 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
HIF: Height Interval Filtering for Efficient Dynamic Points Removal
Mar 10, 20253D point cloud mapping plays a essential role in localization and autonomous navigation. However, dynamic objects often leave residual traces during the map construction process, which undermine the performance of subsequent tasks. Therefore, dynamic object removal has become a critical challenge in point cloud based map construction within dynamic scenarios. Existing approaches, however, often incur significant computational overhead, making it difficult to meet the real-time processing requirements. To address this issue, we introduce the Height Interval Filtering (HIF) method. This approach constructs pillar-based height interval representations to probabilistically model the vertical dimension, with interval probabilities updated through Bayesian inference. It ensures real-time performance while achieving high accuracy and improving robustness in complex environments. Additionally, we propose a low-height preservation strategy that enhances the detection of unknown spaces, reducing misclassification in areas blocked by obstacles (occluded regions). Experiments on public datasets demonstrate that HIF delivers a 7.7 times improvement in time efficiency with comparable accuracy to existing SOTA methods. The code will be publicly available.
ReJSHand: Efficient Real-Time Hand Pose Estimation and Mesh Reconstruction Using Refined Joint and Skeleton Features
Mar 08, 2025Accurate hand pose estimation is vital in robotics, advancing dexterous manipulation in human-computer interaction. Toward this goal, this paper presents ReJSHand (which stands for Refined Joint and Skeleton Features), a cutting-edge network formulated for real-time hand pose estimation and mesh reconstruction. The proposed framework is designed to accurately predict 3D hand gestures under real-time constraints, which is essential for systems that demand agile and responsive hand motion tracking. The network's design prioritizes computational efficiency without compromising accuracy, a prerequisite for instantaneous robotic interactions. Specifically, ReJSHand comprises a 2D keypoint generator, a 3D keypoint generator, an expansion block, and a feature interaction block for meticulously reconstructing 3D hand poses from 2D imagery. In addition, the multi-head self-attention mechanism and a coordinate attention layer enhance feature representation, streamlining the creation of hand mesh vertices through sophisticated feature mapping and linear transformation. Regarding performance, comprehensive evaluations on the FreiHand dataset demonstrate ReJSHand's computational prowess. It achieves a frame rate of 72 frames per second while maintaining a PA-MPJPE (Position-Accurate Mean Per Joint Position Error) of 6.3 mm and a PA-MPVPE (Position-Accurate Mean Per Vertex Position Error) of 6.4 mm. Moreover, our model reaches scores of 0.756 for F@05 and 0.984 for F@15, surpassing modern pipelines and solidifying its position at the forefront of robotic hand pose estimators. To facilitate future studies, we provide our source code at ~\url{https://github.com/daishipeng/ReJSHand}.
HyperGraph ROS: An Open-Source Robot Operating System for Hybrid Parallel Computing based on Computational HyperGraph
Mar 07, 2025


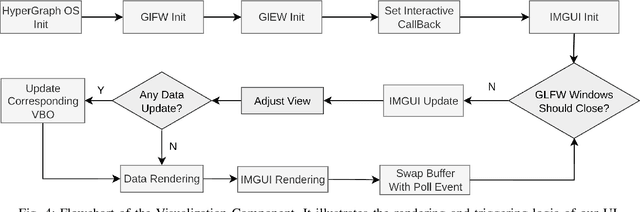
This paper presents HyperGraph ROS, an open-source robot operating system that unifies intra-process, inter-process, and cross-device computation into a computational hypergraph for efficient message passing and parallel execution. In order to optimize communication, HyperGraph ROS dynamically selects the optimal communication mechanism while maintaining a consistent API. For intra-process messages, Intel-TBB Flow Graph is used with C++ pointer passing, which ensures zero memory copying and instant delivery. Meanwhile, inter-process and cross-device communication seamlessly switch to ZeroMQ. When a node receives a message from any source, it is immediately activated and scheduled for parallel execution by Intel-TBB. The computational hypergraph consists of nodes represented by TBB flow graph nodes and edges formed by TBB pointer-based connections for intra-process communication, as well as ZeroMQ links for inter-process and cross-device communication. This structure enables seamless distributed parallelism. Additionally, HyperGraph ROS provides ROS-like utilities such as a parameter server, a coordinate transformation tree, and visualization tools. Evaluation in diverse robotic scenarios demonstrates significantly higher transmission and throughput efficiency compared to ROS 2. Our work is available at https://github.com/wujiazheng2020a/hyper_graph_ros.
