements and rigorous evaluation in this domain, we construct and release P2PInstruct, the first large-scale instruction dataset comprising over 30,000 high-quality examples tailored for the academic paper-to-poster generation task. Furthermore, we establish P2PEval, a comprehensive benchmark featuring 121 paper-poster pairs and a dual evaluation methodology (Universal and Fine-Grained) that leverages LLM-as-a-Judge and detailed, human-annotated checklists. Our contributions aim to streamline research dissemination and provide the community with robust tools for developing and evaluating next-generation poster generation systems.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025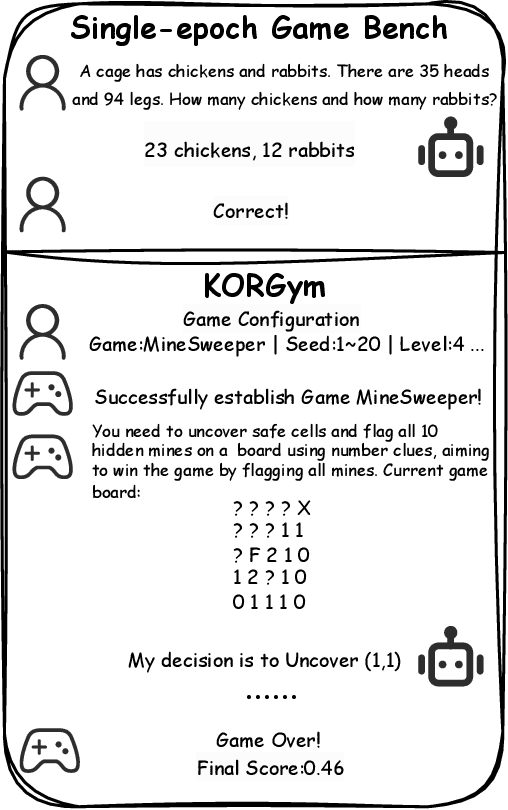
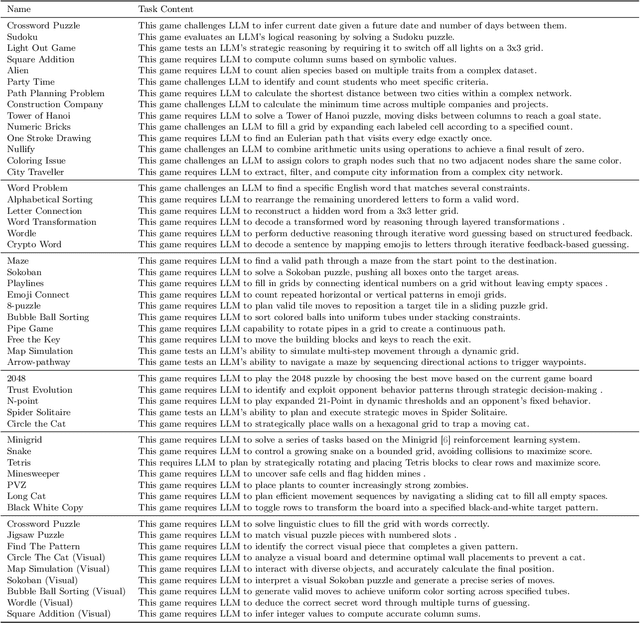
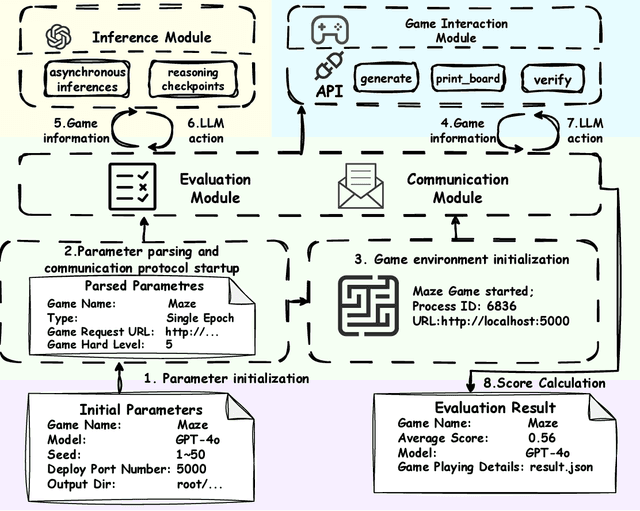

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
CryptoX : Compositional Reasoning Evaluation of Large Language Models
Feb 08, 2025The compositional reasoning capacity has long been regarded as critical to the generalization and intelligence emergence of large language models LLMs. However, despite numerous reasoning-related benchmarks, the compositional reasoning capacity of LLMs is rarely studied or quantified in the existing benchmarks. In this paper, we introduce CryptoX, an evaluation framework that, for the first time, combines existing benchmarks and cryptographic, to quantify the compositional reasoning capacity of LLMs. Building upon CryptoX, we construct CryptoBench, which integrates these principles into several benchmarks for systematic evaluation. We conduct detailed experiments on widely used open-source and closed-source LLMs using CryptoBench, revealing a huge gap between open-source and closed-source LLMs. We further conduct thorough mechanical interpretability experiments to reveal the inner mechanism of LLMs' compositional reasoning, involving subproblem decomposition, subproblem inference, and summarizing subproblem conclusions. Through analysis based on CryptoBench, we highlight the value of independently studying compositional reasoning and emphasize the need to enhance the compositional reasoning capabilities of LLMs.
MdEval: Massively Multilingual Code Debugging
Nov 04, 2024



Code large language models (LLMs) have made significant progress in code debugging by directly generating the correct code based on the buggy code snippet. Programming benchmarks, typically consisting of buggy code snippet and their associated test cases, are used to assess the debugging capabilities of LLMs. However, many existing benchmarks primarily focus on Python and are often limited in terms of language diversity (e.g., DebugBench and DebugEval). To advance the field of multilingual debugging with LLMs, we propose the first massively multilingual debugging benchmark, which includes 3.6K test samples of 18 programming languages and covers the automated program repair (APR) task, the code review (CR) task, and the bug identification (BI) task. Further, we introduce the debugging instruction corpora MDEVAL-INSTRUCT by injecting bugs into the correct multilingual queries and solutions (xDebugGen). Further, a multilingual debugger xDebugCoder trained on MDEVAL-INSTRUCT as a strong baseline specifically to handle the bugs of a wide range of programming languages (e.g. "Missing Mut" in language Rust and "Misused Macro Definition" in language C). Our extensive experiments on MDEVAL reveal a notable performance gap between open-source models and closed-source LLMs (e.g., GPT and Claude series), highlighting huge room for improvement in multilingual code debugging scenarios.