 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating and Scaling MPC-Guided Reinforcement Learning for Humanoid Locomotion and Manipulation
Jun 04, 2026In humanoid motion control, model predictive control (MPC) offers physically grounded prediction and constraint handling, while reinforcement learning (RL) enables robust whole-body skills through large-scale simulation. However, using MPC inside RL often requires time-consuming problem construction or excessive training overhead, making such frameworks difficult to justify in practice. This work studies efficient training-time MPC guidance for humanoid locomotion and manipulation, termed MPC-RL. We introduce a centroidal-dynamics MPC reward formulation that leverages guidance from MPC trajectories in training time. To make this practical in massively parallel RL, we develop $π^n$MPC, a parallel-in-horizon and construction-free batched GPU MPC solver that operates directly on time-varying dynamics to avoid high memory usage and pre-compilation. Through a variety of comparative studies and hardware validations, we have found that MPC-RL achieves superior performance in locomotion and manipulation skills. The code base is available at https://github.com/junhengl/mpc-rl.
HANDOFF: Humanoid Agentic Task-Space Whole-Body Control via Distilled Complementary Teachers
Jun 04, 2026For a humanoid robot to be deployed in the real world, the choice of command space (i.e., the interface between task planning and whole-body control) is crucial. Existing whole-body controllers typically demand dense kinematic or spatial references that planners struggle to synthesize from task semantics. We instead propose a compact, explicit interface that is intuitive, general, modular, and expressive enough for diverse manipulation skills. To this end, we introduce HANDOFF, a single humanoid whole-body controller that follows this interface and is distilled via multi-teacher KL distillation under a context-conditioned gating scheme into a mixture-of-experts student from three complementary specialists: whole-body motion tracking with safety-filtered data, locomotion, and fall-recovery. On the Unitree G1, HANDOFF matches state-of-the-art velocity tracking and offers one of the largest robust manipulation workspaces. We further demonstrate hardware feasibility through multiple natural-language-driven task roll-outs, powered by a VLM-driven agentic planner with no task-specific data or controller fine-tuning.
On Surprising Effects of Risk-Aware Domain Randomization for Contact-Rich Sampling-based Predictive Control
May 05, 2026Domain randomization (DR) is widely used in policy learning to improve robustness to modeling error, but remains underexplored in contact-rich sampling-based predictive control (SPC), where rollout quality is highly sensitive to uncertainty. In this work, we take the first step by studying risk-aware DR in predictive sampling on a simple yet representative Push-T task, comparing average, optimistic, and pessimistic rollout aggregations under randomized model instances. Our initial results suggest that DR affects not only robustness to model error, but also the effective cost landscape seen by the sampling-based optimizer, by reshaping the basin of attraction around contact-producing actions. This opens up potential for exploring better grounded risk-aware contact-rich SPC under model uncertainty. Video: https://youtu.be/f1F0ALXxhSM
MIRROR: Visual Motion Imitation via Real-time Retargeting and Teleoperation with Parallel Differential Inverse Kinematics
Mar 25, 2026Real-time humanoid teleoperation requires inverse kinematics (IK) solvers that are both responsive and constraint-safe under kinematic redundancy and self-collision constraints. While differential IK enables efficient online retargeting, its locally linearized updates are inherently basin-dependent and often become trapped near joint limits, singularities, or active collision boundaries, leading to unsafe or stagnant behavior. We propose a GPU-parallelized, continuation-based differential IK that improves escape from such constraint-induced local minima while preserving real-time performance, promoting safety and stability. Multiple constrained IK quadratic programs are evaluated in parallel, together with a self-collision avoidance control barrier function (CBF), and a Lyapunov-based progression criterion selects updates that reduce the final global task-space error. The method is paired with a visual skeletal pose estimation pipeline that enables robust, real-time upper-body teleoperation on the THEMIS humanoid robot hardware in real-world tasks.
