 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFINE-DP: Diffusion Policy Fine-tuning for Humanoid Loco-manipulation via Reinforcement Learning
Mar 14, 2026Humanoid loco-manipulation requires coordinated high-level motion plans with stable, low-level whole-body execution under complex robot-environment dynamics and long-horizon tasks. While diffusion policies (DPs) show promise for learning from demonstrations, deploying them on humanoids poses critical challenges: the motion planner trained offline is decoupled from the low-level controller, leading to poor command tracking, compounding distribution shift, and task failures. The common approach of scaling demonstration data is prohibitively expensive for high-dimensional humanoid systems. To address this challenge, we present REFINE-DP (REinforcement learning FINE-tuning of Diffusion Policy), a hierarchical framework that jointly optimizes a DP high-level planner and an RL-based low-level loco-manipulation controller. The DP is fine-tuned via a PPO-based diffusion policy gradient to improve task success rate, while the controller is simultaneously updated to accurately track the planner's evolving command distribution, reducing the distributional mismatch that degrades motion quality. We validate REFINE-DP on a humanoid robot performing loco-manipulation tasks, including door traversal and long-horizon object transport. REFINE-DP achieves an over $90\%$ success rate in simulation, even in out-of-distribution cases not seen in the pre-trained data, and enables smooth autonomous task execution in real-world dynamic environments. Our proposed method substantially outperforms pre-trained DP baselines and demonstrates that RL fine-tuning is key to reliable humanoid loco-manipulation. https://refine-dp.github.io/REFINE-DP/
TRANS: Terrain-aware Reinforcement Learning for Agile Navigation of Quadruped Robots under Social Interactions
Feb 13, 2026This study introduces TRANS: Terrain-aware Reinforcement learning for Agile Navigation under Social interactions, a deep reinforcement learning (DRL) framework for quadrupedal social navigation over unstructured terrains. Conventional quadrupedal navigation typically separates motion planning from locomotion control, neglecting whole-body constraints and terrain awareness. On the other hand, end-to-end methods are more integrated but require high-frequency sensing, which is often noisy and computationally costly. In addition, most existing approaches assume static environments, limiting their use in human-populated settings. To address these limitations, we propose a two-stage training framework with three DRL pipelines. (1) TRANS-Loco employs an asymmetric actor-critic (AC) model for quadrupedal locomotion, enabling traversal of uneven terrains without explicit terrain or contact observations. (2) TRANS-Nav applies a symmetric AC framework for social navigation, directly mapping transformed LiDAR data to ego-agent actions under differential-drive kinematics. (3) A unified pipeline, TRANS, integrates TRANS-Loco and TRANS-Nav, supporting terrain-aware quadrupedal navigation in uneven and socially interactive environments. Comprehensive benchmarks against locomotion and social navigation baselines demonstrate the effectiveness of TRANS. Hardware experiments further confirm its potential for sim-to-real transfer.
Adaptive Obstacle-Aware Task Assignment and Planning for Heterogeneous Robot Teaming
Oct 15, 2025Multi-Agent Task Assignment and Planning (MATP) has attracted growing attention but remains challenging in terms of scalability, spatial reasoning, and adaptability in obstacle-rich environments. To address these challenges, we propose OATH: Adaptive Obstacle-Aware Task Assignment and Planning for Heterogeneous Robot Teaming, which advances MATP by introducing a novel obstacle-aware strategy for task assignment. First, we develop an adaptive Halton sequence map, the first known application of Halton sampling with obstacle-aware adaptation in MATP, which adjusts sampling density based on obstacle distribution. Second, we propose a cluster-auction-selection framework that integrates obstacle-aware clustering with weighted auctions and intra-cluster task selection. These mechanisms jointly enable effective coordination among heterogeneous robots while maintaining scalability and near-optimal allocation performance. In addition, our framework leverages an LLM to interpret human instructions and directly guide the planner in real time. We validate OATH in NVIDIA Isaac Sim, showing substantial improvements in task assignment quality, scalability, adaptability to dynamic changes, and overall execution performance compared to state-of-the-art MATP baselines. A project website is available at https://llm-oath.github.io/.
