 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive and Explicit safe: Triggering Latent Safety Awareness in Large Reasoning Models
Jun 15, 2026While Large Reasoning Models (LRMs) excel at complex tasks, they remain highly vulnerable to sophisticated jailbreaks and direct harmful queries. To address this vulnerability, prior works depend heavily on external manual data annotation for safety alignment. However, we observe that LRMs can inherently identify safety risks when being re-presented with original queries alongside their own reasoning trajectories -- a capability we term Latent Safety Awareness. To leverage this safety awareness, we first employ Supervised Fine-Tuning (SFT) to explicitly induce safe tags to trigger safety analysis and guidance following the initial reasoning content for unsafe queries, while preserving standard responses for general queries to ensure adaptive triggering. Subsequently, we apply Direct Preference Optimization (DPO) to further enhance the correctness and stability of the safety analysis and guidance. Notably, responses required for both training stages are entirely generated by models being optimized. With (Safe Trigger) SFT and DPO, experimental results demonstrate significant safety enhancement. For example, the Attack Success Rate (ASR) of DeepSeek-R1-Distill-Llama-8B, on average, drops 24.65% and 36.72% on harmful and jailbreak benchmarks, respectively. Finally, our Safe Trigger method exerts almost no negative impact on general performance or user experience.
Aligned but Fragile: Enhancing LLM Safety Robustness via Zeroth-Order Optimization
May 28, 2026Safety alignment for large language models (LLMs) aims to reduce harmful or unsafe behavior while preserving general utility. However, recent findings reveal that alignment effects can be fragile: lightweight post-alignment manipulations, such as parameter noise, activation noise, or quantization, can easily weaken the intended safety behavior. Prior efforts to improve robustness have primarily focused on data curation, modified alignment objectives, and safety-critical parameter identification, leaving the role of the optimizer itself largely unexplored. In this paper, we are the first to study the robustness of safety alignment from the perspective of the base optimizer. This optimizer-centric view naturally points to zeroth-order optimization, which provides a robustness-oriented signal by evaluating safety alignment under perturbations. Based on this insight, we propose a hybrid framework that first performs standard first-order safety alignment and then applies zeroth-order refinement to improve robustness. Both theoretically and empirically, we show that only a few zeroth-order refinement steps can enhance robustness while preserving safety alignment. We further improve the efficiency of zeroth-order refinement by exploiting its inherent perturbation-based evaluations to estimate layer-wise robustness sensitivity, enabling the refinement process to concentrate updates on robustness-critical layers with modest training overhead.
Module-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.
Quantifying and Defending against Privacy Threats on Federated Knowledge Graph Embedding
Apr 06, 2023



Knowledge Graph Embedding (KGE) is a fundamental technique that extracts expressive representation from knowledge graph (KG) to facilitate diverse downstream tasks. The emerging federated KGE (FKGE) collaboratively trains from distributed KGs held among clients while avoiding exchanging clients' sensitive raw KGs, which can still suffer from privacy threats as evidenced in other federated model trainings (e.g., neural networks). However, quantifying and defending against such privacy threats remain unexplored for FKGE which possesses unique properties not shared by previously studied models. In this paper, we conduct the first holistic study of the privacy threat on FKGE from both attack and defense perspectives. For the attack, we quantify the privacy threat by proposing three new inference attacks, which reveal substantial privacy risk by successfully inferring the existence of the KG triple from victim clients. For the defense, we propose DP-Flames, a novel differentially private FKGE with private selection, which offers a better privacy-utility tradeoff by exploiting the entity-binding sparse gradient property of FKGE and comes with a tight privacy accountant by incorporating the state-of-the-art private selection technique. We further propose an adaptive privacy budget allocation policy to dynamically adjust defense magnitude across the training procedure. Comprehensive evaluations demonstrate that the proposed defense can successfully mitigate the privacy threat by effectively reducing the success rate of inference attacks from $83.1\%$ to $59.4\%$ on average with only a modest utility decrease.
