 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-Aware Diffusion for Generalizable Robotic Manipulation
Jan 16, 2026Robust generalization in robotic manipulation is crucial for robots to adapt flexibly to diverse environments. Existing methods usually improve generalization by scaling data and networks, but model tasks independently and overlook skill-level information. Observing that tasks within the same skill share similar motion patterns, we propose Skill-Aware Diffusion (SADiff), which explicitly incorporates skill-level information to improve generalization. SADiff learns skill-specific representations through a skill-aware encoding module with learnable skill tokens, and conditions a skill-constrained diffusion model to generate object-centric motion flow. A skill-retrieval transformation strategy further exploits skill-specific trajectory priors to refine the mapping from 2D motion flow to executable 3D actions. Furthermore, we introduce IsaacSkill, a high-fidelity dataset containing fundamental robotic skills for comprehensive evaluation and sim-to-real transfer. Experiments in simulation and real-world settings show that SADiff achieves good performance and generalization across various manipulation tasks. Code, data, and videos are available at https://sites.google.com/view/sa-diff.
DRL-TH: Jointly Utilizing Temporal Graph Attention and Hierarchical Fusion for UGV Navigation in Crowded Environments
Dec 30, 2025Deep reinforcement learning (DRL) methods have demonstrated potential for autonomous navigation and obstacle avoidance of unmanned ground vehicles (UGVs) in crowded environments. Most existing approaches rely on single-frame observation and employ simple concatenation for multi-modal fusion, which limits their ability to capture temporal context and hinders dynamic adaptability. To address these challenges, we propose a DRL-based navigation framework, DRL-TH, which leverages temporal graph attention and hierarchical graph pooling to integrate historical observations and adaptively fuse multi-modal information. Specifically, we introduce a temporal-guided graph attention network (TG-GAT) that incorporates temporal weights into attention scores to capture correlations between consecutive frames, thereby enabling the implicit estimation of scene evolution. In addition, we design a graph hierarchical abstraction module (GHAM) that applies hierarchical pooling and learnable weighted fusion to dynamically integrate RGB and LiDAR features, achieving balanced representation across multiple scales. Extensive experiments demonstrate that our DRL-TH outperforms existing methods in various crowded environments. We also implemented DRL-TH control policy on a real UGV and showed that it performed well in real world scenarios.
Multilingual Generative Retrieval via Cross-lingual Semantic Compression
Oct 09, 2025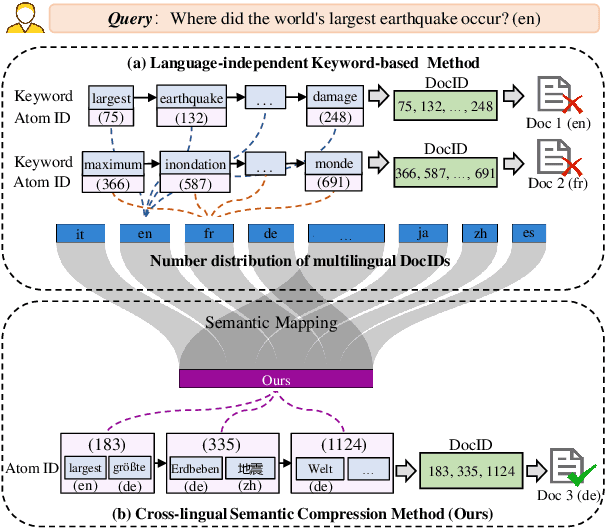
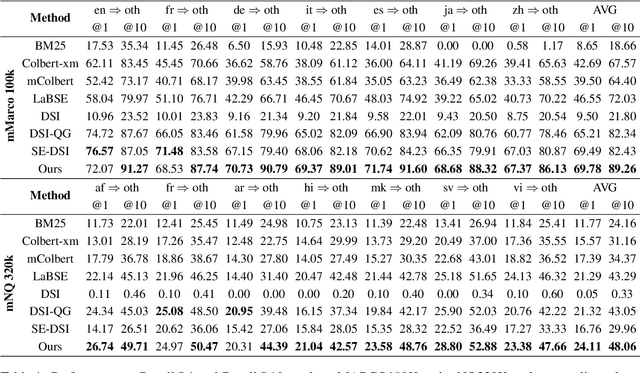
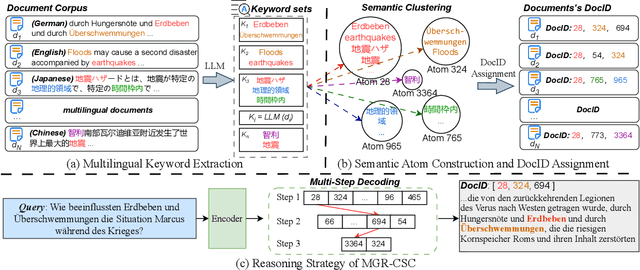