Probabilistically-Safe Bipedal Navigation over Uncertain Terrain via Conformal Prediction and Contraction Analysis
Oct 09, 2025We address the challenge of enabling bipedal robots to traverse rough terrain by developing probabilistically safe planning and control strategies that ensure dynamic feasibility and centroidal robustness under terrain uncertainty. Specifically, we propose a high-level Model Predictive Control (MPC) navigation framework for a bipedal robot with a specified confidence level of safety that (i) enables safe traversal toward a desired goal location across a terrain map with uncertain elevations, and (ii) formally incorporates uncertainty bounds into the centroidal dynamics of locomotion control. To model the rough terrain, we employ Gaussian Process (GP) regression to estimate elevation maps and leverage Conformal Prediction (CP) to construct calibrated confidence intervals that capture the true terrain elevation. Building on this, we formulate contraction-based reachable tubes that explicitly account for terrain uncertainty, ensuring state convergence and tube invariance. In addition, we introduce a contraction-based flywheel torque control law for the reduced-order Linear Inverted Pendulum Model (LIPM), which stabilizes the angular momentum about the center-of-mass (CoM). This formulation provides both probabilistic safety and goal reachability guarantees. For a given confidence level, we establish the forward invariance of the proposed torque control law by demonstrating exponential stabilization of the actual CoM phase-space trajectory and the desired trajectory prescribed by the high-level planner. Finally, we evaluate the effectiveness of our planning framework through physics-based simulations of the Digit bipedal robot in MuJoCo.
Safe Gap-based Planning in Dynamic Settings
Sep 08, 2025This chapter extends the family of perception-informed gap-based local planners to dynamic environments. Existing perception-informed local planners that operate in dynamic environments often rely on emergent or empirical robustness for collision avoidance as opposed to performing formal analysis of dynamic obstacles. This proposed planner, dynamic gap, explicitly addresses dynamic obstacles through several steps in the planning pipeline. First, polar regions of free space known as gaps are tracked and their dynamics are estimated in order to understand how the local environment evolves over time. Then, at planning time, gaps are propagated into the future through novel gap propagation algorithms to understand what regions are feasible for passage. Lastly, pursuit guidance theory is leveraged to generate local trajectories that are provably collision-free under ideal conditions. Additionally, obstacle-centric ungap processing is performed in situations where no gaps exist to robustify the overall planning framework. A set of gap-based planners are benchmarked against a series of classical and learned motion planners in dynamic environments, and dynamic gap is shown to outperform all other baselines in all environments. Furthermore, dynamic gap is deployed on a TurtleBot2 platform in several real-world experiments to validate collision avoidance behaviors.
PreCi: Pretraining and Continual Improvement of Humanoid Locomotion via Model-Assumption-Based Regularization
Apr 14, 2025
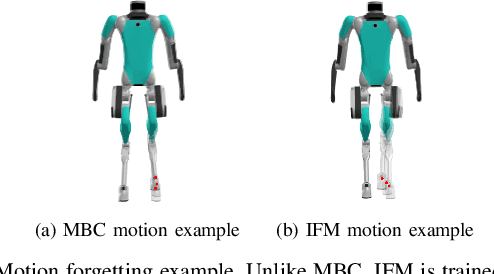
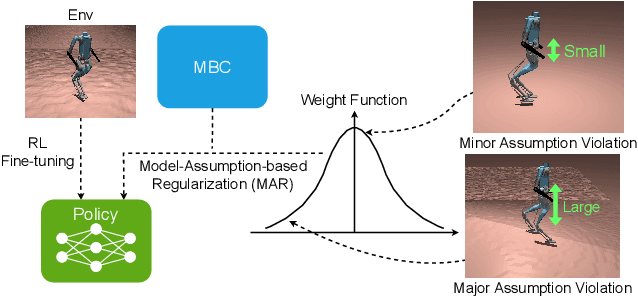

Humanoid locomotion is a challenging task due to its inherent complexity and high-dimensional dynamics, as well as the need to adapt to diverse and unpredictable environments. In this work, we introduce a novel learning framework for effectively training a humanoid locomotion policy that imitates the behavior of a model-based controller while extending its capabilities to handle more complex locomotion tasks, such as more challenging terrain and higher velocity commands. Our framework consists of three key components: pre-training through imitation of the model-based controller, fine-tuning via reinforcement learning, and model-assumption-based regularization (MAR) during fine-tuning. In particular, MAR aligns the policy with actions from the model-based controller only in states where the model assumption holds to prevent catastrophic forgetting. We evaluate the proposed framework through comprehensive simulation tests and hardware experiments on a full-size humanoid robot, Digit, demonstrating a forward speed of 1.5 m/s and robust locomotion across diverse terrains, including slippery, sloped, uneven, and sandy terrains.
