 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReJSHand: Efficient Real-Time Hand Pose Estimation and Mesh Reconstruction Using Refined Joint and Skeleton Features
Mar 08, 2025Accurate hand pose estimation is vital in robotics, advancing dexterous manipulation in human-computer interaction. Toward this goal, this paper presents ReJSHand (which stands for Refined Joint and Skeleton Features), a cutting-edge network formulated for real-time hand pose estimation and mesh reconstruction. The proposed framework is designed to accurately predict 3D hand gestures under real-time constraints, which is essential for systems that demand agile and responsive hand motion tracking. The network's design prioritizes computational efficiency without compromising accuracy, a prerequisite for instantaneous robotic interactions. Specifically, ReJSHand comprises a 2D keypoint generator, a 3D keypoint generator, an expansion block, and a feature interaction block for meticulously reconstructing 3D hand poses from 2D imagery. In addition, the multi-head self-attention mechanism and a coordinate attention layer enhance feature representation, streamlining the creation of hand mesh vertices through sophisticated feature mapping and linear transformation. Regarding performance, comprehensive evaluations on the FreiHand dataset demonstrate ReJSHand's computational prowess. It achieves a frame rate of 72 frames per second while maintaining a PA-MPJPE (Position-Accurate Mean Per Joint Position Error) of 6.3 mm and a PA-MPVPE (Position-Accurate Mean Per Vertex Position Error) of 6.4 mm. Moreover, our model reaches scores of 0.756 for F@05 and 0.984 for F@15, surpassing modern pipelines and solidifying its position at the forefront of robotic hand pose estimators. To facilitate future studies, we provide our source code at ~\url{https://github.com/daishipeng/ReJSHand}.
Future Aspects in Human Action Recognition: Exploring Emerging Techniques and Ethical Influences
Dec 17, 2024
Visual-based human action recognition can be found in various application fields, e.g., surveillance systems, sports analytics, medical assistive technologies, or human-robot interaction frameworks, and it concerns the identification and classification of individuals' activities within a video. Since actions typically occur over a sequence of consecutive images, it is particularly challenging due to the inclusion of temporal analysis, which introduces an extra layer of complexity. However, although multiple approaches try to handle temporal analysis, there are still difficulties because of their computational cost and lack of adaptability. Therefore, different types of vision data, containing transition information between consecutive images, provided by next-generation hardware sensors will guide the robotics community in tackling the problem of human action recognition. On the other hand, while there is a plethora of still-image datasets, that researchers can adopt to train new artificial intelligence models, videos representing human activities are of limited capabilities, e.g., small and unbalanced datasets or selected without control from multiple sources. To this end, generating new and realistic synthetic videos is possible since labeling is performed throughout the data creation process, while reinforcement learning techniques can permit the avoidance of considerable dataset dependence. At the same time, human factors' involvement raises ethical issues for the research community, as doubts and concerns about new technologies already exist.
Spiking neural networks: Towards bio-inspired multimodal perception in robotics
Nov 21, 2024Spiking neural networks (SNNs) have captured apparent interest over the recent years, stemming from neuroscience and reaching the field of artificial intelligence. However, due to their nature SNNs remain far behind in achieving the exceptional performance of deep neural networks (DNNs). As a result, many scholars are exploring ways to enhance SNNs by using learning techniques from DNNs. While this approach has been proven to achieve considerable improvements in SNN performance, we propose another perspective: enhancing the biological plausibility of the models to leverage the advantages of SNNs fully. Our approach aims to propose a brain-like combination of audio-visual signal processing for recognition tasks, intended to succeed in more bio-plausible human-robot interaction applications.
Exploring Emerging Trends and Research Opportunities in Visual Place Recognition
Nov 18, 2024
Visual-based recognition, e.g., image classification, object detection, etc., is a long-standing challenge in computer vision and robotics communities. Concerning the roboticists, since the knowledge of the environment is a prerequisite for complex navigation tasks, visual place recognition is vital for most localization implementations or re-localization and loop closure detection pipelines within simultaneous localization and mapping (SLAM). More specifically, it corresponds to the system's ability to identify and match a previously visited location using computer vision tools. Towards developing novel techniques with enhanced accuracy and robustness, while motivated by the success presented in natural language processing methods, researchers have recently turned their attention to vision-language models, which integrate visual and textual data.
