 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Aware Stochastic KV Cache Eviction for Reasoning Models
Jun 02, 2026Reasoning models improve accuracy through extended chains of thought, but their long outputs create a memory and compute bottleneck. KV cache eviction methods reduce this cost by evicting unimportant key-value pairs from the cache, yet they often yield worse accuracy than selection-based sparse attention alternatives, which keep the full KV cache. We identify key factors crucial to KV cache eviction accuracy. First, a small fraction of value states have abnormally large magnitudes, and evicting them causes catastrophic failure where models enter repetitive reasoning loops. Second, introducing stochasticity during eviction improves accuracy by increasing cache diversity. Based on these findings, we propose Value-aware Stochastic KV Cache Eviction (VaSE), a training-free recipe that protects large-magnitude value states and promotes diverse eviction decisions. Across six reasoning tasks, Qwen3 models using VaSE with 4x KV cache compression yield higher average accuracies than SOTA selection method at the same sparsity, while outperforming the strongest eviction method by more than 4%. Overall, VaSE bridges the gap between efficiency and accuracy, supporting FlashAttention2 and enabling a static memory footprint for reasoning models.
UMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
The Chameleon's Limit: Investigating Persona Collapse and Homogenization in Large Language Models
Apr 27, 2026Applications based on large language models (LLMs), such as multi-agent simulations, require population diversity among agents. We identify a pervasive failure mode we term \emph{Persona Collapse}: agents each assigned a distinct profile nonetheless converge into a narrow behavioral mode, producing a homogeneous simulated population. To quantify persona collapse, we propose a framework that measures how much of the persona space a population occupies (Coverage), how evenly agents spread across it (Uniformity), and how rich the resulting behavioral patterns are (Complexity). Evaluating ten LLMs on personality simulation (BFI-44), moral reasoning, and self-introduction, we observe persona collapse along two axes: (1) Dimensions: a model can appear diverse on one axis yet structurally degenerate on another, and (2) Domains: the same model may collapse the most in personality yet be the most diverse in moral reasoning. Furthermore, item-level diagnostics reveal that behavioral variation tracks coarse demographic stereotypes rather than the fine-grained individual differences specified in each persona. Counter-intuitively, \textbf{the models achieving the highest per-persona fidelity consistently produce the most stereotyped populations}. We release our toolkit and data to support population-level evaluation of LLMs.
When Agents Look the Same: Quantifying Distillation-Induced Similarity in Tool-Use Behaviors
Apr 23, 2026Model distillation is a primary driver behind the rapid progress of LLM agents, yet it often leads to behavioral homogenization. Many emerging agents share nearly identical reasoning steps and failure modes, suggesting they may be distilled echoes of a few dominant teachers. Existing metrics, however, fail to distinguish mandatory behaviors required for task success from non-mandatory patterns that reflect a model's autonomous preferences. We propose two complementary metrics to isolate non-mandatory behavioral patterns: \textbf{Response Pattern Similarity (RPS)} for verbal alignment and \textbf{Action Graph Similarity (AGS)} for tool-use habits modeled as directed graphs. Evaluating 18 models from 8 providers on $τ$-Bench and $τ^2$-Bench against Claude Sonnet 4.5 (thinking), we find that within-family model pairs score 5.9 pp higher in AGS than cross-family pairs, and that Kimi-K2 (thinking) reaches 82.6\% $S_{\text{node}}$ and 94.7\% $S_{\text{dep}}$, exceeding Anthropic's own Opus 4.1. A controlled distillation experiment further confirms that AGS distinguishes teacher-specific convergence from general improvement. RPS and AGS capture distinct behavioral dimensions (Pearson $r$ = 0.491), providing complementary diagnostic signals for behavioral convergence in the agent ecosystem. Our code is available at https://github.com/Syuchin/AgentEcho.
