 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Overviews Benefit Search Engines? An Ecosystem Perspective
Jan 30, 2026The integration of AI Overviews into search engines enhances user experience but diverts traffic from content creators, potentially discouraging high-quality content creation and causing user attrition that undermines long-term search engine profit. To address this issue, we propose a game-theoretic model of creator competition with costly effort, characterize equilibrium behavior, and design two incentive mechanisms: a citation mechanism that references sources within an AI Overview, and a compensation mechanism that offers monetary rewards to creators. For both cases, we provide structural insights and near-optimal profit-maximizing mechanisms. Evaluations on real click data show that although AI Overviews harm long-term search engine profit, interventions based on our proposed mechanisms can increase long-term profit across a range of realistic scenarios, pointing toward a more sustainable trajectory for AI-enhanced search ecosystems.
Reliable and Private Utility Signaling for Data Markets
Nov 11, 2025The explosive growth of data has highlighted its critical role in driving economic growth through data marketplaces, which enable extensive data sharing and access to high-quality datasets. To support effective trading, signaling mechanisms provide participants with information about data products before transactions, enabling informed decisions and facilitating trading. However, due to the inherent free-duplication nature of data, commonly practiced signaling methods face a dilemma between privacy and reliability, undermining the effectiveness of signals in guiding decision-making. To address this, this paper explores the benefits and develops a non-TCP-based construction for a desirable signaling mechanism that simultaneously ensures privacy and reliability. We begin by formally defining the desirable utility signaling mechanism and proving its ability to prevent suboptimal decisions for both participants and facilitate informed data trading. To design a protocol to realize its functionality, we propose leveraging maliciously secure multi-party computation (MPC) to ensure the privacy and robustness of signal computation and introduce an MPC-based hash verification scheme to ensure input reliability. In multi-seller scenarios requiring fair data valuation, we further explore the design and optimization of the MPC-based KNN-Shapley method with improved efficiency. Rigorous experiments demonstrate the efficiency and practicality of our approach.
CoKV: Optimizing KV Cache Allocation via Cooperative Game
Feb 21, 2025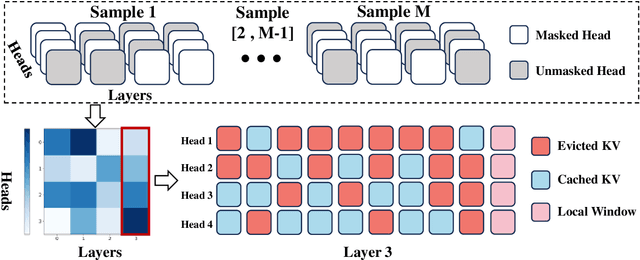
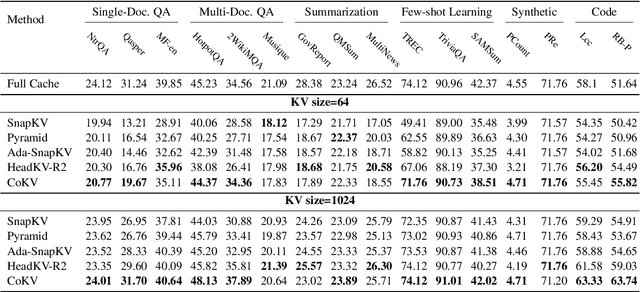
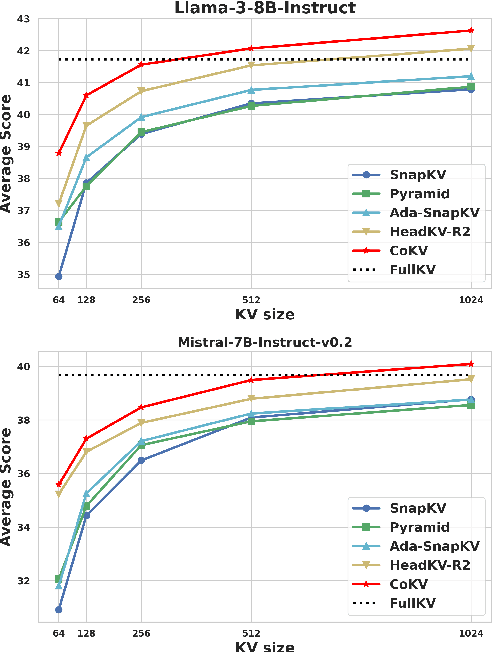

Large language models (LLMs) have achieved remarkable success on various aspects of human life. However, one of the major challenges in deploying these models is the substantial memory consumption required to store key-value pairs (KV), which imposes significant resource demands. Recent research has focused on KV cache budget allocation, with several approaches proposing head-level budget distribution by evaluating the importance of individual attention heads. These methods, however, assess the importance of heads independently, overlooking their cooperative contributions within the model, which may result in a deviation from their true impact on model performance. In light of this limitation, we propose CoKV, a novel method that models the cooperation between heads in model inference as a cooperative game. By evaluating the contribution of each head within the cooperative game, CoKV can allocate the cache budget more effectively. Extensive experiments show that CoKV achieves state-of-the-art performance on the LongBench benchmark using LLama-3-8B-Instruct and Mistral-7B models.
