 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDE-Driven Spatio-Temporal Hypergraph Neural Networks for Irregular Longitudinal fMRI Connectome Modeling in Alzheimer's Disease
Mar 20, 2026Longitudinal neuroimaging is essential for modeling disease progression in Alzheimer's disease (AD), yet irregular sampling and missing visits pose substantial challenges for learning reliable temporal representations. To address this challenge, we propose SDE-HGNN, a stochastic differential equation (SDE)-driven spatio-temporal hypergraph neural network for irregular longitudinal fMRI connectome modeling. The framework first employs an SDE-based reconstruction module to recover continuous latent trajectories from irregular observations. Based on these reconstructed representations, dynamic hypergraphs are constructed to capture higher-order interactions among brain regions over time. To further model temporal evolution, hypergraph convolution parameters evolve through SDE-controlled recurrent dynamics conditioned on inter-scan intervals, enabling disease-stage-adaptive connectivity modeling. We also incorporate a sparsity-based importance learning mechanism to identify salient brain regions and discriminative connectivity patterns. Extensive experiments on the OASIS-3 and ADNI cohorts demonstrate consistent improvements over state-of-the-art graph and hypergraph baselines in AD progression prediction. The source code is available at https://anonymous.4open.science/r/SDE-HGNN-017F.
OmniClone: Engineering a Robust, All-Rounder Whole-Body Humanoid Teleoperation System
Mar 15, 2026Whole-body humanoid teleoperation enables humans to remotely control humanoid robots, serving as both a real-time operational tool and a scalable engine for collecting demonstrations for autonomous learning. Despite recent advances, existing systems are validated using aggregate metrics that conflate distinct motion regimes, masking critical failure modes. This lack of diagnostic granularity, compounded by tightly coupled and labor-intensive system configurations, hinders robust real-world deployment. A key open challenge is building a teleoperation system that is simultaneously robust, versatile, and affordable for practical use. Here we present OmniClone, a whole-body humanoid teleoperation system that achieves high-fidelity, multi-skill control on a single consumer GPU with modest data requirements. Central to our approach is OmniBench, a diagnostic benchmark that evaluates policies across stratified motion categories and difficulty levels on unseen motions, exposing the narrow specialization of prior systems. Guided by these diagnostics, we identify an optimized training data recipe and integrate system-level improvements: subject-agnostic retargeting and robust communication, that collectively reduce Mean Per-Joint Position Error (MPJPE) by over 66% while requiring orders-of-magnitude fewer computational resources than comparable methods. Crucially, OmniClone is control-source-agnostic: a single unified policy supports real-time teleoperation, generated motion playback, and Vision-Language-Action (VLA) models, while generalizing across operators of vastly different body proportions. By uniting diagnostic evaluation with practical engineering, OmniClone provides an accessible foundation for scalable humanoid teleoperation and autonomous learning.
Joint Imaging-ROI Representation Learning via Cross-View Contrastive Alignment for Brain Disorder Classification
Mar 10, 2026Brain imaging classification is commonly approached from two perspectives: modeling the full image volume to capture global anatomical context, or constructing ROI-based graphs to encode localized and topological interactions. Although both representations have demonstrated independent efficacy, their relative contributions and potential complementarity remain insufficiently understood. Existing fusion approaches are typically task-specific and do not enable controlled evaluation of each representation under consistent training settings. To address this gap, we propose a unified cross-view contrastive framework for joint imaging-ROI representation learning. Our method learns subject-level global (imaging) and local (ROI-graph) embeddings and aligns them in a shared latent space using a bidirectional contrastive objective, encouraging representations from the same subject to converge while separating those from different subjects. This alignment produces comparable embeddings suitable for downstream fusion and enables systematic evaluation of imaging-only, ROI-only, and joint configurations within a unified training protocol. Extensive experiments on the ADHD-200 and ABIDE datasets demonstrate that joint learning consistently improves classification performance over either branch alone across multiple backbone choices. Moreover, interpretability analyses reveal that imaging-based and ROI-based branches emphasize distinct yet complementary discriminative patterns, explaining the observed performance gains. These findings provide principled evidence that explicitly integrating global volumetric and ROI-level representations is a promising direction for neuroimaging-based brain disorder classification. The source code is available at https://anonymous.4open.science/r/imaging-roi-contrastive-152C/.
