 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV Object Detection and Positioning in a Mining Industrial Metaverse with Custom Geo-Referenced Data
Jun 16, 2025The mining sector increasingly adopts digital tools to improve operational efficiency, safety, and data-driven decision-making. One of the key challenges remains the reliable acquisition of high-resolution, geo-referenced spatial information to support core activities such as extraction planning and on-site monitoring. This work presents an integrated system architecture that combines UAV-based sensing, LiDAR terrain modeling, and deep learning-based object detection to generate spatially accurate information for open-pit mining environments. The proposed pipeline includes geo-referencing, 3D reconstruction, and object localization, enabling structured spatial outputs to be integrated into an industrial digital twin platform. Unlike traditional static surveying methods, the system offers higher coverage and automation potential, with modular components suitable for deployment in real-world industrial contexts. While the current implementation operates in post-flight batch mode, it lays the foundation for real-time extensions. The system contributes to the development of AI-enhanced remote sensing in mining by demonstrating a scalable and field-validated geospatial data workflow that supports situational awareness and infrastructure safety.
The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection
Apr 27, 2022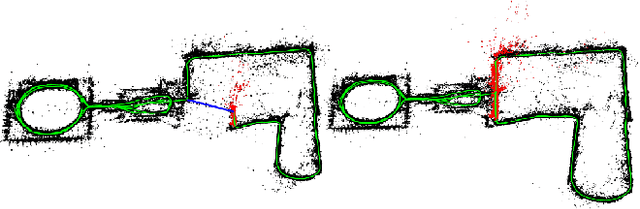
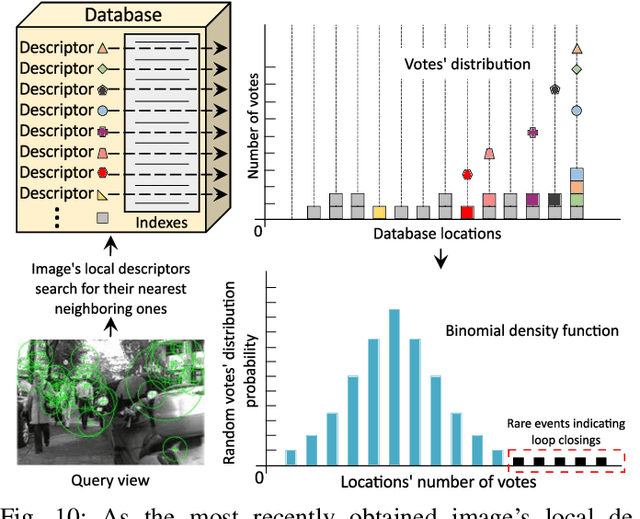
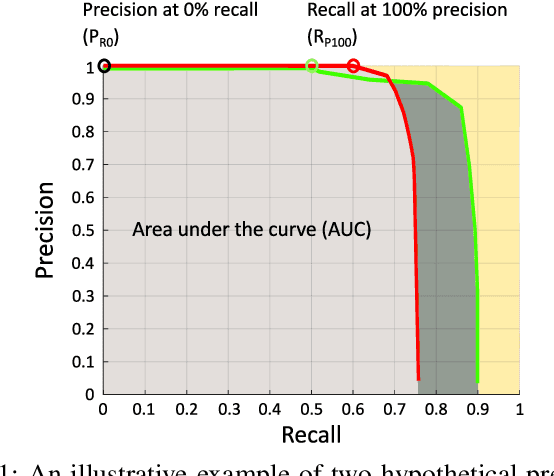

Where am I? This is one of the most critical questions that any intelligent system should answer to decide whether it navigates to a previously visited area. This problem has long been acknowledged for its challenging nature in simultaneous localization and mapping (SLAM), wherein the robot needs to correctly associate the incoming sensory data to the database allowing consistent map generation. The significant advances in computer vision achieved over the last 20 years, the increased computational power, and the growing demand for long-term exploration contributed to efficiently performing such a complex task with inexpensive perception sensors. In this article, visual loop closure detection, which formulates a solution based solely on appearance input data, is surveyed. We start by briefly introducing place recognition and SLAM concepts in robotics. Then, we describe a loop closure detection system's structure, covering an extensive collection of topics, including the feature extraction, the environment representation, the decision-making step, and the evaluation process. We conclude by discussing open and new research challenges, particularly concerning the robustness in dynamic environments, the computational complexity, and scalability in long-term operations. The article aims to serve as a tutorial and a position paper for newcomers to visual loop closure detection.