The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection
Apr 27, 2022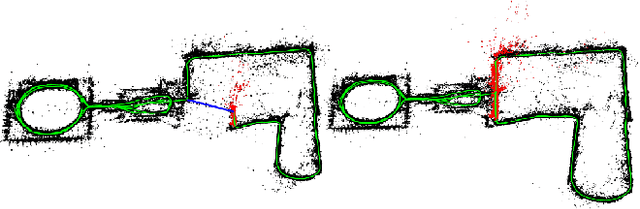
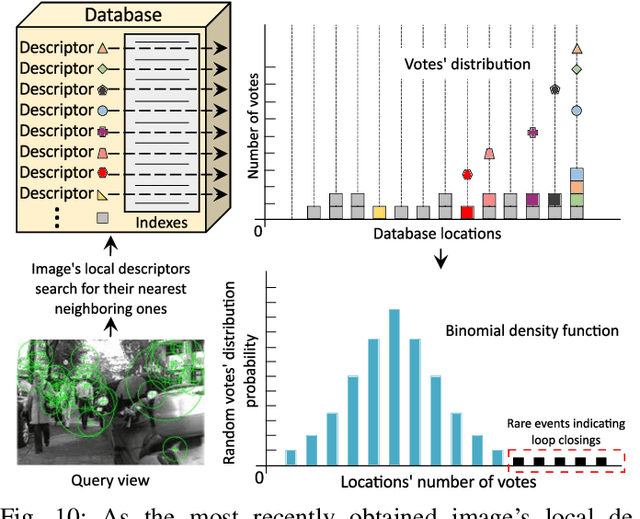
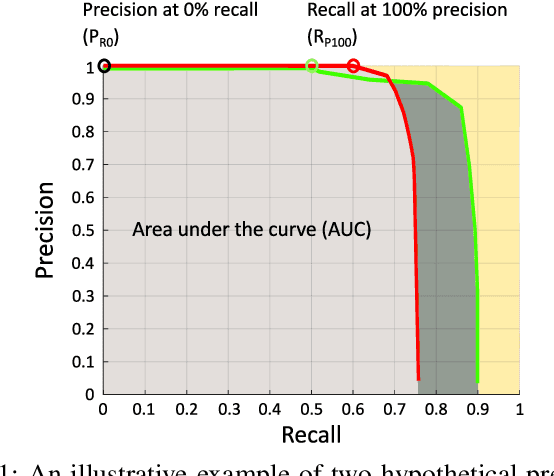

Where am I? This is one of the most critical questions that any intelligent system should answer to decide whether it navigates to a previously visited area. This problem has long been acknowledged for its challenging nature in simultaneous localization and mapping (SLAM), wherein the robot needs to correctly associate the incoming sensory data to the database allowing consistent map generation. The significant advances in computer vision achieved over the last 20 years, the increased computational power, and the growing demand for long-term exploration contributed to efficiently performing such a complex task with inexpensive perception sensors. In this article, visual loop closure detection, which formulates a solution based solely on appearance input data, is surveyed. We start by briefly introducing place recognition and SLAM concepts in robotics. Then, we describe a loop closure detection system's structure, covering an extensive collection of topics, including the feature extraction, the environment representation, the decision-making step, and the evaluation process. We conclude by discussing open and new research challenges, particularly concerning the robustness in dynamic environments, the computational complexity, and scalability in long-term operations. The article aims to serve as a tutorial and a position paper for newcomers to visual loop closure detection.
