 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking neural networks: Towards bio-inspired multimodal perception in robotics
Nov 21, 2024Spiking neural networks (SNNs) have captured apparent interest over the recent years, stemming from neuroscience and reaching the field of artificial intelligence. However, due to their nature SNNs remain far behind in achieving the exceptional performance of deep neural networks (DNNs). As a result, many scholars are exploring ways to enhance SNNs by using learning techniques from DNNs. While this approach has been proven to achieve considerable improvements in SNN performance, we propose another perspective: enhancing the biological plausibility of the models to leverage the advantages of SNNs fully. Our approach aims to propose a brain-like combination of audio-visual signal processing for recognition tasks, intended to succeed in more bio-plausible human-robot interaction applications.
Do Neural Network Weights account for Classes Centers?
Apr 14, 2021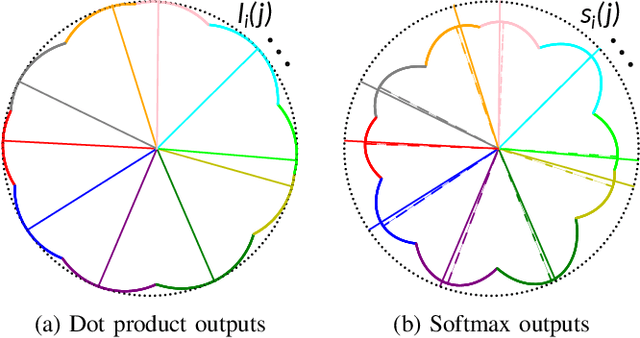
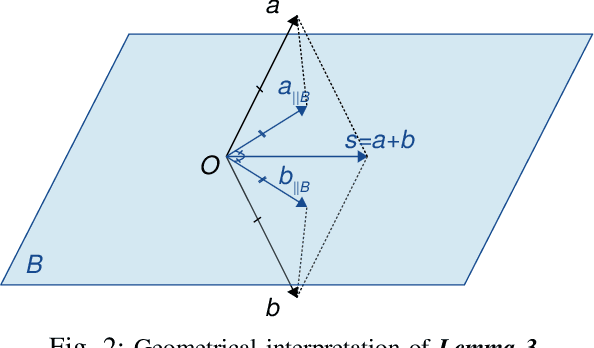
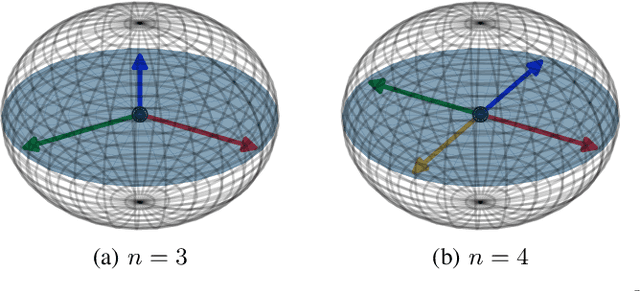
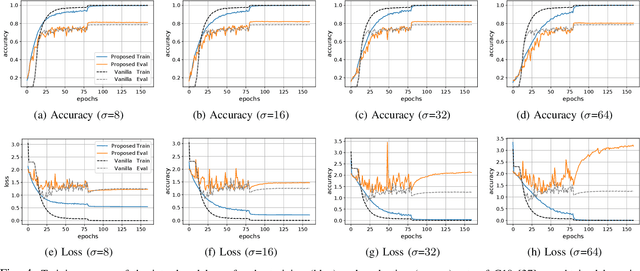
The exploitation of Deep Neural Networks (DNNs) as descriptors in feature learning challenges enjoys apparent popularity over the past few years. The above tendency focuses on the development of effective loss functions that ensure both high feature discrimination among different classes, as well as low geodesic distance between the feature vectors of a given class. The vast majority of the contemporary works rely their formulation on an empirical assumption about the feature space of a network's last hidden layer, claiming that the weight vector of a class accounts for its geometrical center in the studied space. The paper at hand follows a theoretical approach and indicates that the aforementioned hypothesis is not exclusively met. This fact raises stability issues regarding the training procedure of a DNN, as shown in our experimental study. Consequently, a specific symmetry is proposed and studied both analytically and empirically that satisfies the above assumption, addressing the established convergence issues.