Do Neural Network Weights account for Classes Centers?
Apr 14, 2021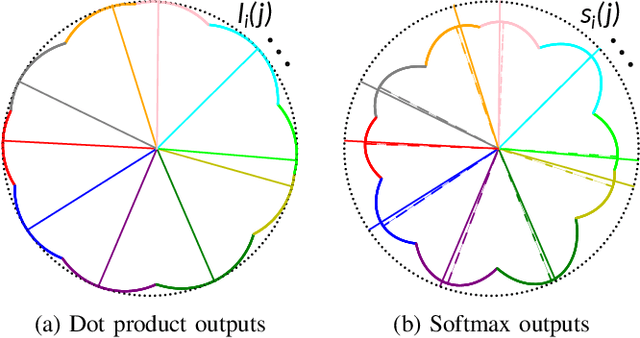
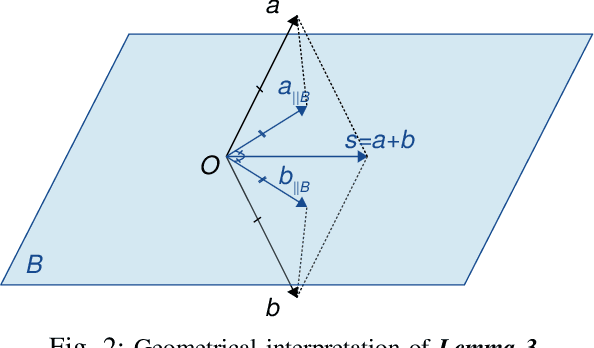
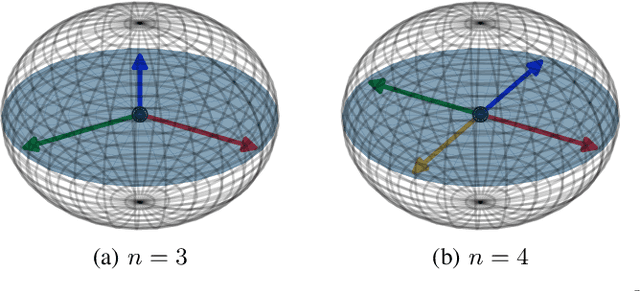
The exploitation of Deep Neural Networks (DNNs) as descriptors in feature learning challenges enjoys apparent popularity over the past few years. The above tendency focuses on the development of effective loss functions that ensure both high feature discrimination among different classes, as well as low geodesic distance between the feature vectors of a given class. The vast majority of the contemporary works rely their formulation on an empirical assumption about the feature space of a network's last hidden layer, claiming that the weight vector of a class accounts for its geometrical center in the studied space. The paper at hand follows a theoretical approach and indicates that the aforementioned hypothesis is not exclusively met. This fact raises stability issues regarding the training procedure of a DNN, as shown in our experimental study. Consequently, a specific symmetry is proposed and studied both analytically and empirically that satisfies the above assumption, addressing the established convergence issues.