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
TabularMark: Watermarking Tabular Datasets for Machine Learning
Jun 21, 2024
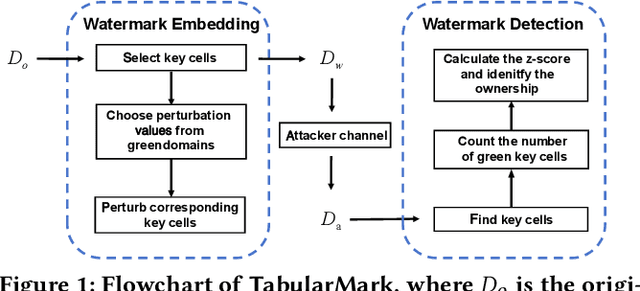
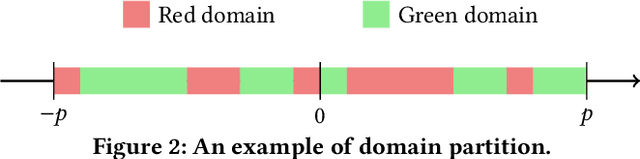
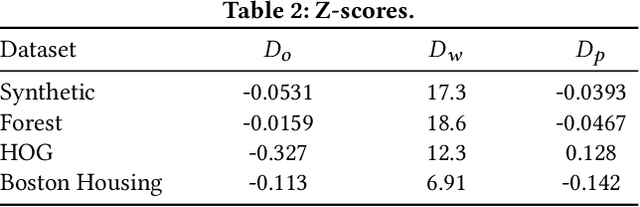
Watermarking is broadly utilized to protect ownership of shared data while preserving data utility. However, existing watermarking methods for tabular datasets fall short on the desired properties (detectability, non-intrusiveness, and robustness) and only preserve data utility from the perspective of data statistics, ignoring the performance of downstream ML models trained on the datasets. Can we watermark tabular datasets without significantly compromising their utility for training ML models while preventing attackers from training usable ML models on attacked datasets? In this paper, we propose a hypothesis testing-based watermarking scheme, TabularMark. Data noise partitioning is utilized for data perturbation during embedding, which is adaptable for numerical and categorical attributes while preserving the data utility. For detection, a custom-threshold one proportion z-test is employed, which can reliably determine the presence of the watermark. Experiments on real-world and synthetic datasets demonstrate the superiority of TabularMark in detectability, non-intrusiveness, and robustness.
Cross-silo Federated Learning with Record-level Personalized Differential Privacy
Jan 30, 2024Federated learning enhanced by differential privacy has emerged as a popular approach to better safeguard the privacy of client-side data by protecting clients' contributions during the training process. Existing solutions typically assume a uniform privacy budget for all records and provide one-size-fits-all solutions that may not be adequate to meet each record's privacy requirement. In this paper, we explore the uncharted territory of cross-silo FL with record-level personalized differential privacy. We devise a novel framework named rPDP-FL, employing a two-stage hybrid sampling scheme with both client-level sampling and non-uniform record-level sampling to accommodate varying privacy requirements. A critical and non-trivial problem is to select the ideal per-record sampling probability q given the personalized privacy budget {\epsilon}. We introduce a versatile solution named Simulation-CurveFitting, allowing us to uncover a significant insight into the nonlinear correlation between q and {\epsilon} and derive an elegant mathematical model to tackle the problem. Our evaluation demonstrates that our solution can provide significant performance gains over the baselines that do not consider personalized privacy preservation.
