 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Feature Space: A Geometrical Perspective
Paper and Code
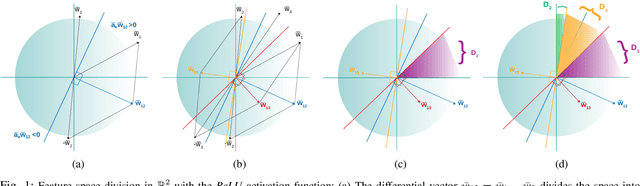
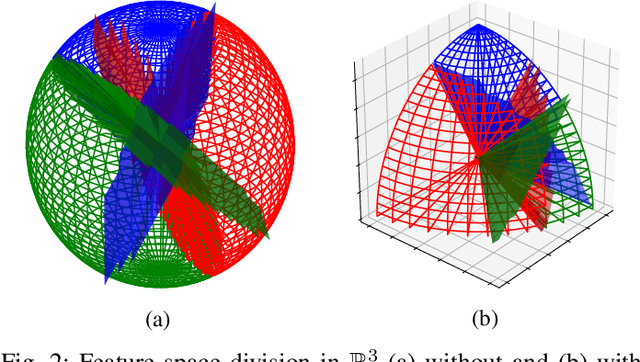
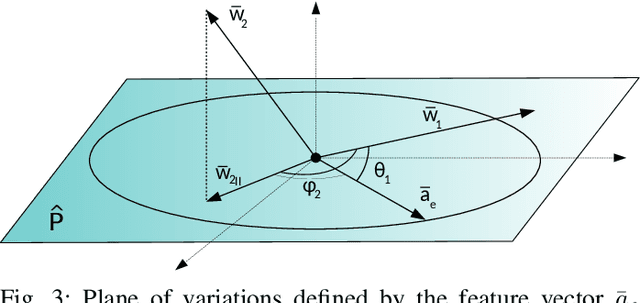
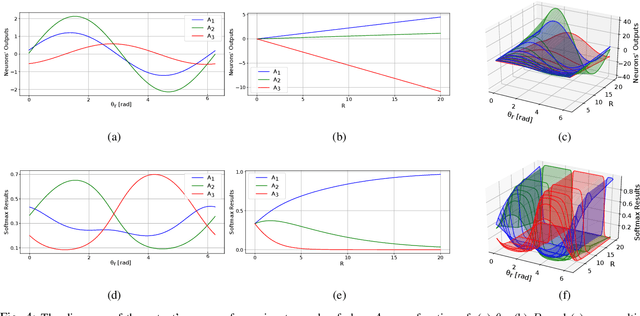
One of the most prominent attributes of Neural Networks (NNs) constitutes their capability of learning to extract robust and descriptive features from high dimensional data, like images. Hence, such an ability renders their exploitation as feature extractors particularly frequent in an abundant of modern reasoning systems. Their application scope mainly includes complex cascade tasks, like multi-modal recognition and deep Reinforcement Learning (RL). However, NNs induce implicit biases that are difficult to avoid or to deal with and are not met in traditional image descriptors. Moreover, the lack of knowledge for describing the intra-layer properties -- and thus their general behavior -- restricts the further applicability of the extracted features. With the paper at hand, a novel way of visualizing and understanding the vector space before the NNs' output layer is presented, aiming to enlighten the deep feature vectors' properties under classification tasks. Main attention is paid to the nature of overfitting in the feature space and its adverse effect on further exploitation. We present the findings that can be derived from our model's formulation, and we evaluate them on realistic recognition scenarios, proving its prominence by improving the obtained results.