HASeparator: Hyperplane-Assisted Softmax
Aug 08, 2020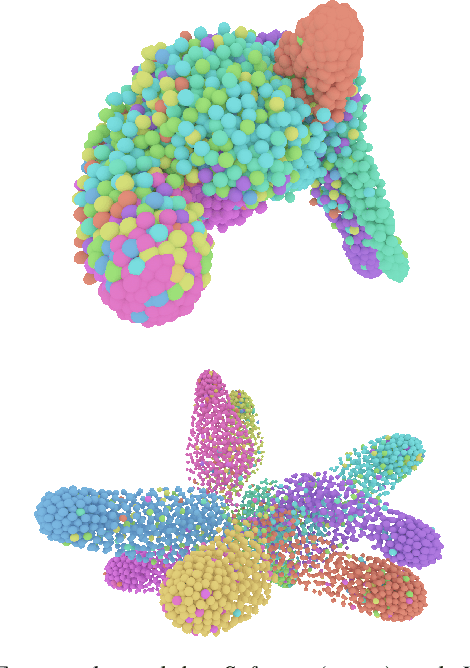
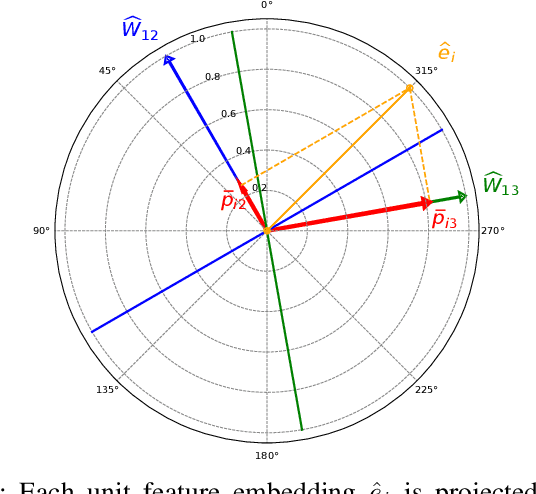
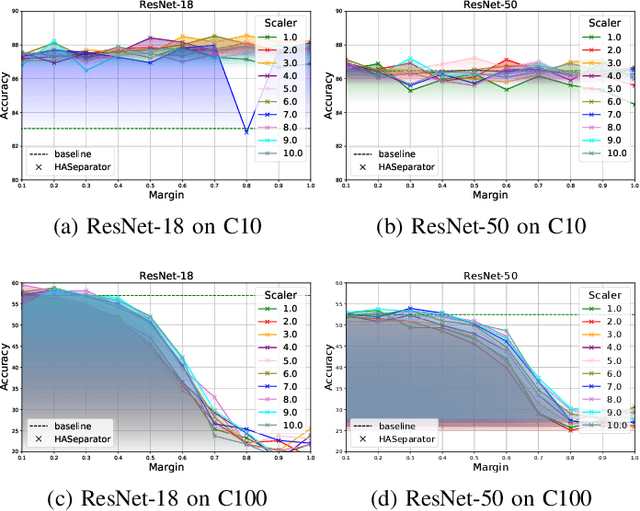
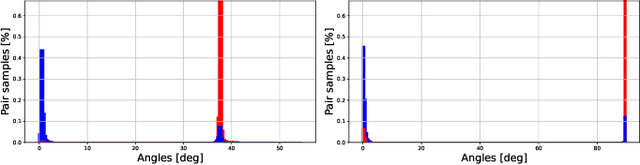
Efficient feature learning with Convolutional Neural Networks (CNNs) constitutes an increasingly imperative property since several challenging tasks of computer vision tend to require cascade schemes and modalities fusion. Feature learning aims at CNN models capable of extracting embeddings, exhibiting high discrimination among the different classes, as well as intra-class compactness. In this paper, a novel approach is introduced that has separator, which focuses on an effective hyperplane-based segregation of the classes instead of the common class centers separation scheme. Accordingly, an innovatory separator, namely the Hyperplane-Assisted Softmax separator (HASeparator), is proposed that demonstrates superior discrimination capabilities, as evaluated on popular image classification benchmarks.