EmoBipedNav: Emotion-aware Social Navigation for Bipedal Robots with Deep Reinforcement Learning
Mar 16, 2025This study presents an emotion-aware navigation framework -- EmoBipedNav -- using deep reinforcement learning (DRL) for bipedal robots walking in socially interactive environments. The inherent locomotion constraints of bipedal robots challenge their safe maneuvering capabilities in dynamic environments. When combined with the intricacies of social environments, including pedestrian interactions and social cues, such as emotions, these challenges become even more pronounced. To address these coupled problems, we propose a two-stage pipeline that considers both bipedal locomotion constraints and complex social environments. Specifically, social navigation scenarios are represented using sequential LiDAR grid maps (LGMs), from which we extract latent features, including collision regions, emotion-related discomfort zones, social interactions, and the spatio-temporal dynamics of evolving environments. The extracted features are directly mapped to the actions of reduced-order models (ROMs) through a DRL architecture. Furthermore, the proposed framework incorporates full-order dynamics and locomotion constraints during training, effectively accounting for tracking errors and restrictions of the locomotion controller while planning the trajectory with ROMs. Comprehensive experiments demonstrate that our approach exceeds both model-based planners and DRL-based baselines. The hardware videos and open-source code are available at https://gatech-lidar.github.io/emobipednav.github.io/.
Physics-informed Neural Network Predictive Control for Quadruped Locomotion
Mar 10, 2025This study introduces a unified control framework that addresses the challenge of precise quadruped locomotion with unknown payloads, named as online payload identification-based physics-informed neural network predictive control (OPI-PINNPC). By integrating online payload identification with physics-informed neural networks (PINNs), our approach embeds identified mass parameters directly into the neural network's loss function, ensuring physical consistency while adapting to changing load conditions. The physics-constrained neural representation serves as an efficient surrogate model within our nonlinear model predictive controller, enabling real-time optimization despite the complex dynamics of legged locomotion. Experimental validation on our quadruped robot platform demonstrates 35% improvement in position and orientation tracking accuracy across diverse payload conditions (25-100 kg), with substantially faster convergence compared to previous adaptive control methods. Our framework provides a adaptive solution for maintaining locomotion performance under variable payload conditions without sacrificing computational efficiency.
Physically-Feasible Reactive Synthesis for Terrain-Adaptive Locomotion via Trajectory Optimization and Symbolic Repair
Mar 05, 2025We propose an integrated planning framework for quadrupedal locomotion over dynamically changing, unforeseen terrains. Existing approaches either rely on heuristics for instantaneous foothold selection--compromising safety and versatility--or solve expensive trajectory optimization problems with complex terrain features and long time horizons. In contrast, our framework leverages reactive synthesis to generate correct-by-construction controllers at the symbolic level, and mixed-integer convex programming (MICP) for dynamic and physically feasible footstep planning for each symbolic transition. We use a high-level manager to reduce the large state space in synthesis by incorporating local environment information, improving synthesis scalability. To handle specifications that cannot be met due to dynamic infeasibility, and to minimize costly MICP solves, we leverage a symbolic repair process to generate only necessary symbolic transitions. During online execution, re-running the MICP with real-world terrain data, along with runtime symbolic repair, bridges the gap between offline synthesis and online execution. We demonstrate, in simulation, our framework's capabilities to discover missing locomotion skills and react promptly in safety-critical environments, such as scattered stepping stones and rebars.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.