Prompt Valuation Based on Shapley Values
Dec 24, 2023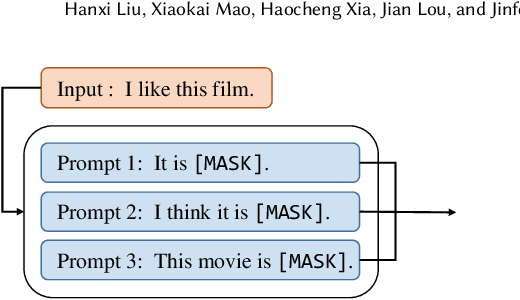
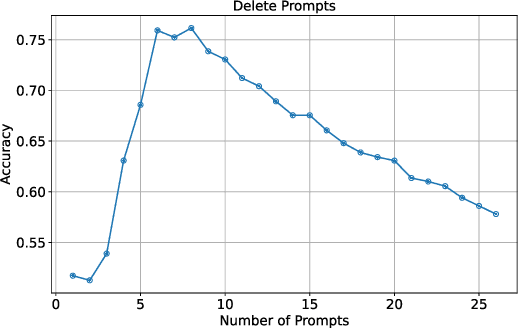
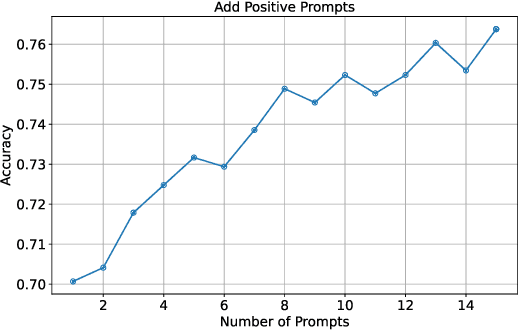
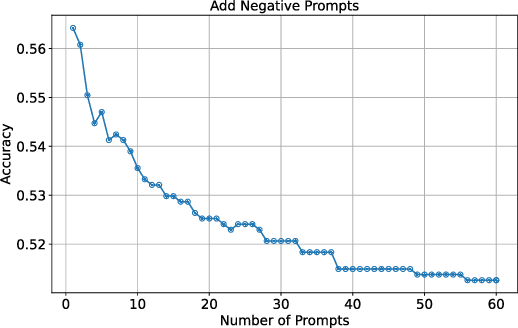
Large language models (LLMs) excel on new tasks without additional training, simply by providing natural language prompts that demonstrate how the task should be performed. Prompt ensemble methods comprehensively harness the knowledge of LLMs while mitigating individual biases and errors and further enhancing performance. However, more prompts do not necessarily lead to better results, and not all prompts are beneficial. A small number of high-quality prompts often outperform many low-quality prompts. Currently, there is a lack of a suitable method for evaluating the impact of prompts on the results. In this paper, we utilize the Shapley value to fairly quantify the contributions of prompts, helping to identify beneficial or detrimental prompts, and potentially guiding prompt valuation in data markets. Through extensive experiments employing various ensemble methods and utility functions on diverse tasks, we validate the effectiveness of using the Shapley value method for prompts as it effectively distinguishes and quantifies the contributions of each prompt.
Shapley Value on Probabilistic Classifiers
Jun 12, 2023



Data valuation has become an increasingly significant discipline in data science due to the economic value of data. In the context of machine learning (ML), data valuation methods aim to equitably measure the contribution of each data point to the utility of an ML model. One prevalent method is Shapley value, which helps identify data points that are beneficial or detrimental to an ML model. However, traditional Shapley-based data valuation methods may not effectively distinguish between beneficial and detrimental training data points for probabilistic classifiers. In this paper, we propose Probabilistic Shapley (P-Shapley) value by constructing a probability-wise utility function that leverages the predicted class probabilities of probabilistic classifiers rather than binarized prediction results in the traditional Shapley value. We also offer several activation functions for confidence calibration to effectively quantify the marginal contribution of each data point to the probabilistic classifiers. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposed P-Shapley value in evaluating the importance of data for building a high-usability and trustworthy ML model.
Quantifying and Defending against Privacy Threats on Federated Knowledge Graph Embedding
Apr 06, 2023



Knowledge Graph Embedding (KGE) is a fundamental technique that extracts expressive representation from knowledge graph (KG) to facilitate diverse downstream tasks. The emerging federated KGE (FKGE) collaboratively trains from distributed KGs held among clients while avoiding exchanging clients' sensitive raw KGs, which can still suffer from privacy threats as evidenced in other federated model trainings (e.g., neural networks). However, quantifying and defending against such privacy threats remain unexplored for FKGE which possesses unique properties not shared by previously studied models. In this paper, we conduct the first holistic study of the privacy threat on FKGE from both attack and defense perspectives. For the attack, we quantify the privacy threat by proposing three new inference attacks, which reveal substantial privacy risk by successfully inferring the existence of the KG triple from victim clients. For the defense, we propose DP-Flames, a novel differentially private FKGE with private selection, which offers a better privacy-utility tradeoff by exploiting the entity-binding sparse gradient property of FKGE and comes with a tight privacy accountant by incorporating the state-of-the-art private selection technique. We further propose an adaptive privacy budget allocation policy to dynamically adjust defense magnitude across the training procedure. Comprehensive evaluations demonstrate that the proposed defense can successfully mitigate the privacy threat by effectively reducing the success rate of inference attacks from $83.1\%$ to $59.4\%$ on average with only a modest utility decrease.