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Aug 01, 2024



Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
* 10 pages, 5 figures, 4 tables
3SHNet: Boosting Image-Sentence Retrieval via Visual Semantic-Spatial Self-Highlighting
Apr 26, 2024



In this paper, we propose a novel visual Semantic-Spatial Self-Highlighting Network (termed 3SHNet) for high-precision, high-efficiency and high-generalization image-sentence retrieval. 3SHNet highlights the salient identification of prominent objects and their spatial locations within the visual modality, thus allowing the integration of visual semantics-spatial interactions and maintaining independence between two modalities. This integration effectively combines object regions with the corresponding semantic and position layouts derived from segmentation to enhance the visual representation. And the modality-independence guarantees efficiency and generalization. Additionally, 3SHNet utilizes the structured contextual visual scene information from segmentation to conduct the local (region-based) or global (grid-based) guidance and achieve accurate hybrid-level retrieval. Extensive experiments conducted on MS-COCO and Flickr30K benchmarks substantiate the superior performances, inference efficiency and generalization of the proposed 3SHNet when juxtaposed with contemporary state-of-the-art methodologies. Specifically, on the larger MS-COCO 5K test set, we achieve 16.3%, 24.8%, and 18.3% improvements in terms of rSum score, respectively, compared with the state-of-the-art methods using different image representations, while maintaining optimal retrieval efficiency. Moreover, our performance on cross-dataset generalization improves by 18.6%. Data and code are available at https://github.com/XuriGe1995/3SHNet.