Generative Information Retrieval is an emerging retrieval paradigm that exhibits remarkable performance in monolingual scenarios.However, applying these methods to multilingual retrieval still encounters two primary challenges, cross-lingual identifier misalignment and identifier inflation. To address these limitations, we propose Multilingual Generative Retrieval via Cross-lingual Semantic Compression (MGR-CSC), a novel framework that unifies semantically equivalent multilingual keywords into shared atoms to align semantics and compresses the identifier space, and we propose a dynamic multi-step constrained decoding strategy during retrieval. MGR-CSC improves cross-lingual alignment by assigning consistent identifiers and enhances decoding efficiency by reducing redundancy. Experiments demonstrate that MGR-CSC achieves outstanding retrieval accuracy, improving by 6.83% on mMarco100k and 4.77% on mNQ320k, while reducing document identifiers length by 74.51% and 78.2%, respectively.
SetKE: Knowledge Editing for Knowledge Elements Overlap
Apr 29, 2025Large Language Models (LLMs) excel in tasks such as retrieval and question answering but require updates to incorporate new knowledge and reduce inaccuracies and hallucinations. Traditional updating methods, like fine-tuning and incremental learning, face challenges such as overfitting and high computational costs. Knowledge Editing (KE) provides a promising alternative but often overlooks the Knowledge Element Overlap (KEO) phenomenon, where multiple triplets share common elements, leading to editing conflicts. We identify the prevalence of KEO in existing KE datasets and show its significant impact on current KE methods, causing performance degradation in handling such triplets. To address this, we propose a new formulation, Knowledge Set Editing (KSE), and introduce SetKE, a method that edits sets of triplets simultaneously. Experimental results demonstrate that SetKE outperforms existing methods in KEO scenarios on mainstream LLMs. Additionally, we introduce EditSet, a dataset containing KEO triplets, providing a comprehensive benchmark.
* The CR version will be updated subsequently
Vision-Language Model Predictive Control for Manipulation Planning and Trajectory Generation
Apr 07, 2025



Model Predictive Control (MPC) is a widely adopted control paradigm that leverages predictive models to estimate future system states and optimize control inputs accordingly. However, while MPC excels in planning and control, it lacks the capability for environmental perception, leading to failures in complex and unstructured scenarios. To address this limitation, we introduce Vision-Language Model Predictive Control (VLMPC), a robotic manipulation planning framework that integrates the perception power of vision-language models (VLMs) with MPC. VLMPC utilizes a conditional action sampling module that takes a goal image or language instruction as input and leverages VLM to generate candidate action sequences. These candidates are fed into a video prediction model that simulates future frames based on the actions. In addition, we propose an enhanced variant, Traj-VLMPC, which replaces video prediction with motion trajectory generation to reduce computational complexity while maintaining accuracy. Traj-VLMPC estimates motion dynamics conditioned on the candidate actions, offering a more efficient alternative for long-horizon tasks and real-time applications. Both VLMPC and Traj-VLMPC select the optimal action sequence using a VLM-based hierarchical cost function that captures both pixel-level and knowledge-level consistency between the current observation and the task input. We demonstrate that both approaches outperform existing state-of-the-art methods on public benchmarks and achieve excellent performance in various real-world robotic manipulation tasks. Code is available at https://github.com/PPjmchen/VLMPC.