Abstraction Generation for Generalized Planning with Pretrained Large Language Models
Feb 11, 2026Qualitative Numerical Planning (QNP) serves as an important abstraction model for generalized planning (GP), which aims to compute general plans that solve multiple instances at once. Recent works show that large language models (LLMs) can function as generalized planners. This work investigates whether LLMs can serve as QNP abstraction generators for GP problems and how to fix abstractions via automated debugging. We propose a prompt protocol: input a GP domain and training tasks to LLMs, prompting them to generate abstract features and further abstract the initial state, action set, and goal into QNP problems. An automated debugging method is designed to detect abstraction errors, guiding LLMs to fix abstractions. Experiments demonstrate that under properly guided by automated debugging, some LLMs can generate useful QNP abstractions.
SelfieAvatar: Real-time Head Avatar reenactment from a Selfie Video
Jan 26, 2026Head avatar reenactment focuses on creating animatable personal avatars from monocular videos, serving as a foundational element for applications like social signal understanding, gaming, human-machine interaction, and computer vision. Recent advances in 3D Morphable Model (3DMM)-based facial reconstruction methods have achieved remarkable high-fidelity face estimation. However, on the one hand, they struggle to capture the entire head, including non-facial regions and background details in real time, which is an essential aspect for producing realistic, high-fidelity head avatars. On the other hand, recent approaches leveraging generative adversarial networks (GANs) for head avatar generation from videos can achieve high-quality reenactments but encounter limitations in reproducing fine-grained head details, such as wrinkles and hair textures. In addition, existing methods generally rely on a large amount of training data, and rarely focus on using only a simple selfie video to achieve avatar reenactment. To address these challenges, this study introduces a method for detailed head avatar reenactment using a selfie video. The approach combines 3DMMs with a StyleGAN-based generator. A detailed reconstruction model is proposed, incorporating mixed loss functions for foreground reconstruction and avatar image generation during adversarial training to recover high-frequency details. Qualitative and quantitative evaluations on self-reenactment and cross-reenactment tasks demonstrate that the proposed method achieves superior head avatar reconstruction with rich and intricate textures compared to existing approaches.
Human Motion Estimation with Everyday Wearables
Dec 24, 2025While on-body device-based human motion estimation is crucial for applications such as XR interaction, existing methods often suffer from poor wearability, expensive hardware, and cumbersome calibration, which hinder their adoption in daily life. To address these challenges, we present EveryWear, a lightweight and practical human motion capture approach based entirely on everyday wearables: a smartphone, smartwatch, earbuds, and smart glasses equipped with one forward-facing and two downward-facing cameras, requiring no explicit calibration before use. We introduce Ego-Elec, a 9-hour real-world dataset covering 56 daily activities across 17 diverse indoor and outdoor environments, with ground-truth 3D annotations provided by the motion capture (MoCap), to facilitate robust research and benchmarking in this direction. Our approach employs a multimodal teacher-student framework that integrates visual cues from egocentric cameras with inertial signals from consumer devices. By training directly on real-world data rather than synthetic data, our model effectively eliminates the sim-to-real gap that constrains prior work. Experiments demonstrate that our method outperforms baseline models, validating its effectiveness for practical full-body motion estimation.
