 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Reconstruction of Neural Tactile Fields
Feb 13, 2026Robots operating in the real world must plan through environments that deform, yield, and reconfigure under contact, requiring interaction-aware 3D representations that extend beyond static geometric occupancy. To address this, we introduce neural tactile fields, a novel 3D representation that maps spatial locations to the expected tactile response upon contact. Our model predicts these neural tactile fields from a single monocular RGB image -- the first method to do so. When integrated with off-the-shelf path planners, neural tactile fields enable robots to generate paths that avoid high-resistance objects while deliberately routing through low-resistance regions (e.g. foliage), rather than treating all occupied space as equally impassable. Empirically, our learning framework improves volumetric 3D reconstruction by $85.8\%$ and surface reconstruction by $26.7\%$ compared to state-of-the-art monocular 3D reconstruction methods (LRM and Direct3D).
First Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
Adversarial Game-Theoretic Algorithm for Dexterous Grasp Synthesis
Nov 08, 2025For many complex tasks, multi-finger robot hands are poised to revolutionize how we interact with the world, but reliably grasping objects remains a significant challenge. We focus on the problem of synthesizing grasps for multi-finger robot hands that, given a target object's geometry and pose, computes a hand configuration. Existing approaches often struggle to produce reliable grasps that sufficiently constrain object motion, leading to instability under disturbances and failed grasps. A key reason is that during grasp generation, they typically focus on resisting a single wrench, while ignoring the object's potential for adversarial movements, such as escaping. We propose a new grasp-synthesis approach that explicitly captures and leverages the adversarial object motion in grasp generation by formulating the problem as a two-player game. One player controls the robot to generate feasible grasp configurations, while the other adversarially controls the object to seek motions that attempt to escape from the grasp. Simulation experiments on various robot platforms and target objects show that our approach achieves a success rate of 75.78%, up to 19.61% higher than the state-of-the-art baseline. The two-player game mechanism improves the grasping success rate by 27.40% over the method without the game formulation. Our approach requires only 0.28-1.04 seconds on average to generate a grasp configuration, depending on the robot platform, making it suitable for real-world deployment. In real-world experiments, our approach achieves an average success rate of 85.0% on ShadowHand and 87.5% on LeapHand, which confirms its feasibility and effectiveness in real robot setups.
NavMoE: Hybrid Model- and Learning-based Traversability Estimation for Local Navigation via Mixture of Experts
Sep 16, 2025This paper explores traversability estimation for robot navigation. A key bottleneck in traversability estimation lies in efficiently achieving reliable and robust predictions while accurately encoding both geometric and semantic information across diverse environments. We introduce Navigation via Mixture of Experts (NAVMOE), a hierarchical and modular approach for traversability estimation and local navigation. NAVMOE combines multiple specialized models for specific terrain types, each of which can be either a classical model-based or a learning-based approach that predicts traversability for specific terrain types. NAVMOE dynamically weights the contributions of different models based on the input environment through a gating network. Overall, our approach offers three advantages: First, NAVMOE enables traversability estimation to adaptively leverage specialized approaches for different terrains, which enhances generalization across diverse and unseen environments. Second, our approach significantly improves efficiency with negligible cost of solution quality by introducing a training-free lazy gating mechanism, which is designed to minimize the number of activated experts during inference. Third, our approach uses a two-stage training strategy that enables the training for the gating networks within the hybrid MoE method that contains nondifferentiable modules. Extensive experiments show that NAVMOE delivers a better efficiency and performance balance than any individual expert or full ensemble across different domains, improving cross- domain generalization and reducing average computational cost by 81.2% via lazy gating, with less than a 2% loss in path quality.
Single-Step Latent Diffusion for Underwater Image Restoration
Jul 10, 2025Underwater image restoration algorithms seek to restore the color, contrast, and appearance of a scene that is imaged underwater. They are a critical tool in applications ranging from marine ecology and aquaculture to underwater construction and archaeology. While existing pixel-domain diffusion-based image restoration approaches are effective at restoring simple scenes with limited depth variation, they are computationally intensive and often generate unrealistic artifacts when applied to scenes with complex geometry and significant depth variation. In this work we overcome these limitations by combining a novel network architecture (SLURPP) with an accurate synthetic data generation pipeline. SLURPP combines pretrained latent diffusion models -- which encode strong priors on the geometry and depth of scenes -- with an explicit scene decomposition -- which allows one to model and account for the effects of light attenuation and backscattering. To train SLURPP we design a physics-based underwater image synthesis pipeline that applies varied and realistic underwater degradation effects to existing terrestrial image datasets. This approach enables the generation of diverse training data with dense medium/degradation annotations. We evaluate our method extensively on both synthetic and real-world benchmarks and demonstrate state-of-the-art performance. Notably, SLURPP is over 200X faster than existing diffusion-based methods while offering ~ 3 dB improvement in PSNR on synthetic benchmarks. It also offers compelling qualitative improvements on real-world data. Project website https://tianfwang.github.io/slurpp/.