HASeparator: Hyperplane-Assisted Softmax
Aug 08, 2020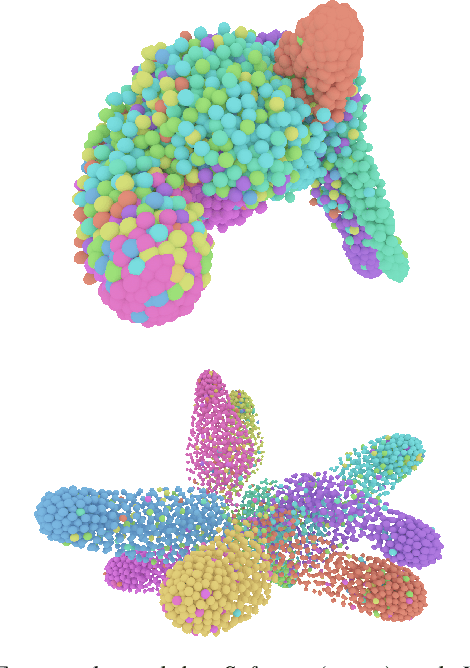
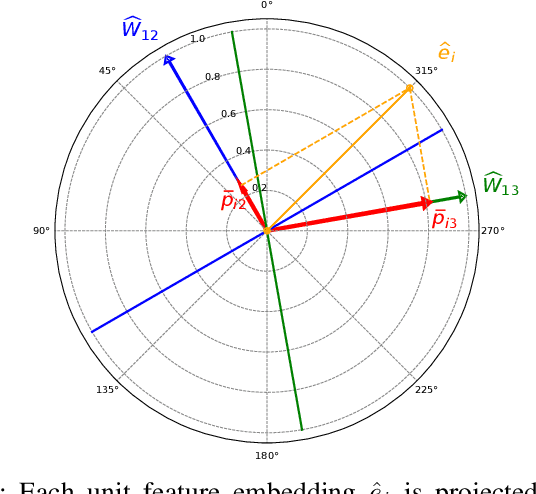
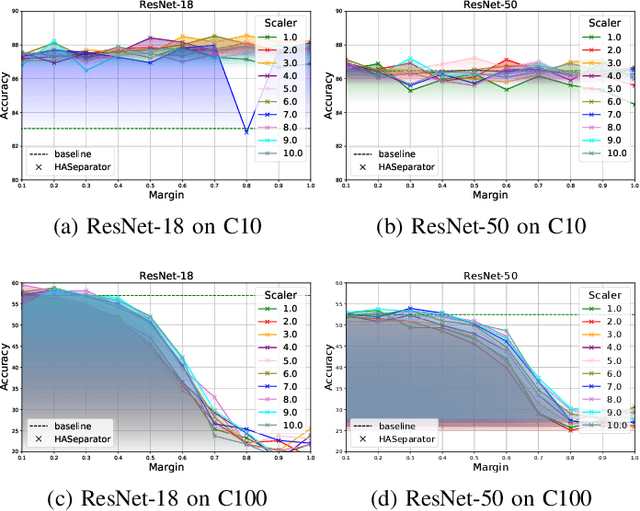
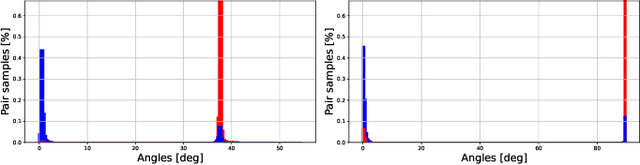
Efficient feature learning with Convolutional Neural Networks (CNNs) constitutes an increasingly imperative property since several challenging tasks of computer vision tend to require cascade schemes and modalities fusion. Feature learning aims at CNN models capable of extracting embeddings, exhibiting high discrimination among the different classes, as well as intra-class compactness. In this paper, a novel approach is introduced that has separator, which focuses on an effective hyperplane-based segregation of the classes instead of the common class centers separation scheme. Accordingly, an innovatory separator, namely the Hyperplane-Assisted Softmax separator (HASeparator), is proposed that demonstrates superior discrimination capabilities, as evaluated on popular image classification benchmarks.