* Accepted Information Processing and Management (IP&M), 10 pages, 9 figures and 8 tables
A Bi-Pyramid Multimodal Fusion Method for the Diagnosis of Bipolar Disorders
Jan 15, 2024



Previous research on the diagnosis of Bipolar disorder has mainly focused on resting-state functional magnetic resonance imaging. However, their accuracy can not meet the requirements of clinical diagnosis. Efficient multimodal fusion strategies have great potential for applications in multimodal data and can further improve the performance of medical diagnosis models. In this work, we utilize both sMRI and fMRI data and propose a novel multimodal diagnosis model for bipolar disorder. The proposed Patch Pyramid Feature Extraction Module extracts sMRI features, and the spatio-temporal pyramid structure extracts the fMRI features. Finally, they are fused by a fusion module to output diagnosis results with a classifier. Extensive experiments show that our proposed method outperforms others in balanced accuracy from 0.657 to 0.732 on the OpenfMRI dataset, and achieves the state of the art.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023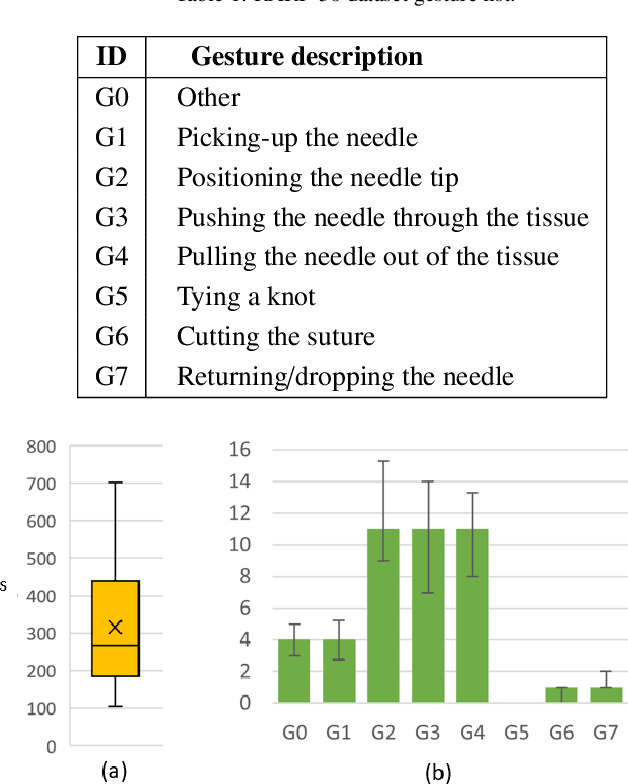
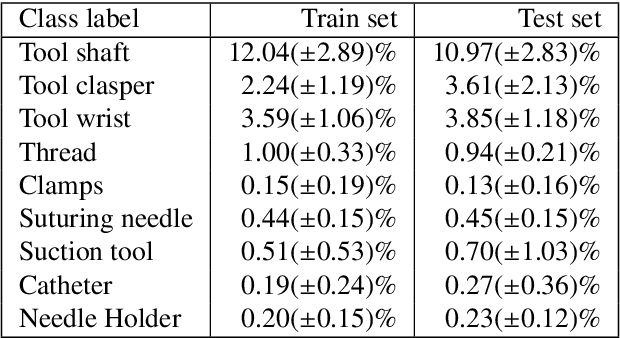
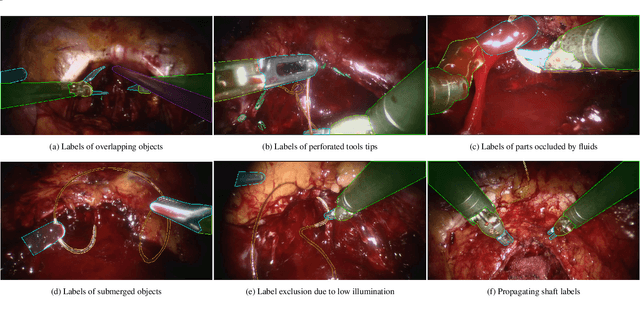
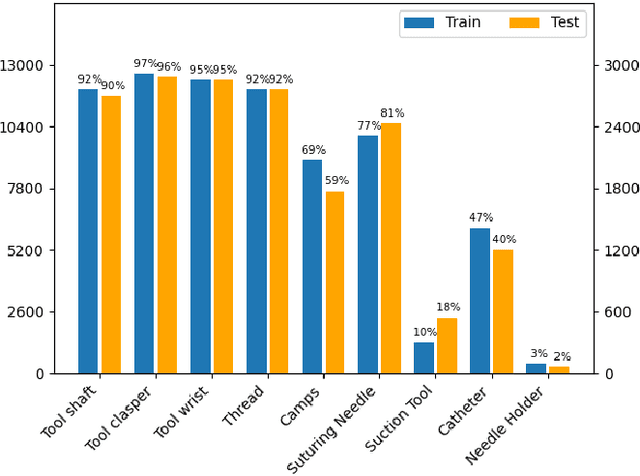
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023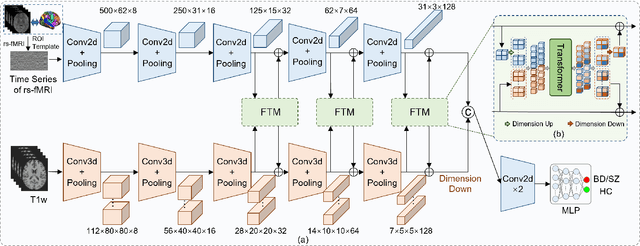
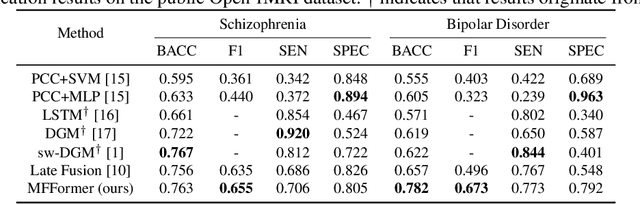
