 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneOrchestra: Efficient Agentic 3D Scene Synthesis via Full Tool-Call Trajectory Generation
Apr 21, 2026Recent agentic frameworks for 3D scene synthesis have advanced realism and diversity by integrating heterogeneous generation and editing tools. These tools are organized into workflows orchestrated by an off-the-shelf LLM. Current approaches typically adopt an execute-review-reflect loop: at each step, the orchestrator executes a tool, renders intermediate results for review, and then decides on the tool and its parameters for the next step. However, this design has two key limitations. First, next-step tool selection and parameter configuration are driven by heuristic rules, which can lead to suboptimal execution flows, unnecessary tool invocations, degraded output quality, and increased runtime. Second, rendering and reviewing intermediate results after each step introduces additional latency. To address these issues, we propose SceneOrchestra, a trainable orchestration framework that optimizes the tool-call execution flow and eliminates the step-by-step review loop, improving both efficiency and output quality. SceneOrchestra consists of an orchestrator and a discriminator, which we fine-tune with a two-phase training strategy. In the first phase, the orchestrator learns context-aware tool selection and complete tool-call trajectory generation, while the discriminator is trained to assess the quality of full trajectories, enabling it to select the best trajectory from multiple candidates. In the second phase, we perform interleaved training, where the discriminator adapts to the orchestrator's evolving trajectory distribution and distills its discriminative capability back into the orchestrator. At inference, we only use the orchestrator to generate and execute full tool-call trajectories from instructions, without requiring the discriminator. Extensive experiments show that our method achieves state-of-the-art scene quality while reducing runtime compared to previous work.
AFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
Oct 01, 2025Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.
ControlTac: Force- and Position-Controlled Tactile Data Augmentation with a Single Reference Image
May 28, 2025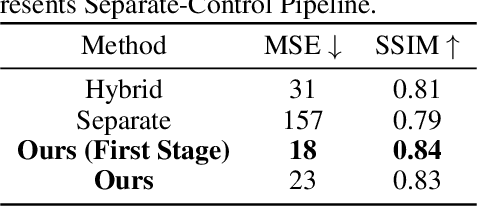
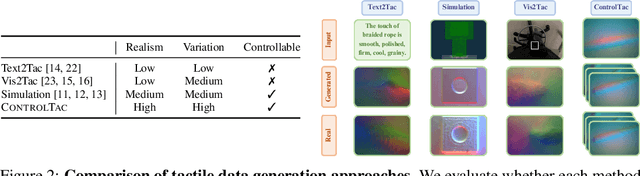
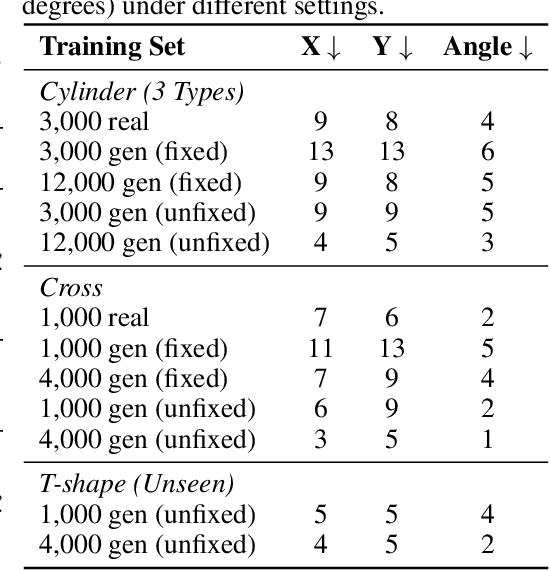
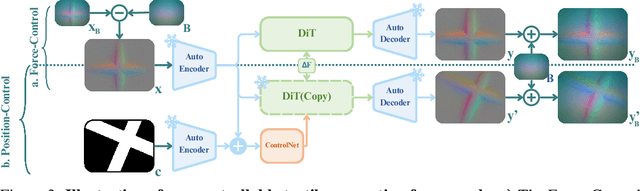
Vision-based tactile sensing has been widely used in perception, reconstruction, and robotic manipulation. However, collecting large-scale tactile data remains costly due to the localized nature of sensor-object interactions and inconsistencies across sensor instances. Existing approaches to scaling tactile data, such as simulation and free-form tactile generation, often suffer from unrealistic output and poor transferability to downstream tasks. To address this, we propose ControlTac, a two-stage controllable framework that generates realistic tactile images conditioned on a single reference tactile image, contact force, and contact position. With those physical priors as control input, ControlTac generates physically plausible and varied tactile images that can be used for effective data augmentation. Through experiments on three downstream tasks, we demonstrate that ControlTac can effectively augment tactile datasets and lead to consistent gains. Our three real-world experiments further validate the practical utility of our approach. Project page: https://dongyuluo.github.io/controltac.
MimicTouch: Learning Human's Control Strategy with Multi-Modal Tactile Feedback
Nov 01, 2023
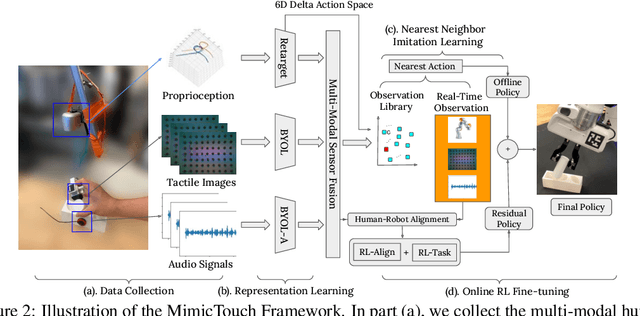

