 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTrack: General Motion Tracking via Physics-Consistent Reference
Feb 27, 2026Learning motion tracking from rich human motion data is a foundational task for achieving general control in humanoid robots, enabling them to perform diverse behaviors. However, discrepancies in morphology and dynamics between humans and robots, combined with data noise, introduce physically infeasible artifacts in reference motions, such as floating and penetration. During both training and execution, these artifacts create a conflict between following inaccurate reference motions and maintaining the robot's stability, hindering the development of a generalizable motion tracking policy. To address these challenges, we introduce OmniTrack, a general tracking framework that explicitly decouples physical feasibility from general motion tracking. In the first stage, a privileged generalist policy generates physically plausible motions that strictly adhere to the robot's dynamics via trajectory rollout in simulation. In the second stage, the general control policy is trained to track these physically feasible motions, ensuring stable and coherent control transfer to the real robot. Experiments show that OmniTrack improves tracking accuracy and demonstrates strong generalization to unseen motions. In real-world tests, OmniTrack achieves hour-long, consistent, and stable tracking, including complex acrobatic motions such as flips and cartwheels. Additionally, we show that OmniTrack supports human-style stable and dynamic online teleoperation, highlighting its robustness and adaptability to varying user inputs.
Simultaneous Tactile-Visual Perception for Learning Multimodal Robot Manipulation
Dec 10, 2025Robotic manipulation requires both rich multimodal perception and effective learning frameworks to handle complex real-world tasks. See-through-skin (STS) sensors, which combine tactile and visual perception, offer promising sensing capabilities, while modern imitation learning provides powerful tools for policy acquisition. However, existing STS designs lack simultaneous multimodal perception and suffer from unreliable tactile tracking. Furthermore, integrating these rich multimodal signals into learning-based manipulation pipelines remains an open challenge. We introduce TacThru, an STS sensor enabling simultaneous visual perception and robust tactile signal extraction, and TacThru-UMI, an imitation learning framework that leverages these multimodal signals for manipulation. Our sensor features a fully transparent elastomer, persistent illumination, novel keyline markers, and efficient tracking, while our learning system integrates these signals through a Transformer-based Diffusion Policy. Experiments on five challenging real-world tasks show that TacThru-UMI achieves an average success rate of 85.5%, significantly outperforming the baselines of alternating tactile-visual (66.3%) and vision-only (55.4%). The system excels in critical scenarios, including contact detection with thin and soft objects and precision manipulation requiring multimodal coordination. This work demonstrates that combining simultaneous multimodal perception with modern learning frameworks enables more precise, adaptable robotic manipulation.
CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
Jun 10, 2025Humanoid teleoperation plays a vital role in demonstrating and collecting data for complex humanoid-scene interactions. However, current teleoperation systems face critical limitations: they decouple upper- and lower-body control to maintain stability, restricting natural coordination, and operate open-loop without real-time position feedback, leading to accumulated drift. The fundamental challenge is achieving precise, coordinated whole-body teleoperation over extended durations while maintaining accurate global positioning. Here we show that an MoE-based teleoperation system, CLONE, with closed-loop error correction enables unprecedented whole-body teleoperation fidelity, maintaining minimal positional drift over long-range trajectories using only head and hand tracking from an MR headset. Unlike previous methods that either sacrifice coordination for stability or suffer from unbounded drift, CLONE learns diverse motion skills while preventing tracking error accumulation through real-time feedback, enabling complex coordinated movements such as ``picking up objects from the ground.'' These results establish a new milestone for whole-body humanoid teleoperation for long-horizon humanoid-scene interaction tasks.
MetaScenes: Towards Automated Replica Creation for Real-world 3D Scans
May 05, 2025Embodied AI (EAI) research requires high-quality, diverse 3D scenes to effectively support skill acquisition, sim-to-real transfer, and generalization. Achieving these quality standards, however, necessitates the precise replication of real-world object diversity. Existing datasets demonstrate that this process heavily relies on artist-driven designs, which demand substantial human effort and present significant scalability challenges. To scalably produce realistic and interactive 3D scenes, we first present MetaScenes, a large-scale, simulatable 3D scene dataset constructed from real-world scans, which includes 15366 objects spanning 831 fine-grained categories. Then, we introduce Scan2Sim, a robust multi-modal alignment model, which enables the automated, high-quality replacement of assets, thereby eliminating the reliance on artist-driven designs for scaling 3D scenes. We further propose two benchmarks to evaluate MetaScenes: a detailed scene synthesis task focused on small item layouts for robotic manipulation and a domain transfer task in vision-and-language navigation (VLN) to validate cross-domain transfer. Results confirm MetaScene's potential to enhance EAI by supporting more generalizable agent learning and sim-to-real applications, introducing new possibilities for EAI research. Project website: https://meta-scenes.github.io/.