Deep Feature Space: A Geometrical Perspective
Jun 30, 2020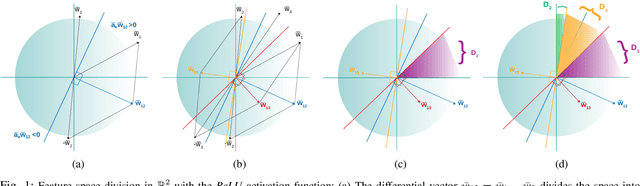
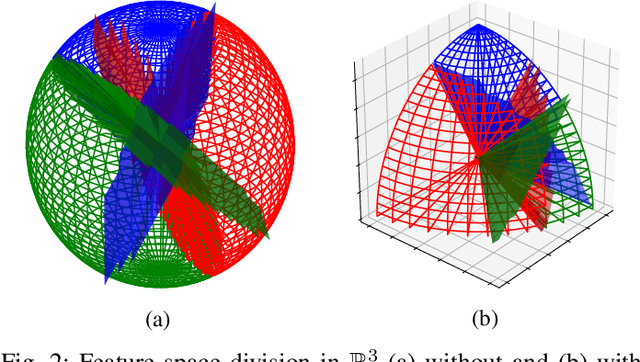
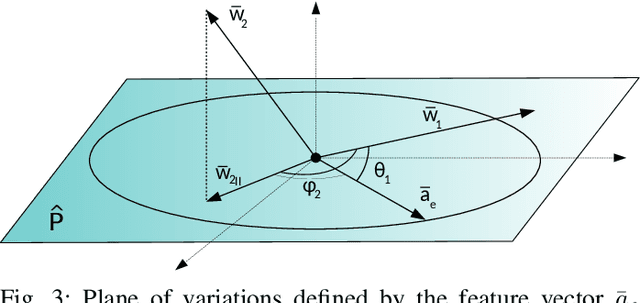
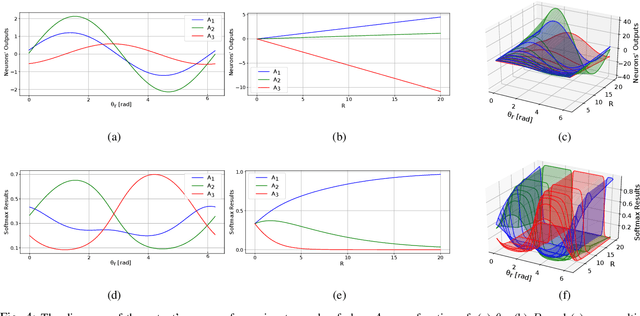
One of the most prominent attributes of Neural Networks (NNs) constitutes their capability of learning to extract robust and descriptive features from high dimensional data, like images. Hence, such an ability renders their exploitation as feature extractors particularly frequent in an abundant of modern reasoning systems. Their application scope mainly includes complex cascade tasks, like multi-modal recognition and deep Reinforcement Learning (RL). However, NNs induce implicit biases that are difficult to avoid or to deal with and are not met in traditional image descriptors. Moreover, the lack of knowledge for describing the intra-layer properties -- and thus their general behavior -- restricts the further applicability of the extracted features. With the paper at hand, a novel way of visualizing and understanding the vector space before the NNs' output layer is presented, aiming to enlighten the deep feature vectors' properties under classification tasks. Main attention is paid to the nature of overfitting in the feature space and its adverse effect on further exploitation. We present the findings that can be derived from our model's formulation, and we evaluate them on realistic recognition scenarios, proving its prominence by improving the obtained results.