Real-Time Monocular Human Depth Estimation and Segmentation on Embedded Systems
Aug 24, 2021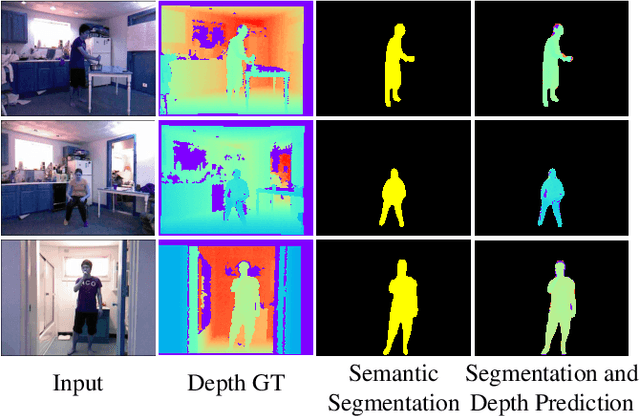
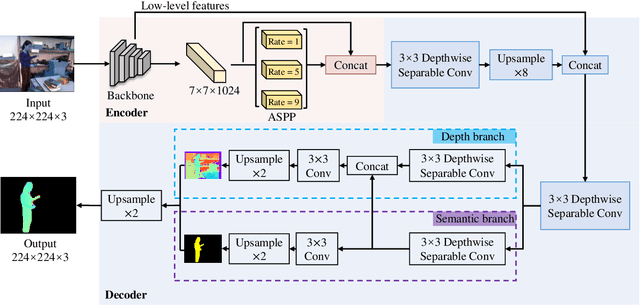
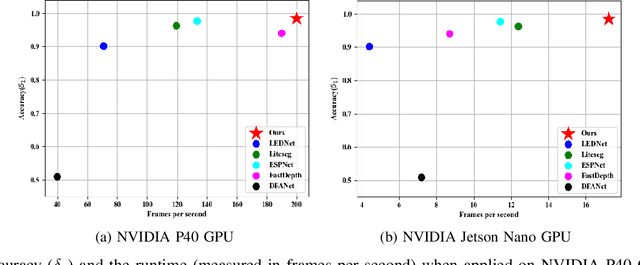
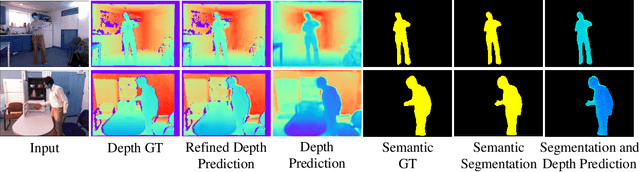
Estimating a scene's depth to achieve collision avoidance against moving pedestrians is a crucial and fundamental problem in the robotic field. This paper proposes a novel, low complexity network architecture for fast and accurate human depth estimation and segmentation in indoor environments, aiming to applications for resource-constrained platforms (including battery-powered aerial, micro-aerial, and ground vehicles) with a monocular camera being the primary perception module. Following the encoder-decoder structure, the proposed framework consists of two branches, one for depth prediction and another for semantic segmentation. Moreover, network structure optimization is employed to improve its forward inference speed. Exhaustive experiments on three self-generated datasets prove our pipeline's capability to execute in real-time, achieving higher frame rates than contemporary state-of-the-art frameworks (114.6 frames per second on an NVIDIA Jetson Nano GPU with TensorRT) while maintaining comparable accuracy.
FastHand: Fast Hand Pose Estimation From A Monocular Camera
Feb 14, 2021

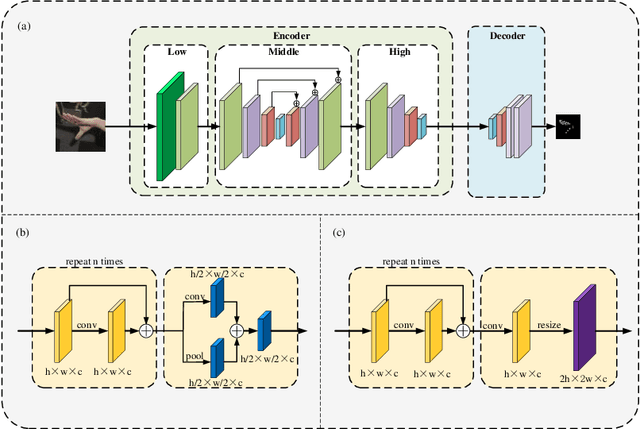

Hand gesture recognition constitutes the initial step in most methods related to human-robot interaction. There are two key challenges in this task. The first one corresponds to the difficulty of achieving stable and accurate hand landmark predictions in real-world scenarios, while the second to the decreased time of forward inference. In this paper, we propose a fast and accurate framework for hand pose estimation, dubbed as "FastHand". Using a lightweight encoder-decoder network architecture, we achieve to fulfil the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.