RadarMP: Motion Perception for 4D mmWave Radar in Autonomous Driving
Nov 15, 2025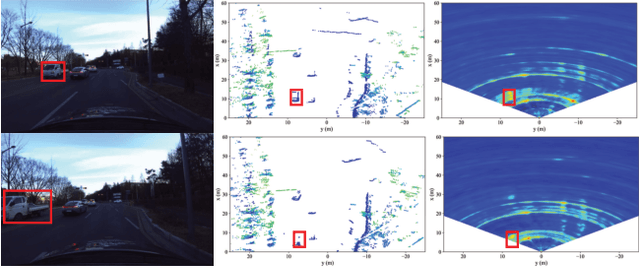
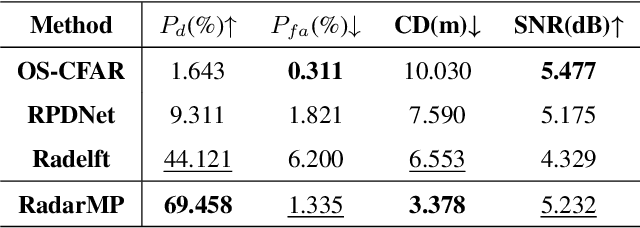
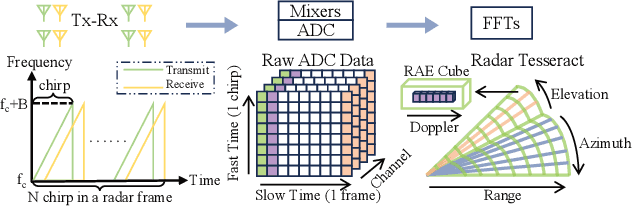
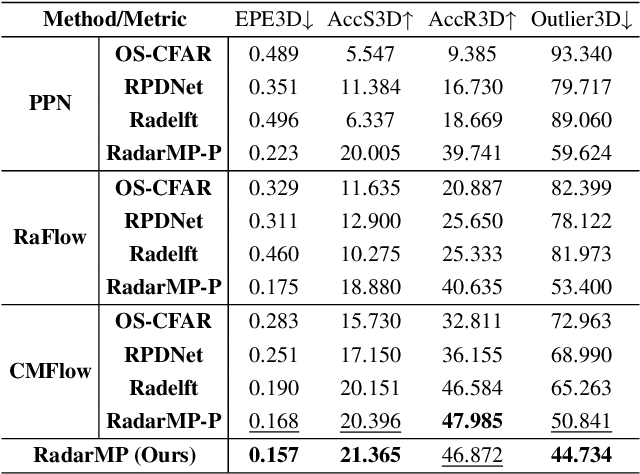
Accurate 3D scene motion perception significantly enhances the safety and reliability of an autonomous driving system. Benefiting from its all-weather operational capability and unique perceptual properties, 4D mmWave radar has emerged as an essential component in advanced autonomous driving. However, sparse and noisy radar points often lead to imprecise motion perception, leaving autonomous vehicles with limited sensing capabilities when optical sensors degrade under adverse weather conditions. In this paper, we propose RadarMP, a novel method for precise 3D scene motion perception using low-level radar echo signals from two consecutive frames. Unlike existing methods that separate radar target detection and motion estimation, RadarMP jointly models both tasks in a unified architecture, enabling consistent radar point cloud generation and pointwise 3D scene flow prediction. Tailored to radar characteristics, we design specialized self-supervised loss functions guided by Doppler shifts and echo intensity, effectively supervising spatial and motion consistency without explicit annotations. Extensive experiments on the public dataset demonstrate that RadarMP achieves reliable motion perception across diverse weather and illumination conditions, outperforming radar-based decoupled motion perception pipelines and enhancing perception capabilities for full-scenario autonomous driving systems.