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Apr 05, 2025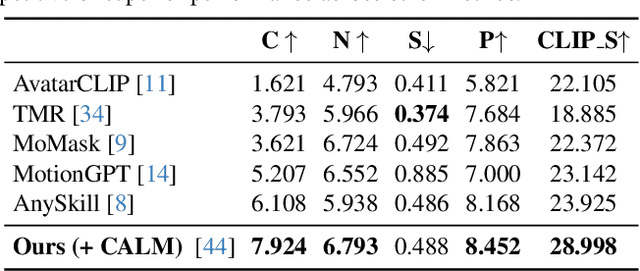
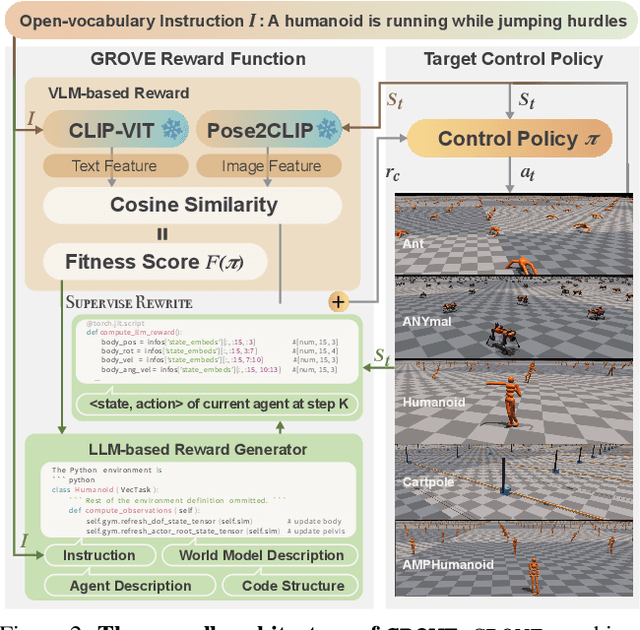

Learning open-vocabulary physical skills for simulated agents presents a significant challenge in artificial intelligence. Current reinforcement learning approaches face critical limitations: manually designed rewards lack scalability across diverse tasks, while demonstration-based methods struggle to generalize beyond their training distribution. We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations. Our key insight is that Large Language Models(LLMs) and Vision Language Models(VLMs) provide complementary guidance -- LLMs generate precise physical constraints capturing task requirements, while VLMs evaluate motion semantics and naturalness. Through an iterative design process, VLM-based feedback continuously refines LLM-generated constraints, creating a self-improving reward system. To bridge the domain gap between simulation and natural images, we develop Pose2CLIP, a lightweight mapper that efficiently projects agent poses directly into semantic feature space without computationally expensive rendering. Extensive experiments across diverse embodiments and learning paradigms demonstrate GROVE's effectiveness, achieving 22.2% higher motion naturalness and 25.7% better task completion scores while training 8.4x faster than previous methods. These results establish a new foundation for scalable physical skill acquisition in simulated environments.
Dexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion
Mar 19, 2025
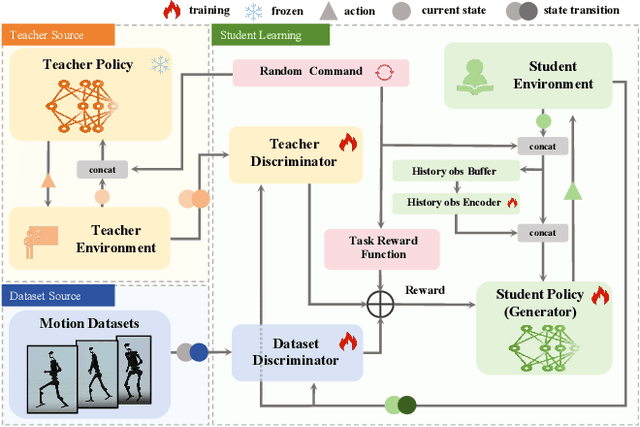


Humanoid robots are anticipated to acquire a wide range of locomotion capabilities while ensuring natural movement across varying speeds and terrains. Existing methods encounter a fundamental dilemma in learning humanoid locomotion: reinforcement learning with handcrafted rewards can achieve agile locomotion but produces unnatural gaits, while Generative Adversarial Imitation Learning (GAIL) with motion capture data yields natural movements but suffers from unstable training processes and restricted agility. Integrating these approaches proves challenging due to the inherent heterogeneity between expert policies and human motion datasets. To address this, we introduce StyleLoco, a novel two-stage framework that bridges this gap through a Generative Adversarial Distillation (GAD) process. Our framework begins by training a teacher policy using reinforcement learning to achieve agile and dynamic locomotion. It then employs a multi-discriminator architecture, where distinct discriminators concurrently extract skills from both the teacher policy and motion capture data. This approach effectively combines the agility of reinforcement learning with the natural fluidity of human-like movements while mitigating the instability issues commonly associated with adversarial training. Through extensive simulation and real-world experiments, we demonstrate that StyleLoco enables humanoid robots to perform diverse locomotion tasks with the precision of expertly trained policies and the natural aesthetics of human motion, successfully transferring styles across different movement types while maintaining stable locomotion across a broad spectrum of command inputs.