ControlTac: Force- and Position-Controlled Tactile Data Augmentation with a Single Reference Image
May 28, 2025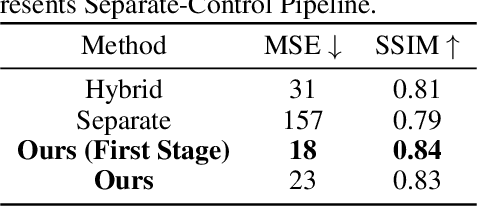
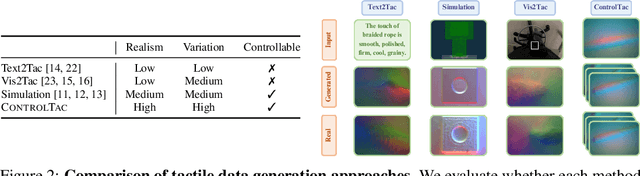
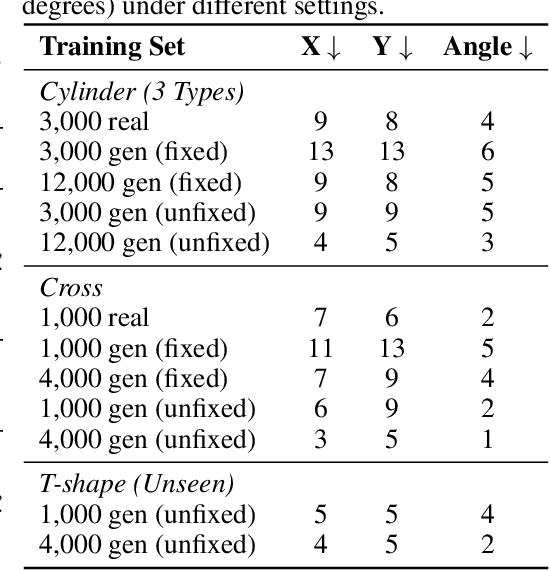
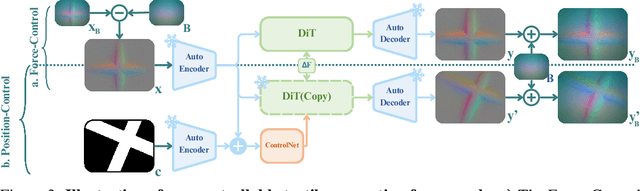
Vision-based tactile sensing has been widely used in perception, reconstruction, and robotic manipulation. However, collecting large-scale tactile data remains costly due to the localized nature of sensor-object interactions and inconsistencies across sensor instances. Existing approaches to scaling tactile data, such as simulation and free-form tactile generation, often suffer from unrealistic output and poor transferability to downstream tasks. To address this, we propose ControlTac, a two-stage controllable framework that generates realistic tactile images conditioned on a single reference tactile image, contact force, and contact position. With those physical priors as control input, ControlTac generates physically plausible and varied tactile images that can be used for effective data augmentation. Through experiments on three downstream tasks, we demonstrate that ControlTac can effectively augment tactile datasets and lead to consistent gains. Our three real-world experiments further validate the practical utility of our approach. Project page: https://dongyuluo.github.io/controltac.