OpBoost: A Vertical Federated Tree Boosting Framework Based on Order-Preserving Desensitization
Oct 04, 2022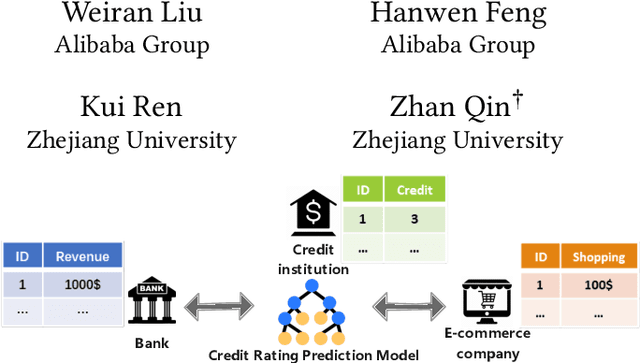
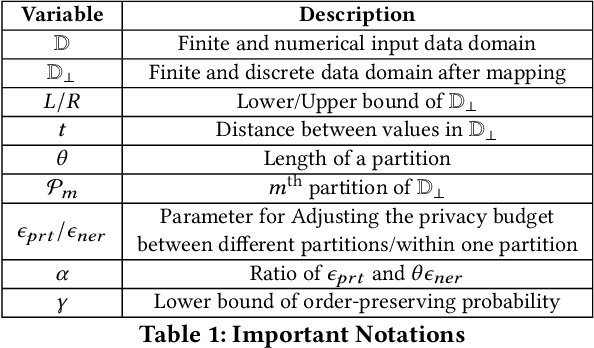
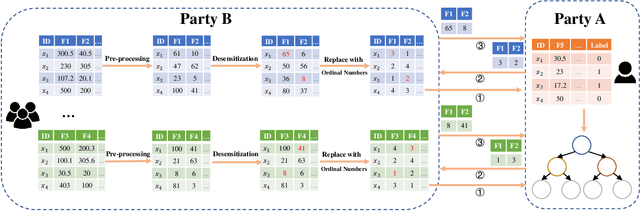
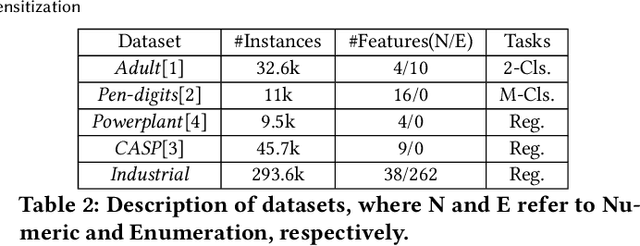
Vertical Federated Learning (FL) is a new paradigm that enables users with non-overlapping attributes of the same data samples to jointly train a model without directly sharing the raw data. Nevertheless, recent works show that it's still not sufficient to prevent privacy leakage from the training process or the trained model. This paper focuses on studying the privacy-preserving tree boosting algorithms under the vertical FL. The existing solutions based on cryptography involve heavy computation and communication overhead and are vulnerable to inference attacks. Although the solution based on Local Differential Privacy (LDP) addresses the above problems, it leads to the low accuracy of the trained model. This paper explores to improve the accuracy of the widely deployed tree boosting algorithms satisfying differential privacy under vertical FL. Specifically, we introduce a framework called OpBoost. Three order-preserving desensitization algorithms satisfying a variant of LDP called distance-based LDP (dLDP) are designed to desensitize the training data. In particular, we optimize the dLDP definition and study efficient sampling distributions to further improve the accuracy and efficiency of the proposed algorithms. The proposed algorithms provide a trade-off between the privacy of pairs with large distance and the utility of desensitized values. Comprehensive evaluations show that OpBoost has a better performance on prediction accuracy of trained models compared with existing LDP approaches on reasonable settings. Our code is open source.