 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeeting SLOs, Slashing Hours: Automated Enterprise LLM Optimization with OptiKIT
Jan 28, 2026Enterprise LLM deployment faces a critical scalability challenge: organizations must optimize models systematically to scale AI initiatives within constrained compute budgets, yet the specialized expertise required for manual optimization remains a niche and scarce skillset. This challenge is particularly evident in managing GPU utilization across heterogeneous infrastructure while enabling teams with diverse workloads and limited LLM optimization experience to deploy models efficiently. We present OptiKIT, a distributed LLM optimization framework that democratizes model compression and tuning by automating complex optimization workflows for non-expert teams. OptiKIT provides dynamic resource allocation, staged pipeline execution with automatic cleanup, and seamless enterprise integration. In production, it delivers more than 2x GPU throughput improvement while empowering application teams to achieve consistent performance improvements without deep LLM optimization expertise. We share both the platform design and key engineering insights into resource allocation algorithms, pipeline orchestration, and integration patterns that enable large-scale, production-grade democratization of model optimization. Finally, we open-source the system to enable external contributions and broader reproducibility.
UAV Object Detection and Positioning in a Mining Industrial Metaverse with Custom Geo-Referenced Data
Jun 16, 2025The mining sector increasingly adopts digital tools to improve operational efficiency, safety, and data-driven decision-making. One of the key challenges remains the reliable acquisition of high-resolution, geo-referenced spatial information to support core activities such as extraction planning and on-site monitoring. This work presents an integrated system architecture that combines UAV-based sensing, LiDAR terrain modeling, and deep learning-based object detection to generate spatially accurate information for open-pit mining environments. The proposed pipeline includes geo-referencing, 3D reconstruction, and object localization, enabling structured spatial outputs to be integrated into an industrial digital twin platform. Unlike traditional static surveying methods, the system offers higher coverage and automation potential, with modular components suitable for deployment in real-world industrial contexts. While the current implementation operates in post-flight batch mode, it lays the foundation for real-time extensions. The system contributes to the development of AI-enhanced remote sensing in mining by demonstrating a scalable and field-validated geospatial data workflow that supports situational awareness and infrastructure safety.
Future Aspects in Human Action Recognition: Exploring Emerging Techniques and Ethical Influences
Dec 17, 2024
Visual-based human action recognition can be found in various application fields, e.g., surveillance systems, sports analytics, medical assistive technologies, or human-robot interaction frameworks, and it concerns the identification and classification of individuals' activities within a video. Since actions typically occur over a sequence of consecutive images, it is particularly challenging due to the inclusion of temporal analysis, which introduces an extra layer of complexity. However, although multiple approaches try to handle temporal analysis, there are still difficulties because of their computational cost and lack of adaptability. Therefore, different types of vision data, containing transition information between consecutive images, provided by next-generation hardware sensors will guide the robotics community in tackling the problem of human action recognition. On the other hand, while there is a plethora of still-image datasets, that researchers can adopt to train new artificial intelligence models, videos representing human activities are of limited capabilities, e.g., small and unbalanced datasets or selected without control from multiple sources. To this end, generating new and realistic synthetic videos is possible since labeling is performed throughout the data creation process, while reinforcement learning techniques can permit the avoidance of considerable dataset dependence. At the same time, human factors' involvement raises ethical issues for the research community, as doubts and concerns about new technologies already exist.
Spiking neural networks: Towards bio-inspired multimodal perception in robotics
Nov 21, 2024Spiking neural networks (SNNs) have captured apparent interest over the recent years, stemming from neuroscience and reaching the field of artificial intelligence. However, due to their nature SNNs remain far behind in achieving the exceptional performance of deep neural networks (DNNs). As a result, many scholars are exploring ways to enhance SNNs by using learning techniques from DNNs. While this approach has been proven to achieve considerable improvements in SNN performance, we propose another perspective: enhancing the biological plausibility of the models to leverage the advantages of SNNs fully. Our approach aims to propose a brain-like combination of audio-visual signal processing for recognition tasks, intended to succeed in more bio-plausible human-robot interaction applications.
Exploring Emerging Trends and Research Opportunities in Visual Place Recognition
Nov 18, 2024
Visual-based recognition, e.g., image classification, object detection, etc., is a long-standing challenge in computer vision and robotics communities. Concerning the roboticists, since the knowledge of the environment is a prerequisite for complex navigation tasks, visual place recognition is vital for most localization implementations or re-localization and loop closure detection pipelines within simultaneous localization and mapping (SLAM). More specifically, it corresponds to the system's ability to identify and match a previously visited location using computer vision tools. Towards developing novel techniques with enhanced accuracy and robustness, while motivated by the success presented in natural language processing methods, researchers have recently turned their attention to vision-language models, which integrate visual and textual data.
