 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Improves Information Conveyance in Language Models
May 29, 2026Fine-tuning is often believed to reduce uncertainty and diversity in large language models, but existing analyses overlook output length, a key confounder, and therefore fail to capture how uncertainty is distributed across an entire generation rollout. To address this, we propose Canopy Entropy ($\mathrm{CE}^\star$), a measure that views language generation from a tree perspective, where ``canopy'' represents the space of all possible rollouts, making $\mathrm{CE}^\star$ naturally quantify the effective size of the generation space. $\mathrm{CE}^\star$ jointly captures uncertainty in both the output length $N$ and the generated sequence $Y_{1:N}$ -- indeed, we show that it equals to total Shannon entropy $H(N, Y_{1:N}\mid X)$, where $X$ denotes the prompt. This formulation yields interpretable metrics, including a length-entropy correlation term $ρ(N, r_N)$, where $r_N$ is the entropy rate, quantifying information conveyance efficiency by indicating whether longer outputs are more or less informative per token. Empirically, across tasks and model families, we find that fine-tuned models consistently exhibit stronger positive correlation $ρ(N, r_N)$, even when total entropy decreases. Furthermore, after controlling for model family, task, prompt, and output-length effects, we find that fine-tuning nearly triples the correlation strength between entropy rate and semantic diversity, suggesting that aligned models convert token uncertainty into semantic diversity more efficiently. Overall, these results demonstrate that fine-tuning does not simply reduce uncertainty, but fundamentally reorganizes it into more informative and semantically meaningful generations. Our code is available at https://github.com/WeiyiTian/canopy-entropy.
On Benchmark Hacking in ML Contests: Modeling, Insights and Design
Apr 24, 2026Benchmark hacking refers to tuning a machine learning model to score highly on certain evaluation criteria without improving true generalization or faithfully solving the intended problem. We study this phenomenon in a generic machine learning contest, where each contestant chooses two types of effort: creative effort that improves model capability as desired by the contest host, and mechanistic effort that only improves the model's fitness to the particular task in contest without contributing to true generalization. We establish the existence of a symmetric monotone pure strategy equilibrium in this competition game. It also provides a natural definition of benchmark hacking in this strategic context by comparing a player's equilibrium effort allocation to that of a single-agent baseline scenario. Under our definition, contestants with types below certain threshold (low types) always engage in benchmark hacking, whereas those above the threshold do not. Furthermore, we show that more skewed reward structures (favoring top-ranked contestants) can elicit more desirable contest outcomes. We also provide empirical evidence to support our theoretical predictions.
Do AI Overviews Benefit Search Engines? An Ecosystem Perspective
Jan 30, 2026The integration of AI Overviews into search engines enhances user experience but diverts traffic from content creators, potentially discouraging high-quality content creation and causing user attrition that undermines long-term search engine profit. To address this issue, we propose a game-theoretic model of creator competition with costly effort, characterize equilibrium behavior, and design two incentive mechanisms: a citation mechanism that references sources within an AI Overview, and a compensation mechanism that offers monetary rewards to creators. For both cases, we provide structural insights and near-optimal profit-maximizing mechanisms. Evaluations on real click data show that although AI Overviews harm long-term search engine profit, interventions based on our proposed mechanisms can increase long-term profit across a range of realistic scenarios, pointing toward a more sustainable trajectory for AI-enhanced search ecosystems.
Beyond Majority Voting: LLM Aggregation by Leveraging Higher-Order Information
Oct 01, 2025With the rapid progress of multi-agent large language model (LLM) reasoning, how to effectively aggregate answers from multiple LLMs has emerged as a fundamental challenge. Standard majority voting treats all answers equally, failing to consider latent heterogeneity and correlation across models. In this work, we design two new aggregation algorithms called Optimal Weight (OW) and Inverse Surprising Popularity (ISP), leveraging both first-order and second-order information. Our theoretical analysis shows these methods provably mitigate inherent limitations of majority voting under mild assumptions, leading to more reliable collective decisions. We empirically validate our algorithms on synthetic datasets, popular LLM fine-tuning benchmarks such as UltraFeedback and MMLU, and a real-world healthcare setting ARMMAN. Across all cases, our methods consistently outperform majority voting, offering both practical performance gains and conceptual insights for the design of robust multi-agent LLM pipelines.
Strategic Filtering for Content Moderation: Free Speech or Free of Distortion?
Jul 26, 2025User-generated content (UGC) on social media platforms is vulnerable to incitements and manipulations, necessitating effective regulations. To address these challenges, those platforms often deploy automated content moderators tasked with evaluating the harmfulness of UGC and filtering out content that violates established guidelines. However, such moderation inevitably gives rise to strategic responses from users, who strive to express themselves within the confines of guidelines. Such phenomena call for a careful balance between: 1. ensuring freedom of speech -- by minimizing the restriction of expression; and 2. reducing social distortion -- measured by the total amount of content manipulation. We tackle the problem of optimizing this balance through the lens of mechanism design, aiming at optimizing the trade-off between minimizing social distortion and maximizing free speech. Although determining the optimal trade-off is NP-hard, we propose practical methods to approximate the optimal solution. Additionally, we provide generalization guarantees determining the amount of finite offline data required to approximate the optimal moderator effectively.