Deep Feature Space: A Geometrical Perspective
Jun 30, 2020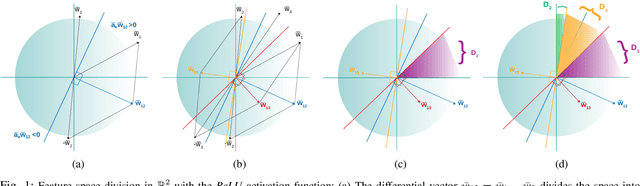
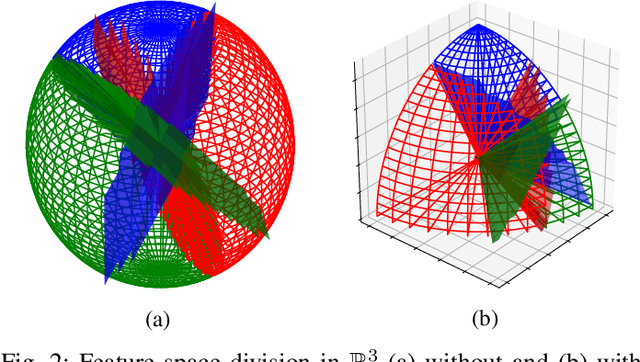
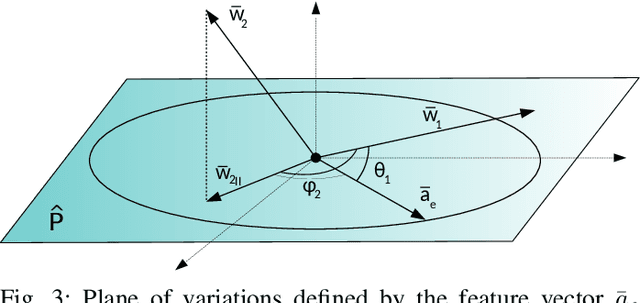
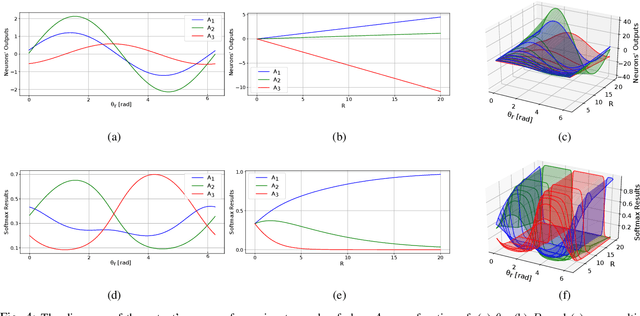
One of the most prominent attributes of Neural Networks (NNs) constitutes their capability of learning to extract robust and descriptive features from high dimensional data, like images. Hence, such an ability renders their exploitation as feature extractors particularly frequent in an abundant of modern reasoning systems. Their application scope mainly includes complex cascade tasks, like multi-modal recognition and deep Reinforcement Learning (RL). However, NNs induce implicit biases that are difficult to avoid or to deal with and are not met in traditional image descriptors. Moreover, the lack of knowledge for describing the intra-layer properties -- and thus their general behavior -- restricts the further applicability of the extracted features. With the paper at hand, a novel way of visualizing and understanding the vector space before the NNs' output layer is presented, aiming to enlighten the deep feature vectors' properties under classification tasks. Main attention is paid to the nature of overfitting in the feature space and its adverse effect on further exploitation. We present the findings that can be derived from our model's formulation, and we evaluate them on realistic recognition scenarios, proving its prominence by improving the obtained results.