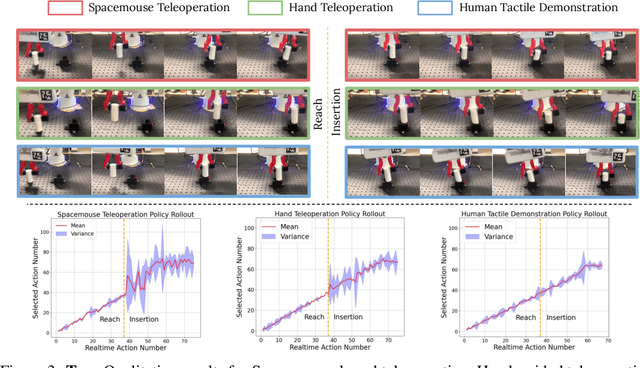
In robotics and artificial intelligence, the integration of tactile processing is becoming increasingly pivotal, especially in learning to execute intricate tasks like alignment and insertion. However, existing works focusing on tactile methods for insertion tasks predominantly rely on robot teleoperation data and reinforcement learning, which do not utilize the rich insights provided by human's control strategy guided by tactile feedback. For utilizing human sensations, methodologies related to learning from humans predominantly leverage visual feedback, often overlooking the invaluable tactile feedback that humans inherently employ to finish complex manipulations. Addressing this gap, we introduce "MimicTouch", a novel framework that mimics human's tactile-guided control strategy. In this framework, we initially collect multi-modal tactile datasets from human demonstrators, incorporating human tactile-guided control strategies for task completion. The subsequent step involves instructing robots through imitation learning using multi-modal sensor data and retargeted human motions. To further mitigate the embodiment gap between humans and robots, we employ online residual reinforcement learning on the physical robot. Through comprehensive experiments, we validate the safety of MimicTouch in transferring a latent policy learned through imitation learning from human to robot. This ongoing work will pave the way for a broader spectrum of tactile-guided robotic applications.
Evolutionary Curriculum Training for DRL-Based Navigation Systems
Jun 15, 2023



In recent years, Deep Reinforcement Learning (DRL) has emerged as a promising method for robot collision avoidance. However, such DRL models often come with limitations, such as adapting effectively to structured environments containing various pedestrians. In order to solve this difficulty, previous research has attempted a few approaches, including training an end-to-end solution by integrating a waypoint planner with DRL and developing a multimodal solution to mitigate the drawbacks of the DRL model. However, these approaches have encountered several issues, including slow training times, scalability challenges, and poor coordination among different models. To address these challenges, this paper introduces a novel approach called evolutionary curriculum training to tackle these challenges. The primary goal of evolutionary curriculum training is to evaluate the collision avoidance model's competency in various scenarios and create curricula to enhance its insufficient skills. The paper introduces an innovative evaluation technique to assess the DRL model's performance in navigating structured maps and avoiding dynamic obstacles. Additionally, an evolutionary training environment generates all the curriculum to improve the DRL model's inadequate skills tested in the previous evaluation. We benchmark the performance of our model across five structured environments to validate the hypothesis that this evolutionary training environment leads to a higher success rate and a lower average number of collisions. Further details and results at our project website.
Temporal Video-Language Alignment Network for Reward Shaping in Reinforcement Learning
Feb 08, 2023

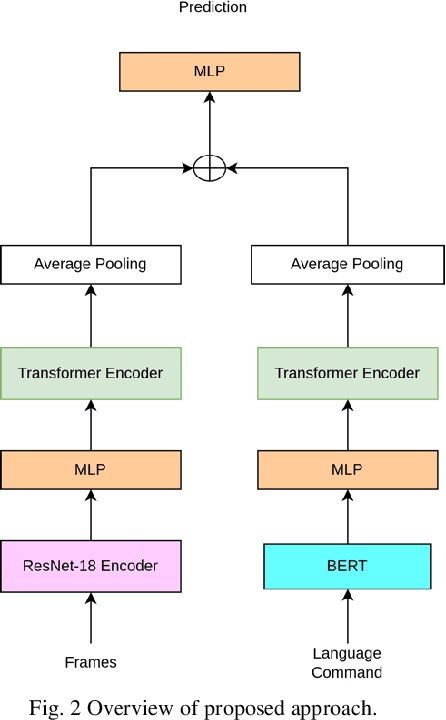
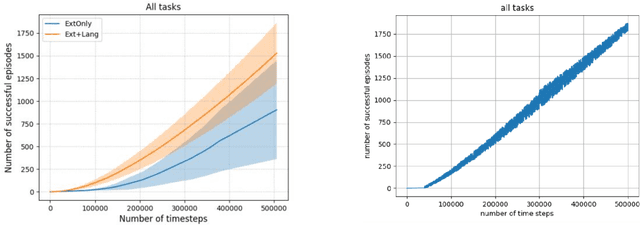
Designing appropriate reward functions for Reinforcement Learning (RL) approaches has been a significant problem, especially for complex environments such as Atari games. Utilizing natural language instructions to provide intermediate rewards to RL agents in a process known as reward shaping can help the agent in reaching the goal state faster. In this work, we propose a natural language-based reward shaping approach that maps trajectories from the Montezuma's Revenge game environment to corresponding natural language instructions using an extension of the LanguagE-Action Reward Network (LEARN) framework. These trajectory-language mappings are further used to generate intermediate rewards which are integrated into reward functions that can be utilized to learn an optimal policy for any standard RL algorithms. For a set of 15 tasks from Atari's Montezuma's Revenge game, the Ext-LEARN approach leads to the successful completion of tasks more often on average than the reward shaping approach that uses the LEARN framework and performs even better than the reward shaping framework without natural language-based rewards.