NatSGLD: A Dataset with Speech, Gesture, Logic, and Demonstration for Robot Learning in Natural Human-Robot Interaction
Feb 23, 2025Recent advances in multimodal Human-Robot Interaction (HRI) datasets emphasize the integration of speech and gestures, allowing robots to absorb explicit knowledge and tacit understanding. However, existing datasets primarily focus on elementary tasks like object pointing and pushing, limiting their applicability to complex domains. They prioritize simpler human command data but place less emphasis on training robots to correctly interpret tasks and respond appropriately. To address these gaps, we present the NatSGLD dataset, which was collected using a Wizard of Oz (WoZ) method, where participants interacted with a robot they believed to be autonomous. NatSGLD records humans' multimodal commands (speech and gestures), each paired with a demonstration trajectory and a Linear Temporal Logic (LTL) formula that provides a ground-truth interpretation of the commanded tasks. This dataset serves as a foundational resource for research at the intersection of HRI and machine learning. By providing multimodal inputs and detailed annotations, NatSGLD enables exploration in areas such as multimodal instruction following, plan recognition, and human-advisable reinforcement learning from demonstrations. We release the dataset and code under the MIT License at https://www.snehesh.com/natsgld/ to support future HRI research.
* arXiv admin note: substantial text overlap with arXiv:2403.02274
Structure-from-Sherds++: Robust Incremental 3D Reassembly of Axially Symmetric Pots from Unordered and Mixed Fragment Collections
Feb 19, 2025Reassembling multiple axially symmetric pots from fragmentary sherds is crucial for cultural heritage preservation, yet it poses significant challenges due to thin and sharp fracture surfaces that generate numerous false positive matches and hinder large-scale puzzle solving. Existing global approaches, which optimize all potential fragment pairs simultaneously or data-driven models, are prone to local minima and face scalability issues when multiple pots are intermixed. Motivated by Structure-from-Motion (SfM) for 3D reconstruction from multiple images, we propose an efficient reassembly method for axially symmetric pots based on iterative registration of one sherd at a time, called Structure-from-Sherds++ (SfS++). Our method extends beyond simple replication of incremental SfM and leverages multi-graph beam search to explore multiple registration paths. This allows us to effectively filter out indistinguishable false matches and simultaneously reconstruct multiple pots without requiring prior information such as base or the number of mixed objects. Our approach achieves 87% reassembly accuracy on a dataset of 142 real fragments from 10 different pots, outperforming other methods in handling complex fracture patterns with mixed datasets and achieving state-of-the-art performance. Code and results can be found in our project page https://sj-yoo.info/sfs/.
HashEvict: A Pre-Attention KV Cache Eviction Strategy using Locality-Sensitive Hashing
Dec 24, 2024



Transformer-based large language models (LLMs) use the key-value (KV) cache to significantly accelerate inference by storing the key and value embeddings of past tokens. However, this cache consumes significant GPU memory. In this work, we introduce HashEvict, an algorithm that uses locality-sensitive hashing (LSH) to compress the KV cache. HashEvict quickly locates tokens in the cache that are cosine dissimilar to the current query token. This is achieved by computing the Hamming distance between binarized Gaussian projections of the current token query and cached token keys, with a projection length much smaller than the embedding dimension. We maintain a lightweight binary structure in GPU memory to facilitate these calculations. Unlike existing compression strategies that compute attention to determine token retention, HashEvict makes these decisions pre-attention, thereby reducing computational costs. Additionally, HashEvict is dynamic - at every decoding step, the key and value of the current token replace the embeddings of a token expected to produce the lowest attention score. We demonstrate that HashEvict can compress the KV cache by 30%-70% while maintaining high performance across reasoning, multiple-choice, long-context retrieval and summarization tasks.
Future Aspects in Human Action Recognition: Exploring Emerging Techniques and Ethical Influences
Dec 17, 2024
Visual-based human action recognition can be found in various application fields, e.g., surveillance systems, sports analytics, medical assistive technologies, or human-robot interaction frameworks, and it concerns the identification and classification of individuals' activities within a video. Since actions typically occur over a sequence of consecutive images, it is particularly challenging due to the inclusion of temporal analysis, which introduces an extra layer of complexity. However, although multiple approaches try to handle temporal analysis, there are still difficulties because of their computational cost and lack of adaptability. Therefore, different types of vision data, containing transition information between consecutive images, provided by next-generation hardware sensors will guide the robotics community in tackling the problem of human action recognition. On the other hand, while there is a plethora of still-image datasets, that researchers can adopt to train new artificial intelligence models, videos representing human activities are of limited capabilities, e.g., small and unbalanced datasets or selected without control from multiple sources. To this end, generating new and realistic synthetic videos is possible since labeling is performed throughout the data creation process, while reinforcement learning techniques can permit the avoidance of considerable dataset dependence. At the same time, human factors' involvement raises ethical issues for the research community, as doubts and concerns about new technologies already exist.