 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquipping Transformer with Random-Access Reading for Long-Context Understanding
Paper and Code
May 21, 2024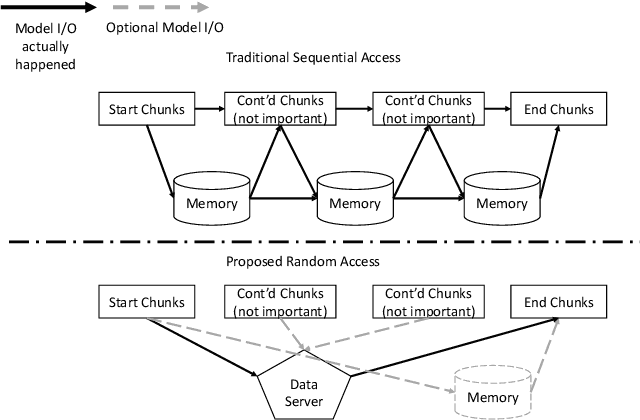

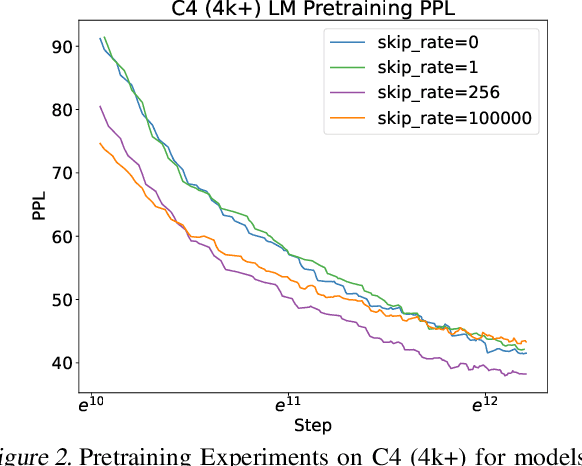
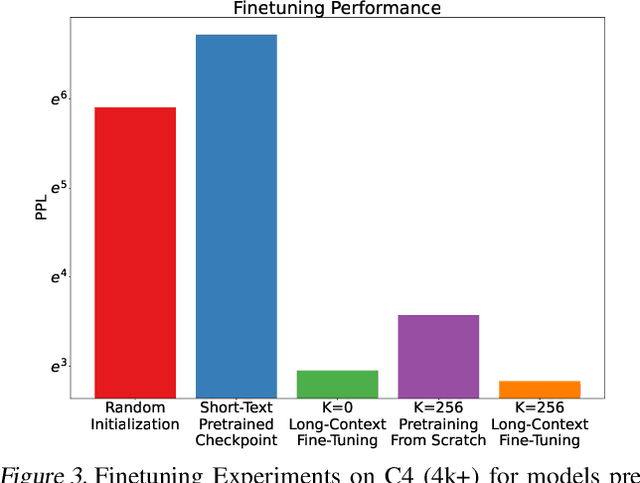
Long-context modeling presents a significant challenge for transformer-based large language models (LLMs) due to the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs. Existing methods address computational complexity through techniques such as text chunking, the kernel approach, and structured attention, and tackle length extrapolation problems through positional encoding, continued pretraining, and data engineering. These approaches typically require $\textbf{sequential access}$ to the document, necessitating reading from the first to the last token. We contend that for goal-oriented reading of long documents, such sequential access is not necessary, and a proficiently trained model can learn to omit hundreds of less pertinent tokens. Inspired by human reading behaviors and existing empirical observations, we propose $\textbf{random access}$, a novel reading strategy that enables transformers to efficiently process long documents without examining every token. Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of our method.