Fast and Incremental Loop Closure Detection with Deep Features and Proximity Graphs
Sep 29, 2020

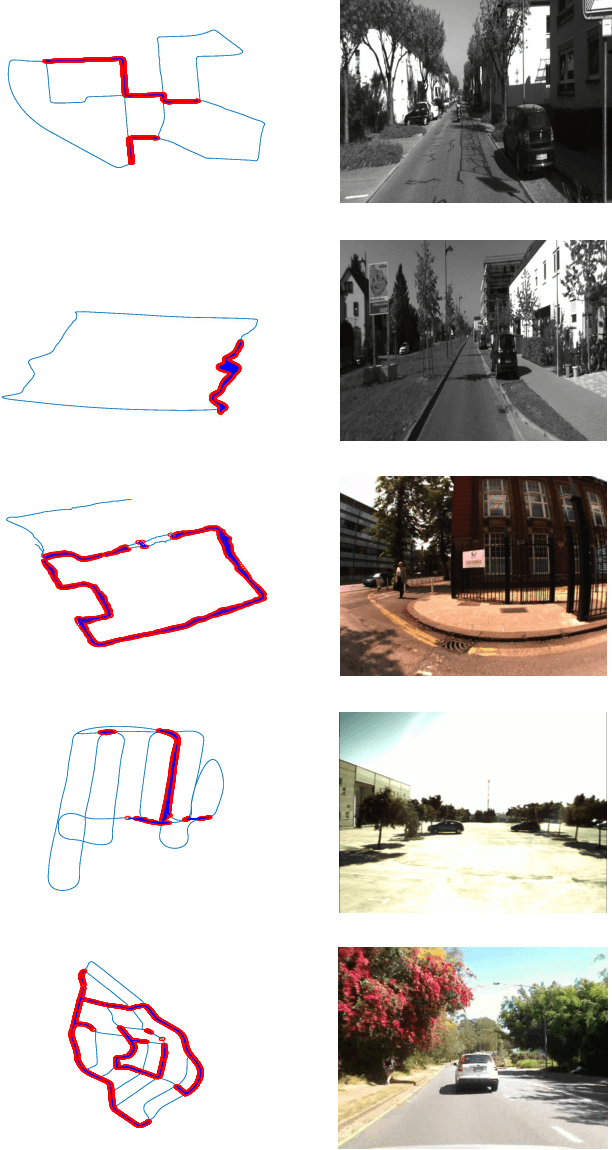
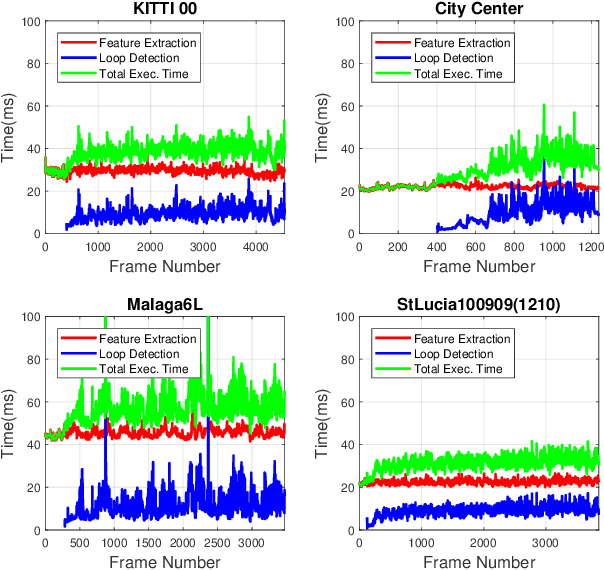
In recent years, methods concerning the place recognition task have been extensively examined from the robotics community within the scope of simultaneous localization and mapping applications. In this article, an appearance-based loop closure detection pipeline is proposed, entitled "FILD++" (Fast and Incremental Loop closure Detection). When the incoming camera observation arrives, global and local visual features are extracted through two passes of a single convolutional neural network. Subsequently, a modified hierarchical-navigable small-world graph incrementally generates a visual database that represents the robot's traversed path based on global features. Given the query sensor measurement, similar locations from the trajectory are retrieved using these representations, while an image-to-image pairing is further evaluated thanks to the spatial information provided by the local features. Exhaustive experiments on several publicly-available datasets exhibit the system's high performance and low execution time compared to other contemporary state-of-the-art pipelines.