Attention! A Lightweight 2D Hand Pose Estimation Approach
Jan 22, 2020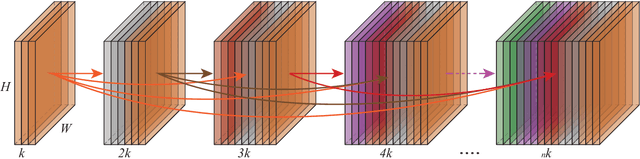
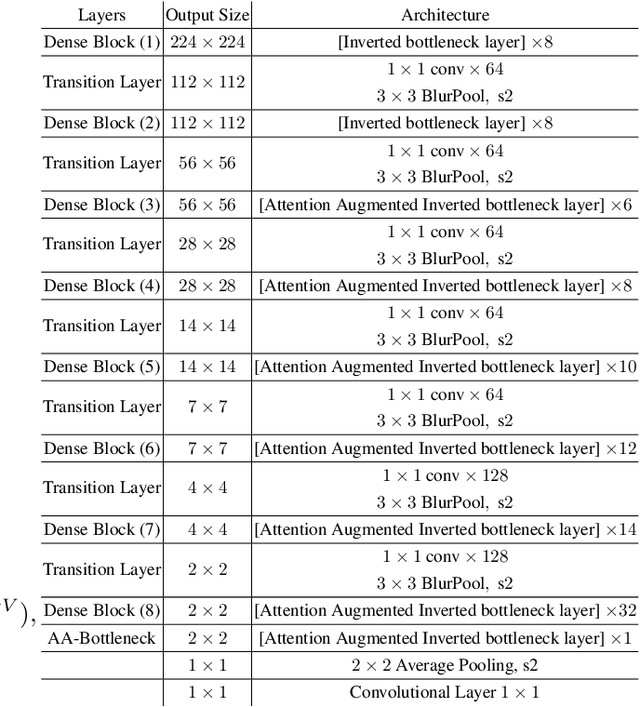
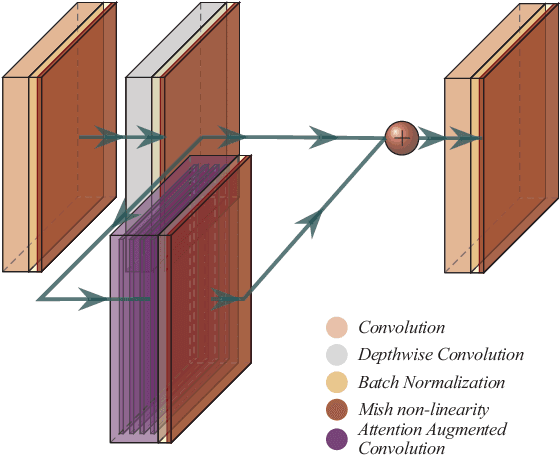
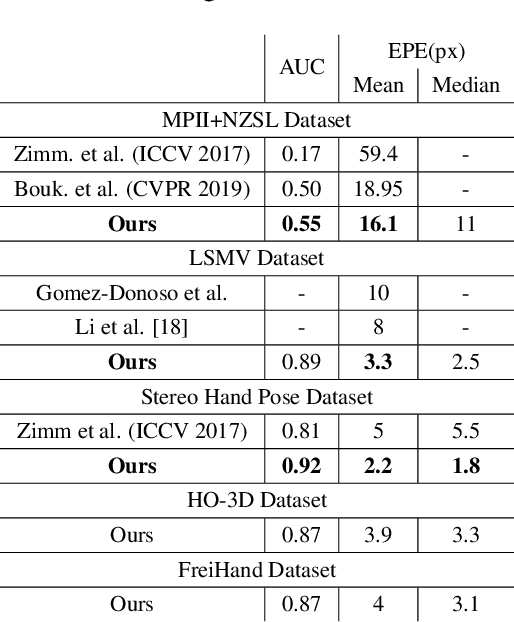
Vision based human pose estimation is an non-invasive technology for Human-Computer Interaction (HCI). Direct use of the hand as an input device provides an attractive interaction method, with no need for specialized sensing equipment, such as exoskeletons, gloves etc, but a camera. Traditionally, HCI is employed in various applications spreading in areas including manufacturing, surgery, entertainment industry and architecture, to mention a few. Deployment of vision based human pose estimation algorithms can give a breath of innovation to these applications. In this letter, we present a novel Convolutional Neural Network architecture, reinforced with a Self-Attention module that it can be deployed on an embedded system, due to its lightweight nature, with just 1.9 Million parameters. The source code and qualitative results are publicly available.