WorldTravel: A Realistic Multimodal Travel-Planning Benchmark with Tightly Coupled Constraints
Feb 09, 2026Real-world autonomous planning requires coordinating tightly coupled constraints where a single decision dictates the feasibility of all subsequent actions. However, existing benchmarks predominantly feature loosely coupled constraints solvable through local greedy decisions and rely on idealized data, failing to capture the complexity of extracting parameters from dynamic web environments. We introduce \textbf{WorldTravel}, a benchmark comprising 150 real-world travel scenarios across 5 cities that demand navigating an average of 15+ interdependent temporal and logical constraints. To evaluate agents in realistic deployments, we develop \textbf{WorldTravel-Webscape}, a multi-modal environment featuring over 2,000 rendered webpages where agents must perceive constraint parameters directly from visual layouts to inform their planning. Our evaluation of 10 frontier models reveals a significant performance collapse: even the state-of-the-art GPT-5.2 achieves only 32.67\% feasibility in text-only settings, which plummets to 19.33\% in multi-modal environments. We identify a critical Perception-Action Gap and a Planning Horizon threshold at approximately 10 constraints where model reasoning consistently fails, suggesting that perception and reasoning remain independent bottlenecks. These findings underscore the need for next-generation agents that unify high-fidelity visual perception with long-horizon reasoning to handle brittle real-world logistics.
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domains
Nov 14, 2025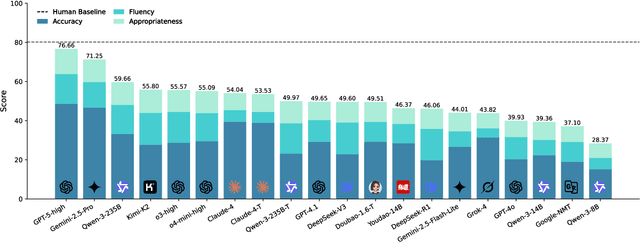

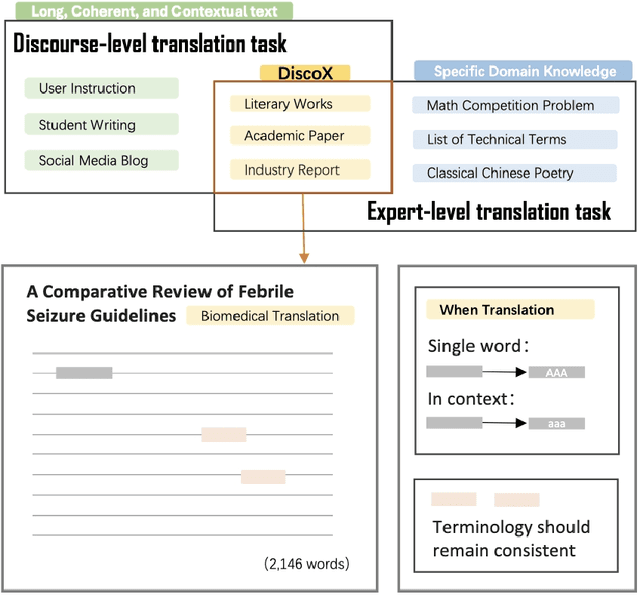

The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Nov 07, 2025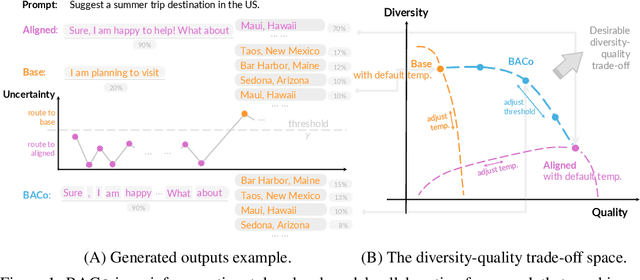
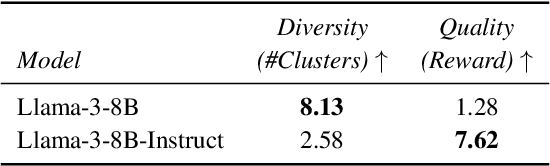
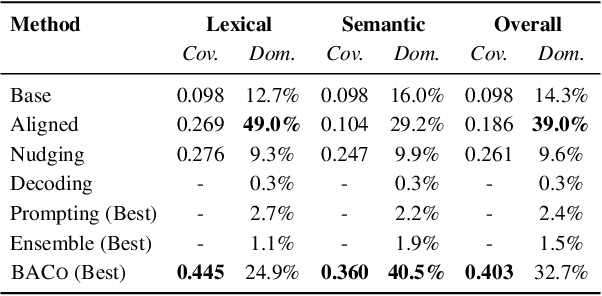
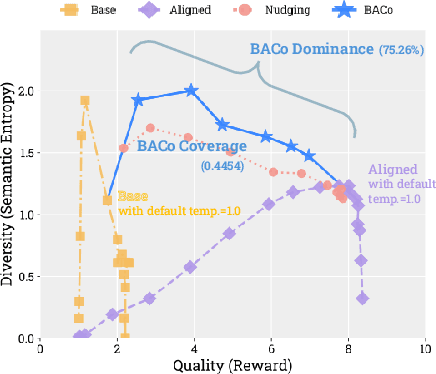
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs across generations. We propose Base-Aligned Model Collaboration (BACo), an inference-time token-level model collaboration framework that dynamically combines a base LLM with its aligned counterpart to optimize diversity and quality. Inspired by prior work (Fei et al., 2025), BACo employs routing strategies that determine, at each token, from which model to decode based on next-token prediction uncertainty and predicted contents' semantic role. Prior diversity-promoting methods, such as retraining, prompt engineering, and multi-sampling methods, improve diversity but often degrade quality or require costly decoding or post-training. In contrast, BACo achieves both high diversity and quality post hoc within a single pass, while offering strong controllability. We explore a family of routing strategies, across three open-ended generation tasks and 13 metrics covering diversity and quality, BACo consistently surpasses state-of-the-art inference-time baselines. With our best router, BACo achieves a 21.3% joint improvement in diversity and quality. Human evaluations also mirror these improvements. The results suggest that collaboration between base and aligned models can optimize and control diversity and quality.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