Absolute Shapley Value
Mar 23, 2020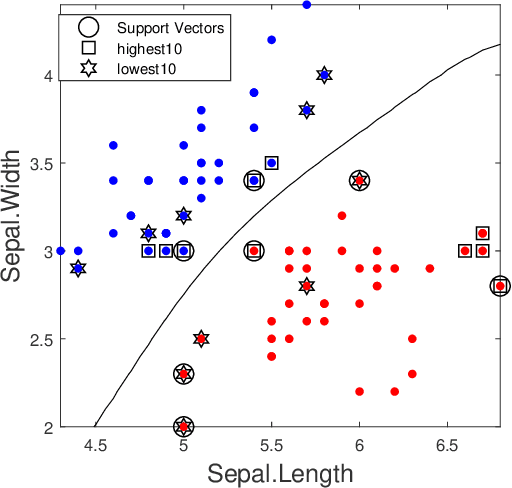
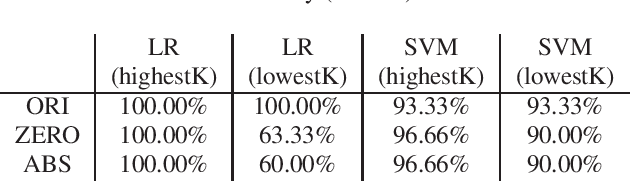
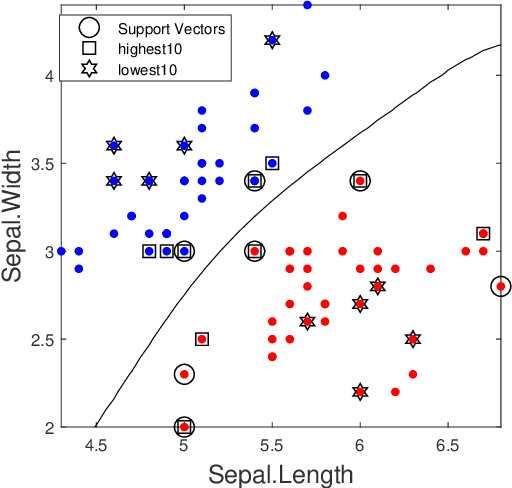
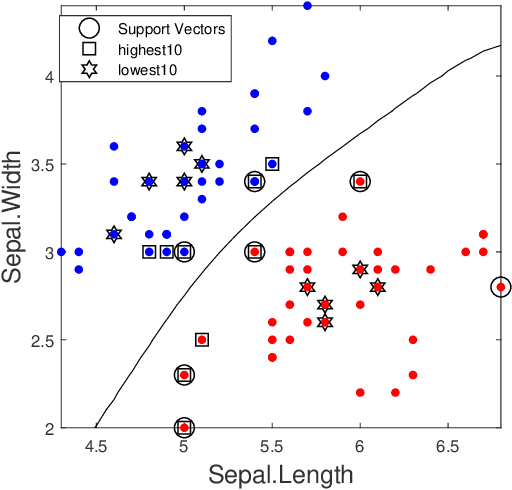
Shapley value is a concept in cooperative game theory for measuring the contribution of each participant, which was named in honor of Lloyd Shapley. Shapley value has been recently applied in data marketplaces for compensation allocation based on their contribution to the models. Shapley value is the only value division scheme used for compensation allocation that meets three desirable criteria: group rationality, fairness, and additivity. In cooperative game theory, the marginal contribution of each contributor to each coalition is a nonnegative value. However, in machine learning model training, the marginal contribution of each contributor (data tuple) to each coalition (a set of data tuples) can be a negative value, i.e., the accuracy of the model trained by a dataset with an additional data tuple can be lower than the accuracy of the model trained by the dataset only. In this paper, we investigate the problem of how to handle the negative marginal contribution when computing Shapley value. We explore three philosophies: 1) taking the original value (Original Shapley Value); 2) taking the larger of the original value and zero (Zero Shapley Value); and 3) taking the absolute value of the original value (Absolute Shapley Value). Experiments on Iris dataset demonstrate that the definition of Absolute Shapley Value significantly outperforms the other two definitions in terms of evaluating data importance (the contribution of each data tuple to the trained model).