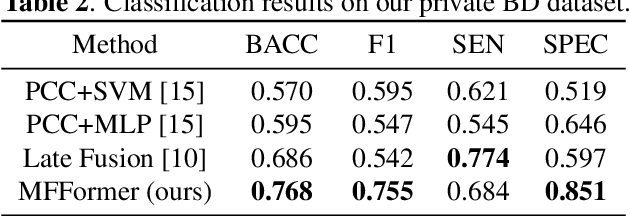
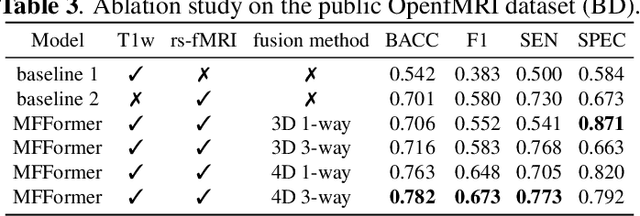
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Temporal Action Localization with Enhanced Instant Discriminability
Sep 11, 2023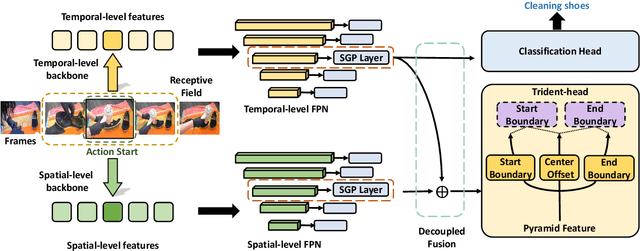
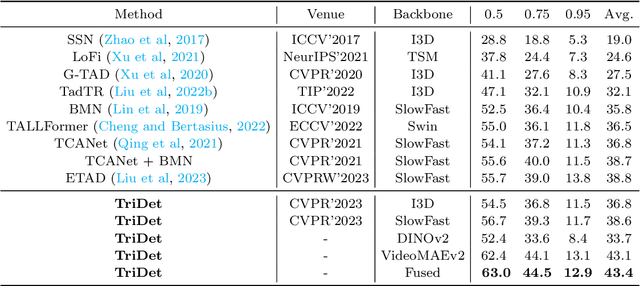
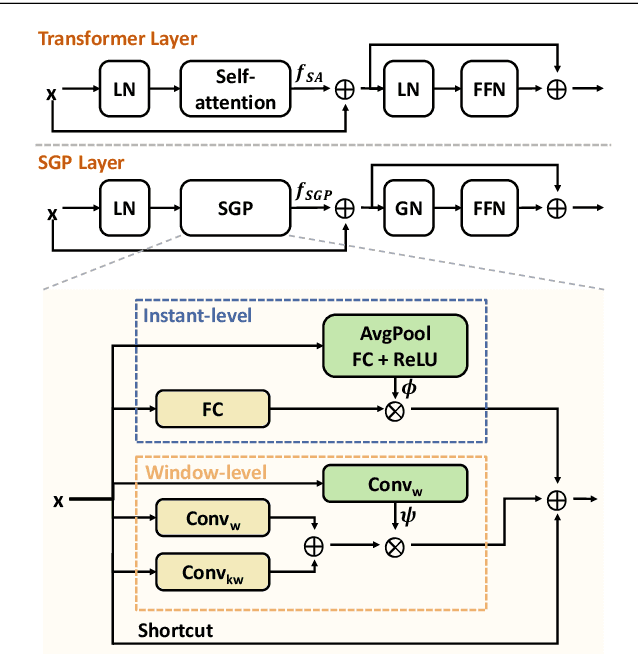
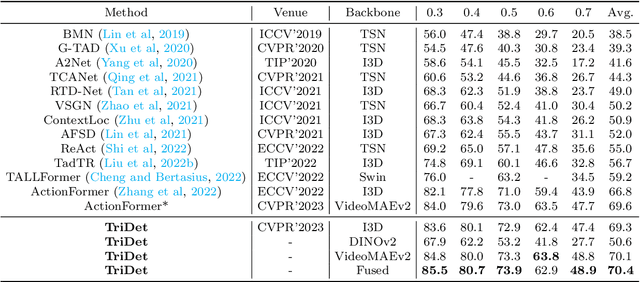
Temporal action detection (TAD) aims to detect all action boundaries and their corresponding categories in an untrimmed video. The unclear boundaries of actions in videos often result in imprecise predictions of action boundaries by existing methods. To resolve this issue, we propose a one-stage framework named TriDet. First, we propose a Trident-head to model the action boundary via an estimated relative probability distribution around the boundary. Then, we analyze the rank-loss problem (i.e. instant discriminability deterioration) in transformer-based methods and propose an efficient scalable-granularity perception (SGP) layer to mitigate this issue. To further push the limit of instant discriminability in the video backbone, we leverage the strong representation capability of pretrained large models and investigate their performance on TAD. Last, considering the adequate spatial-temporal context for classification, we design a decoupled feature pyramid network with separate feature pyramids to incorporate rich spatial context from the large model for localization. Experimental results demonstrate the robustness of TriDet and its state-of-the-art performance on multiple TAD datasets, including hierarchical (multilabel) TAD datasets.