Tokenized Bandit for LLM Decoding and Alignment
Jun 08, 2025



We introduce the tokenized linear bandit (TLB) and multi-armed bandit (TMAB), variants of linear and stochastic multi-armed bandit problems inspired by LLM decoding and alignment. In these problems, at each round $t \in [T]$, a user submits a query (context), and the decision maker (DM) sequentially selects a token irrevocably from a token set. Once the sequence is complete, the DM observes a random utility from the user, whose expectation is presented by a sequence function mapping the chosen token sequence to a nonnegative real value that depends on the query. In both problems, we first show that learning is impossible without any structure on the sequence function. We introduce a natural assumption, diminishing distance with more commons (DDMC), and propose algorithms with regret $\tilde{O}(L\sqrt{T})$ and $\tilde{O}(L\sqrt{T^{2/3}})$ for TLB and TMAB, respectively. As a side product, we obtain an (almost) optimality of the greedy decoding for LLM decoding algorithm under DDMC, which justifies the unresaonable effectiveness of greedy decoding in several tasks. This also has an immediate application to decoding-time LLM alignment, when the misaligned utility can be represented as the frozen LLM's utility and a linearly realizable latent function. We finally validate our algorithm's performance empirically as well as verify our assumptions using synthetic and real-world datasets.
MARS-Bench: A Multi-turn Athletic Real-world Scenario Benchmark for Dialogue Evaluation
May 27, 2025Large Language Models (\textbf{LLMs}), e.g. ChatGPT, have been widely adopted in real-world dialogue applications. However, LLMs' robustness, especially in handling long complex dialogue sessions, including frequent motivation transfer, sophisticated cross-turn dependency, is criticized all along. Nevertheless, no existing benchmarks can fully reflect these weaknesses. We present \textbf{MARS-Bench}, a \textbf{M}ulti-turn \textbf{A}thletic \textbf{R}eal-world \textbf{S}cenario Dialogue \textbf{Bench}mark, designed to remedy the gap. MARS-Bench is constructed from play-by-play text commentary so to feature realistic dialogues specifically designed to evaluate three critical aspects of multi-turn conversations: Ultra Multi-turn, Interactive Multi-turn, and Cross-turn Tasks. Extensive experiments on MARS-Bench also reveal that closed-source LLMs significantly outperform open-source alternatives, explicit reasoning significantly boosts LLMs' robustness on handling long complex dialogue sessions, and LLMs indeed face significant challenges when handling motivation transfer and sophisticated cross-turn dependency. Moreover, we provide mechanistic interpretability on how attention sinks due to special tokens lead to LLMs' performance degradation when handling long complex dialogue sessions based on attention visualization experiment in Qwen2.5-7B-Instruction.