Taccel: Scaling Up Vision-based Tactile Robotics via High-performance GPU Simulation
Apr 17, 2025Tactile sensing is crucial for achieving human-level robotic capabilities in manipulation tasks. VBTSs have emerged as a promising solution, offering high spatial resolution and cost-effectiveness by sensing contact through camera-captured deformation patterns of elastic gel pads. However, these sensors' complex physical characteristics and visual signal processing requirements present unique challenges for robotic applications. The lack of efficient and accurate simulation tools for VBTS has significantly limited the scale and scope of tactile robotics research. Here we present Taccel, a high-performance simulation platform that integrates IPC and ABD to model robots, tactile sensors, and objects with both accuracy and unprecedented speed, achieving an 18-fold acceleration over real-time across thousands of parallel environments. Unlike previous simulators that operate at sub-real-time speeds with limited parallelization, Taccel provides precise physics simulation and realistic tactile signals while supporting flexible robot-sensor configurations through user-friendly APIs. Through extensive validation in object recognition, robotic grasping, and articulated object manipulation, we demonstrate precise simulation and successful sim-to-real transfer. These capabilities position Taccel as a powerful tool for scaling up tactile robotics research and development. By enabling large-scale simulation and experimentation with tactile sensing, Taccel accelerates the development of more capable robotic systems, potentially transforming how robots interact with and understand their physical environment.
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Apr 05, 2025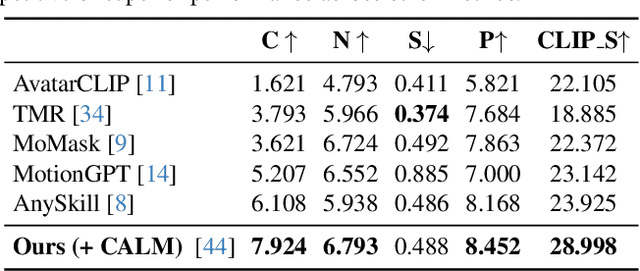
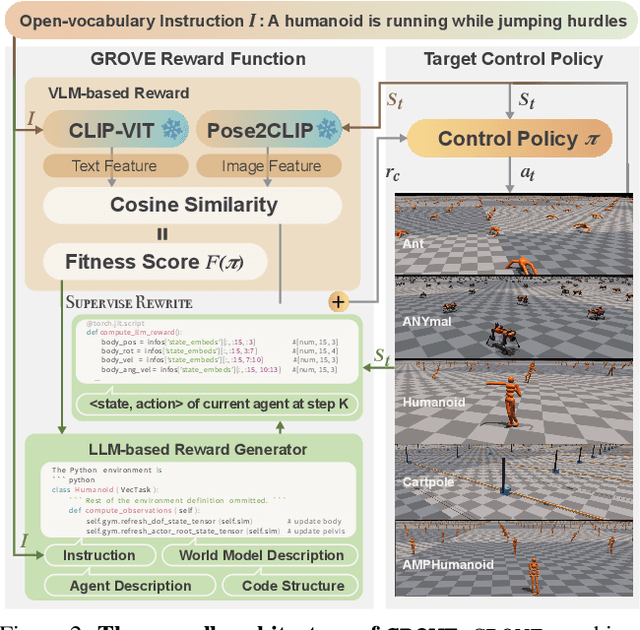
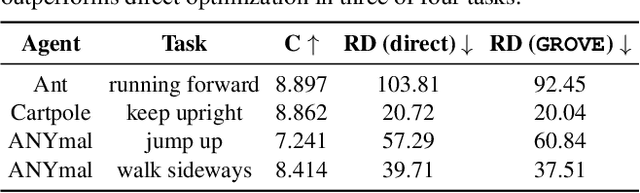

Learning open-vocabulary physical skills for simulated agents presents a significant challenge in artificial intelligence. Current reinforcement learning approaches face critical limitations: manually designed rewards lack scalability across diverse tasks, while demonstration-based methods struggle to generalize beyond their training distribution. We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations. Our key insight is that Large Language Models(LLMs) and Vision Language Models(VLMs) provide complementary guidance -- LLMs generate precise physical constraints capturing task requirements, while VLMs evaluate motion semantics and naturalness. Through an iterative design process, VLM-based feedback continuously refines LLM-generated constraints, creating a self-improving reward system. To bridge the domain gap between simulation and natural images, we develop Pose2CLIP, a lightweight mapper that efficiently projects agent poses directly into semantic feature space without computationally expensive rendering. Extensive experiments across diverse embodiments and learning paradigms demonstrate GROVE's effectiveness, achieving 22.2% higher motion naturalness and 25.7% better task completion scores while training 8.4x faster than previous methods. These results establish a new foundation for scalable physical skill acquisition in simulated environments.
Dexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
Mar 27, 2025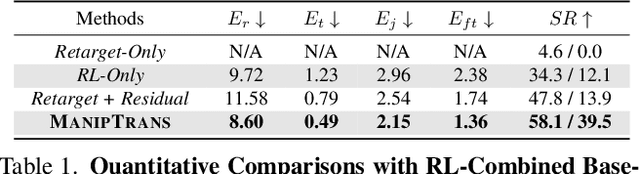
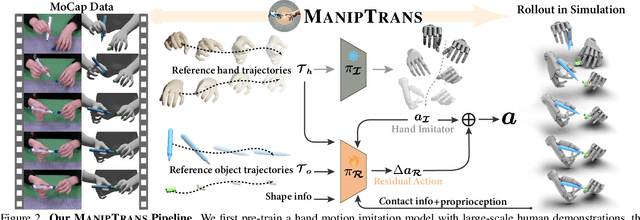

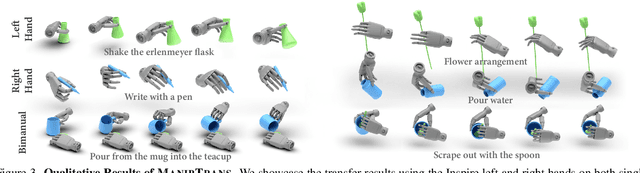
Human hands play a central role in interacting, motivating increasing research in dexterous robotic manipulation. Data-driven embodied AI algorithms demand precise, large-scale, human-like manipulation sequences, which are challenging to obtain with conventional reinforcement learning or real-world teleoperation. To address this, we introduce ManipTrans, a novel two-stage method for efficiently transferring human bimanual skills to dexterous robotic hands in simulation. ManipTrans first pre-trains a generalist trajectory imitator to mimic hand motion, then fine-tunes a specific residual module under interaction constraints, enabling efficient learning and accurate execution of complex bimanual tasks. Experiments show that ManipTrans surpasses state-of-the-art methods in success rate, fidelity, and efficiency. Leveraging ManipTrans, we transfer multiple hand-object datasets to robotic hands, creating DexManipNet, a large-scale dataset featuring previously unexplored tasks like pen capping and bottle unscrewing. DexManipNet comprises 3.3K episodes of robotic manipulation and is easily extensible, facilitating further policy training for dexterous hands and enabling real-world deployments.
Dynamic Motion Blending for Versatile Motion Editing
Mar 26, 2025Text-guided motion editing enables high-level semantic control and iterative modifications beyond traditional keyframe animation. Existing methods rely on limited pre-collected training triplets, which severely hinders their versatility in diverse editing scenarios. We introduce MotionCutMix, an online data augmentation technique that dynamically generates training triplets by blending body part motions based on input text. While MotionCutMix effectively expands the training distribution, the compositional nature introduces increased randomness and potential body part incoordination. To model such a rich distribution, we present MotionReFit, an auto-regressive diffusion model with a motion coordinator. The auto-regressive architecture facilitates learning by decomposing long sequences, while the motion coordinator mitigates the artifacts of motion composition. Our method handles both spatial and temporal motion edits directly from high-level human instructions, without relying on additional specifications or Large Language Models. Through extensive experiments, we show that MotionReFit achieves state-of-the-art performance in text-guided motion editing.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion
Mar 19, 2025
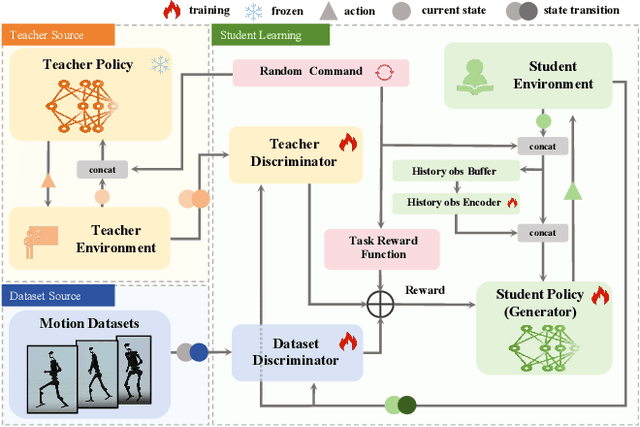


Humanoid robots are anticipated to acquire a wide range of locomotion capabilities while ensuring natural movement across varying speeds and terrains. Existing methods encounter a fundamental dilemma in learning humanoid locomotion: reinforcement learning with handcrafted rewards can achieve agile locomotion but produces unnatural gaits, while Generative Adversarial Imitation Learning (GAIL) with motion capture data yields natural movements but suffers from unstable training processes and restricted agility. Integrating these approaches proves challenging due to the inherent heterogeneity between expert policies and human motion datasets. To address this, we introduce StyleLoco, a novel two-stage framework that bridges this gap through a Generative Adversarial Distillation (GAD) process. Our framework begins by training a teacher policy using reinforcement learning to achieve agile and dynamic locomotion. It then employs a multi-discriminator architecture, where distinct discriminators concurrently extract skills from both the teacher policy and motion capture data. This approach effectively combines the agility of reinforcement learning with the natural fluidity of human-like movements while mitigating the instability issues commonly associated with adversarial training. Through extensive simulation and real-world experiments, we demonstrate that StyleLoco enables humanoid robots to perform diverse locomotion tasks with the precision of expertly trained policies and the natural aesthetics of human motion, successfully transferring styles across different movement types while maintaining stable locomotion across a broad spectrum of command inputs.