Attention! A Lightweight 2D Hand Pose Estimation Approach
Jan 22, 2020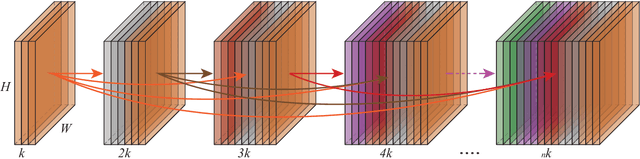
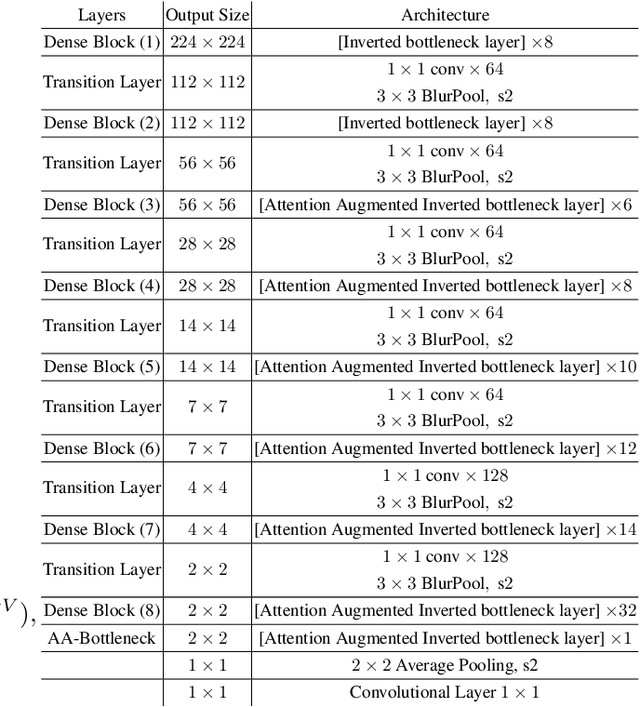
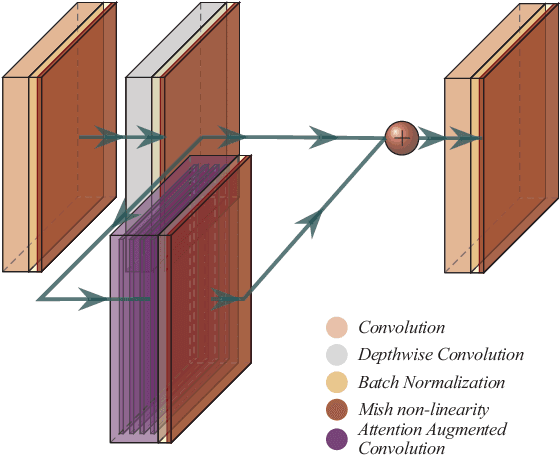
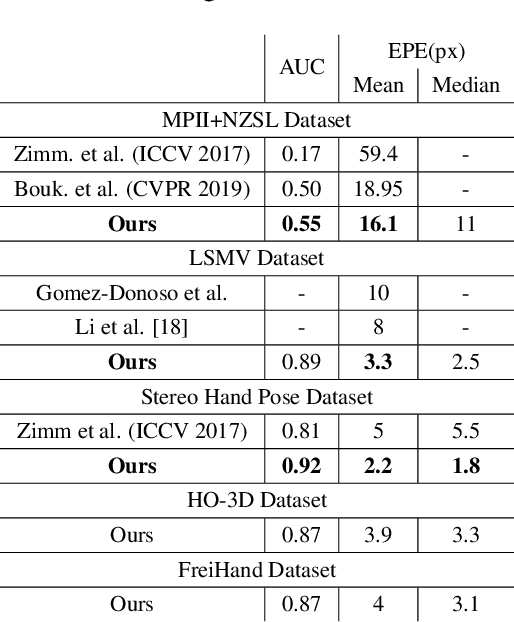
Vision based human pose estimation is an non-invasive technology for Human-Computer Interaction (HCI). Direct use of the hand as an input device provides an attractive interaction method, with no need for specialized sensing equipment, such as exoskeletons, gloves etc, but a camera. Traditionally, HCI is employed in various applications spreading in areas including manufacturing, surgery, entertainment industry and architecture, to mention a few. Deployment of vision based human pose estimation algorithms can give a breath of innovation to these applications. In this letter, we present a novel Convolutional Neural Network architecture, reinforced with a Self-Attention module that it can be deployed on an embedded system, due to its lightweight nature, with just 1.9 Million parameters. The source code and qualitative results are publicly available.