Defect detection using weakly supervised learning
Mar 27, 2023


In many real-world scenarios, obtaining large amounts of labeled data can be a daunting task. Weakly supervised learning techniques have gained significant attention in recent years as an alternative to traditional supervised learning, as they enable training models using only a limited amount of labeled data. In this paper, the performance of a weakly supervised classifier to its fully supervised counterpart is compared on the task of defect detection. Experiments are conducted on a dataset of images containing defects, and evaluate the two classifiers based on their accuracy, precision, and recall. Our results show that the weakly supervised classifier achieves comparable performance to the supervised classifier, while requiring significantly less labeled data.
Dens-PU: PU Learning with Density-Based Positive Labeled Augmentation
Mar 21, 2023

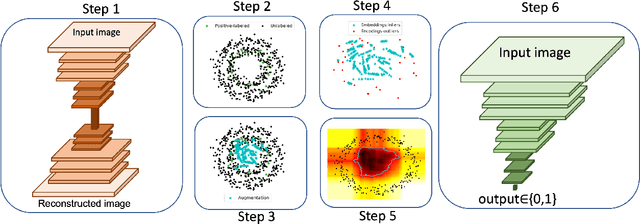
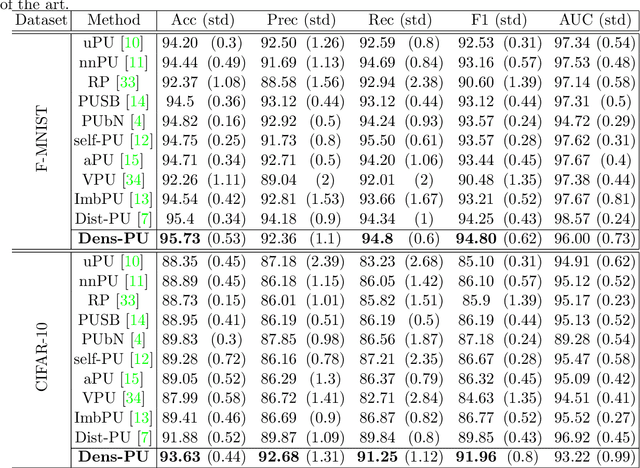
This study proposes a novel approach for solving the PU learning problem based on an anomaly-detection strategy. Latent encodings extracted from positive-labeled data are linearly combined to acquire new samples. These new samples are used as embeddings to increase the density of positive-labeled data and, thus, define a boundary that approximates the positive class. The further a sample is from the boundary the more it is considered as a negative sample. Once a set of negative samples is obtained, the PU learning problem reduces to binary classification. The approach, named Dens-PU due to its reliance on the density of positive-labeled data, was evaluated using benchmark image datasets, and state-of-the-art results were attained.
Embedded light-weight approach for safe landing in populated areas
Feb 28, 2023Landing safety is a challenge heavily engaging the research community recently, due to the increasing interest in applications availed by aerial vehicles. In this paper, we propose a landing safety pipeline based on state of the art object detectors and OctoMap. First, a point cloud of surface obstacles is generated, which is then inserted in an OctoMap. The unoccupied areas are identified, thus resulting to a list of safe landing points. Due to the low inference time achieved by state of the art object detectors and the efficient point cloud manipulation using OctoMap, it is feasible for our approach to deploy on low-weight embedded systems. The proposed pipeline has been evaluated in many simulation scenarios, varying in people density, number, and movement. Simulations were executed with an Nvidia Jetson Nano in the loop to confirm the pipeline's performance and robustness in a low computing power hardware. The experiments yielded promising results with a 95% success rate.