Tokenized Bandit for LLM Decoding and Alignment
Jun 08, 2025



We introduce the tokenized linear bandit (TLB) and multi-armed bandit (TMAB), variants of linear and stochastic multi-armed bandit problems inspired by LLM decoding and alignment. In these problems, at each round $t \in [T]$, a user submits a query (context), and the decision maker (DM) sequentially selects a token irrevocably from a token set. Once the sequence is complete, the DM observes a random utility from the user, whose expectation is presented by a sequence function mapping the chosen token sequence to a nonnegative real value that depends on the query. In both problems, we first show that learning is impossible without any structure on the sequence function. We introduce a natural assumption, diminishing distance with more commons (DDMC), and propose algorithms with regret $\tilde{O}(L\sqrt{T})$ and $\tilde{O}(L\sqrt{T^{2/3}})$ for TLB and TMAB, respectively. As a side product, we obtain an (almost) optimality of the greedy decoding for LLM decoding algorithm under DDMC, which justifies the unresaonable effectiveness of greedy decoding in several tasks. This also has an immediate application to decoding-time LLM alignment, when the misaligned utility can be represented as the frozen LLM's utility and a linearly realizable latent function. We finally validate our algorithm's performance empirically as well as verify our assumptions using synthetic and real-world datasets.
Cer-Eval: Certifiable and Cost-Efficient Evaluation Framework for LLMs
May 02, 2025As foundation models continue to scale, the size of trained models grows exponentially, presenting significant challenges for their evaluation. Current evaluation practices involve curating increasingly large datasets to assess the performance of large language models (LLMs). However, there is a lack of systematic analysis and guidance on determining the sufficiency of test data or selecting informative samples for evaluation. This paper introduces a certifiable and cost-efficient evaluation framework for LLMs. Our framework adapts to different evaluation objectives and outputs confidence intervals that contain true values with high probability. We use ``test sample complexity'' to quantify the number of test points needed for a certifiable evaluation and derive tight bounds on test sample complexity. Based on the developed theory, we develop a partition-based algorithm, named Cer-Eval, that adaptively selects test points to minimize the cost of LLM evaluation. Real-world experiments demonstrate that Cer-Eval can save 20% to 40% test points across various benchmarks, while maintaining an estimation error level comparable to the current evaluation process and providing a 95% confidence guarantee.
Grounded Persuasive Language Generation for Automated Marketing
Feb 24, 2025



This paper develops an agentic framework that employs large language models (LLMs) to automate the generation of persuasive and grounded marketing content, using real estate listing descriptions as our focal application domain. Our method is designed to align the generated content with user preferences while highlighting useful factual attributes. This agent consists of three key modules: (1) Grounding Module, mimicking expert human behavior to predict marketable features; (2) Personalization Module, aligning content with user preferences; (3) Marketing Module, ensuring factual accuracy and the inclusion of localized features. We conduct systematic human-subject experiments in the domain of real estate marketing, with a focus group of potential house buyers. The results demonstrate that marketing descriptions generated by our approach are preferred over those written by human experts by a clear margin. Our findings suggest a promising LLM-based agentic framework to automate large-scale targeted marketing while ensuring responsible generation using only facts.
Machine Learning Should Maximize Welfare, Not (Only) Accuracy
Feb 17, 2025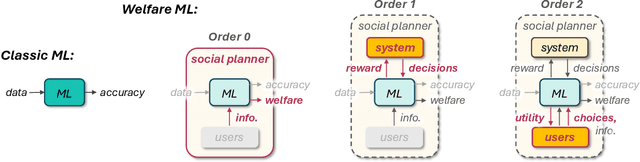
Decades of research in machine learning have given us powerful tools for making accurate predictions. But when used in social settings and on human inputs, better accuracy does not immediately translate to better social outcomes. This may not be surprising given that conventional learning frameworks are not designed to express societal preferences -- let alone promote them. This position paper argues that machine learning is currently missing, and can gain much from incorporating, a proper notion of social welfare. The field of welfare economics asks: how should we allocate limited resources to self-interested agents in a way that maximizes social benefit? We argue that this perspective applies to many modern applications of machine learning in social contexts, and advocate for its adoption. Rather than disposing of prediction, we aim to leverage this forte of machine learning for promoting social welfare. We demonstrate this idea by proposing a conceptual framework that gradually transitions from accuracy maximization (with awareness to welfare) to welfare maximization (via accurate prediction). We detail applications and use-cases for which our framework can be effective, identify technical challenges and practical opportunities, and highlight future avenues worth pursuing.
On Sequential Fault-Intolerant Process Planning
Feb 07, 2025We propose and study a planning problem we call Sequential Fault-Intolerant Process Planning (SFIPP). SFIPP captures a reward structure common in many sequential multi-stage decision problems where the planning is deemed successful only if all stages succeed. Such reward structures are different from classic additive reward structures and arise in important applications such as drug/material discovery, security, and quality-critical product design. We design provably tight online algorithms for settings in which we need to pick between different actions with unknown success chances at each stage. We do so both for the foundational case in which the behavior of actions is deterministic, and the case of probabilistic action outcomes, where we effectively balance exploration for learning and exploitation for planning through the usage of multi-armed bandit algorithms. In our empirical evaluations, we demonstrate that the specialized algorithms we develop, which leverage additional information about the structure of the SFIPP instance, outperform our more general algorithm.