M^3Detection: Multi-Frame Multi-Level Feature Fusion for Multi-Modal 3D Object Detection with Camera and 4D Imaging Radar
Oct 31, 2025Recent advances in 4D imaging radar have enabled robust perception in adverse weather, while camera sensors provide dense semantic information. Fusing the these complementary modalities has great potential for cost-effective 3D perception. However, most existing camera-radar fusion methods are limited to single-frame inputs, capturing only a partial view of the scene. The incomplete scene information, compounded by image degradation and 4D radar sparsity, hinders overall detection performance. In contrast, multi-frame fusion offers richer spatiotemporal information but faces two challenges: achieving robust and effective object feature fusion across frames and modalities, and mitigating the computational cost of redundant feature extraction. Consequently, we propose M^3Detection, a unified multi-frame 3D object detection framework that performs multi-level feature fusion on multi-modal data from camera and 4D imaging radar. Our framework leverages intermediate features from the baseline detector and employs the tracker to produce reference trajectories, improving computational efficiency and providing richer information for second-stage. In the second stage, we design a global-level inter-object feature aggregation module guided by radar information to align global features across candidate proposals and a local-level inter-grid feature aggregation module that expands local features along the reference trajectories to enhance fine-grained object representation. The aggregated features are then processed by a trajectory-level multi-frame spatiotemporal reasoning module to encode cross-frame interactions and enhance temporal representation. Extensive experiments on the VoD and TJ4DRadSet datasets demonstrate that M^3Detection achieves state-of-the-art 3D detection performance, validating its effectiveness in multi-frame detection with camera-4D imaging radar fusion.
SFGFusion: Surface Fitting Guided 3D Object Detection with 4D Radar and Camera Fusion
Oct 22, 20253D object detection is essential for autonomous driving. As an emerging sensor, 4D imaging radar offers advantages as low cost, long-range detection, and accurate velocity measurement, making it highly suitable for object detection. However, its sparse point clouds and low resolution limit object geometric representation and hinder multi-modal fusion. In this study, we introduce SFGFusion, a novel camera-4D imaging radar detection network guided by surface fitting. By estimating quadratic surface parameters of objects from image and radar data, the explicit surface fitting model enhances spatial representation and cross-modal interaction, enabling more reliable prediction of fine-grained dense depth. The predicted depth serves two purposes: 1) in an image branch to guide the transformation of image features from perspective view (PV) to a unified bird's-eye view (BEV) for multi-modal fusion, improving spatial mapping accuracy; and 2) in a surface pseudo-point branch to generate dense pseudo-point cloud, mitigating the radar point sparsity. The original radar point cloud is also encoded in a separate radar branch. These two point cloud branches adopt a pillar-based method and subsequently transform the features into the BEV space. Finally, a standard 2D backbone and detection head are used to predict object labels and bounding boxes from BEV features. Experimental results show that SFGFusion effectively fuses camera and 4D radar features, achieving superior performance on the TJ4DRadSet and view-of-delft (VoD) object detection benchmarks.
Learning Human-Humanoid Coordination for Collaborative Object Carrying
Oct 16, 2025Human-humanoid collaboration shows significant promise for applications in healthcare, domestic assistance, and manufacturing. While compliant robot-human collaboration has been extensively developed for robotic arms, enabling compliant human-humanoid collaboration remains largely unexplored due to humanoids' complex whole-body dynamics. In this paper, we propose a proprioception-only reinforcement learning approach, COLA, that combines leader and follower behaviors within a single policy. The model is trained in a closed-loop environment with dynamic object interactions to predict object motion patterns and human intentions implicitly, enabling compliant collaboration to maintain load balance through coordinated trajectory planning. We evaluate our approach through comprehensive simulator and real-world experiments on collaborative carrying tasks, demonstrating the effectiveness, generalization, and robustness of our model across various terrains and objects. Simulation experiments demonstrate that our model reduces human effort by 24.7%. compared to baseline approaches while maintaining object stability. Real-world experiments validate robust collaborative carrying across different object types (boxes, desks, stretchers, etc.) and movement patterns (straight-line, turning, slope climbing). Human user studies with 23 participants confirm an average improvement of 27.4% compared to baseline models. Our method enables compliant human-humanoid collaborative carrying without requiring external sensors or complex interaction models, offering a practical solution for real-world deployment.