The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection
Apr 27, 2022
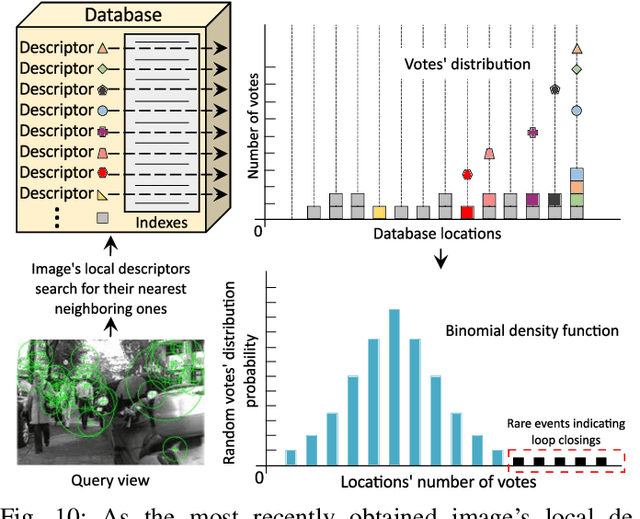

Where am I? This is one of the most critical questions that any intelligent system should answer to decide whether it navigates to a previously visited area. This problem has long been acknowledged for its challenging nature in simultaneous localization and mapping (SLAM), wherein the robot needs to correctly associate the incoming sensory data to the database allowing consistent map generation. The significant advances in computer vision achieved over the last 20 years, the increased computational power, and the growing demand for long-term exploration contributed to efficiently performing such a complex task with inexpensive perception sensors. In this article, visual loop closure detection, which formulates a solution based solely on appearance input data, is surveyed. We start by briefly introducing place recognition and SLAM concepts in robotics. Then, we describe a loop closure detection system's structure, covering an extensive collection of topics, including the feature extraction, the environment representation, the decision-making step, and the evaluation process. We conclude by discussing open and new research challenges, particularly concerning the robustness in dynamic environments, the computational complexity, and scalability in long-term operations. The article aims to serve as a tutorial and a position paper for newcomers to visual loop closure detection.
Do Neural Network Weights account for Classes Centers?
Apr 14, 2021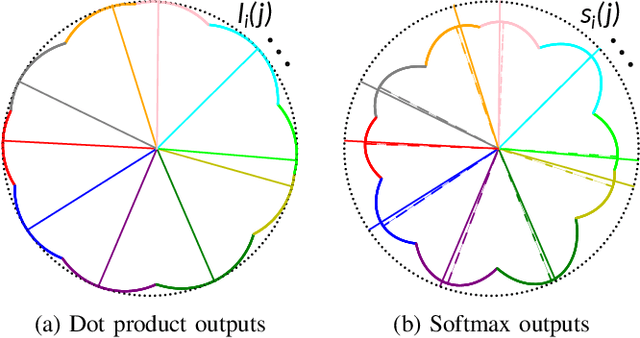
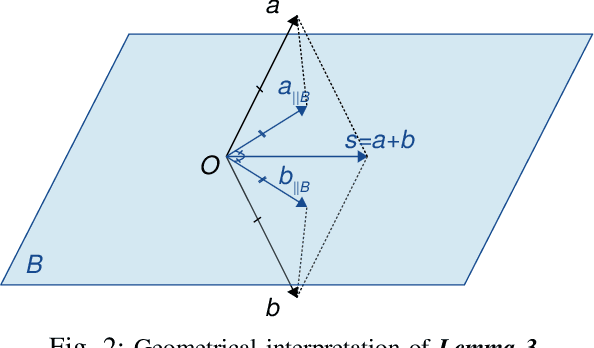
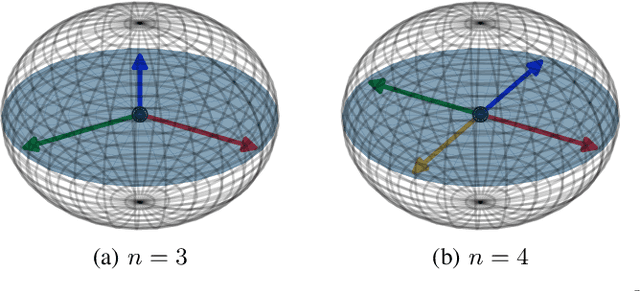
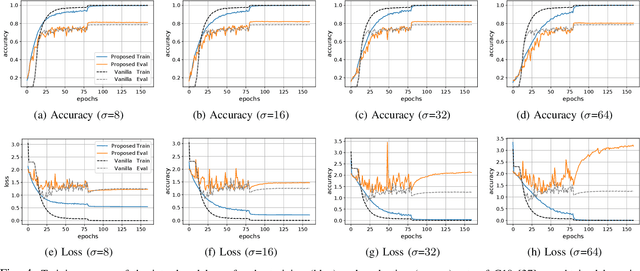
The exploitation of Deep Neural Networks (DNNs) as descriptors in feature learning challenges enjoys apparent popularity over the past few years. The above tendency focuses on the development of effective loss functions that ensure both high feature discrimination among different classes, as well as low geodesic distance between the feature vectors of a given class. The vast majority of the contemporary works rely their formulation on an empirical assumption about the feature space of a network's last hidden layer, claiming that the weight vector of a class accounts for its geometrical center in the studied space. The paper at hand follows a theoretical approach and indicates that the aforementioned hypothesis is not exclusively met. This fact raises stability issues regarding the training procedure of a DNN, as shown in our experimental study. Consequently, a specific symmetry is proposed and studied both analytically and empirically that satisfies the above assumption, addressing the established convergence issues.