Generalize Drug Response Prediction by Latent Independent Projection for Asymmetric Constrained Domain Generalization
Feb 06, 2025



The accurate prediction of drug responses remains a formidable challenge, particularly at the single-cell level and in clinical treatment contexts. Some studies employ transfer learning techniques to predict drug responses in individual cells and patients, but they require access to target-domain data during training, which is often unavailable or only obtainable in future. In this study, we propose a novel domain generalization framework, termed panCancerDR, to address this challenge. We conceptualize each cancer type as a distinct source domain, with its cell lines serving as domain-specific samples. Our primary objective is to extract domain-invariant features from the expression profiles of cell lines across diverse cancer types, thereby generalize the predictive capacity to out-of-distribution samples. To enhance robustness, we introduce a latent independence projection (LIP) module that encourages the encoder to extract informative yet non-redundant features. Also, we propose an asymmetric adaptive clustering constraint, which clusters drug-sensitive samples into a compact group while drives resistant samples dispersed across separate clusters in the latent space. Our empirical experiments demonstrate that panCancerDR effectively learns task-relevant features from diverse source domains, and achieves accurate predictions of drug response for unseen cancer type during training. Furthermore, when evaluated on single-cell and patient-level prediction tasks, our model-trained solely on in vitro cell line data without access to target-domain information-consistently outperforms and matched current state-of-the-art methods. These findings highlights the potential of our method for real-world clinical applications.
MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
Aug 20, 2024
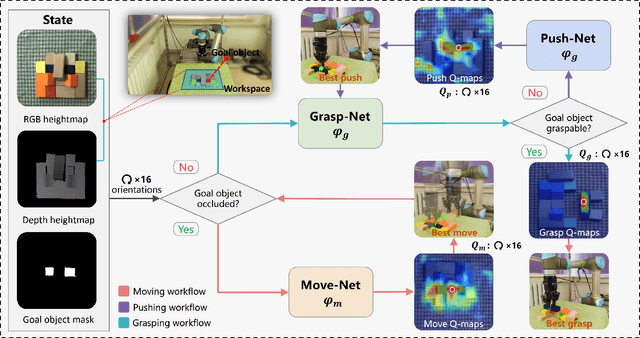
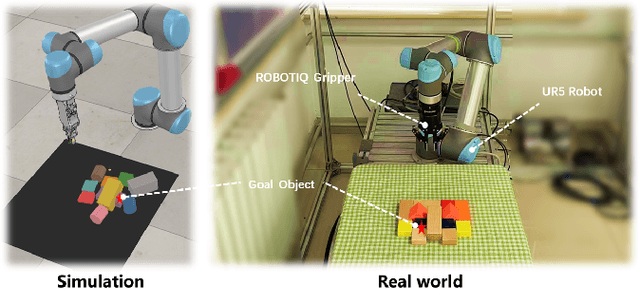
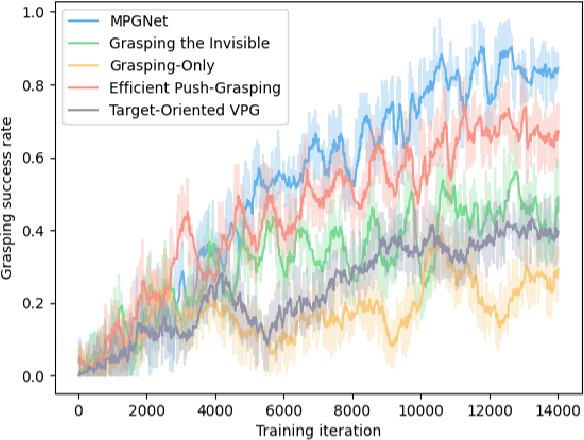
This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.