Walk the PLANC: Physics-Guided RL for Agile Humanoid Locomotion on Constrained Footholds
Jan 09, 2026Bipedal humanoid robots must precisely coordinate balance, timing, and contact decisions when locomoting on constrained footholds such as stepping stones, beams, and planks -- even minor errors can lead to catastrophic failure. Classical optimization and control pipelines handle these constraints well but depend on highly accurate mathematical representations of terrain geometry, making them prone to error when perception is noisy or incomplete. Meanwhile, reinforcement learning has shown strong resilience to disturbances and modeling errors, yet end-to-end policies rarely discover the precise foothold placement and step sequencing required for discontinuous terrain. These contrasting limitations motivate approaches that guide learning with physics-based structure rather than relying purely on reward shaping. In this work, we introduce a locomotion framework in which a reduced-order stepping planner supplies dynamically consistent motion targets that steer the RL training process via Control Lyapunov Function (CLF) rewards. This combination of structured footstep planning and data-driven adaptation produces accurate, agile, and hardware-validated stepping-stone locomotion on a humanoid robot, substantially improving reliability compared to conventional model-free reinforcement-learning baselines.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
May 29, 2025



The deployment of robot controllers is hindered by modeling discrepancies due to necessary simplifications for computational tractability or inaccuracies in data-generating simulators. Such discrepancies typically require ad-hoc tuning to meet the desired performance, thereby ensuring successful transfer to a target domain. We propose a framework for automated, gradient-based tuning to enhance performance in the deployment domain by leveraging differentiable simulators. Our method collects rollouts in an iterative manner to co-tune the simulator and controller parameters, enabling systematic transfer within a few trials in the deployment domain. Specifically, we formulate multi-step objectives for tuning and employ alternating optimization to effectively adapt the controller to the deployment domain. The scalability of our framework is demonstrated by co-tuning model-based and learning-based controllers of arbitrary complexity for tasks ranging from low-dimensional cart-pole stabilization to high-dimensional quadruped and biped tracking, showing performance improvements across different deployment domains.
Gait-Net-augmented Implicit Kino-dynamic MPC for Dynamic Variable-frequency Humanoid Locomotion over Discrete Terrains
Feb 05, 2025



Current optimization-based control techniques for humanoid locomotion struggle to adapt step duration and placement simultaneously in dynamic walking gaits due to their reliance on fixed-time discretization, which limits responsiveness to terrain conditions and results in suboptimal performance in challenging environments. In this work, we propose a Gait-Net-augmented implicit kino-dynamic model-predictive control (MPC) to simultaneously optimize step location, step duration, and contact forces for natural variable-frequency locomotion. The proposed method incorporates a Gait-Net-augmented Sequential Convex MPC algorithm to solve multi-linearly constrained variables by iterative quadratic programs. At its core, a lightweight Gait-frequency Network (Gait-Net) determines the preferred step duration in terms of variable MPC sampling times, simplifying step duration optimization to the parameter level. Additionally, it enhances and updates the spatial reference trajectory within each sequential iteration by incorporating local solutions, allowing the projection of kinematic constraints to the design of reference trajectories. We validate the proposed algorithm in high-fidelity simulations and on small-size humanoid hardware, demonstrating its capability for variable-frequency and 3-D discrete terrain locomotion with only a one-step preview of terrain data.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.
Adapting Gait Frequency for Posture-regulating Humanoid Push-recovery via Hierarchical Model Predictive Control
Sep 22, 2024Current humanoid push-recovery strategies often use whole-body motion, yet posture regulation is often overlooked. For instance, during manipulation tasks, the upper body may need to stay upright and have minimal recovery displacement. This paper introduces a novel approach to enhancing humanoid push-recovery performance under unknown disturbances and regulating body posture by tailoring the recovery stepping strategy. We propose a hierarchical-MPC-based scheme that analyzes and detects instability in the prediction window and quickly recovers through adapting gait frequency. Our approach integrates a high-level nonlinear MPC, a posture-aware gait frequency adaptation planner, and a low-level convex locomotion MPC. The planners predict the center of mass (CoM) state trajectories that can be assessed for precursors of potential instability and posture deviation. In simulation, we demonstrate improved maximum recoverable impulse by 131% on average compared with baseline approaches. In hardware experiments, a 125 ms advancement in recovery stepping timing/reflex has been observed with the proposed approach, We also demonstrate improved push-recovery performance and minimized attitude change under 0.2 rad.
Continuous Dynamic Bipedal Jumping via Adaptive-model Optimization
Apr 18, 2024
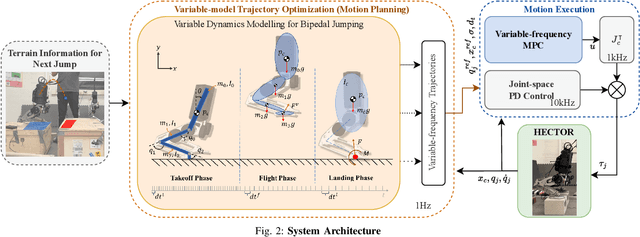
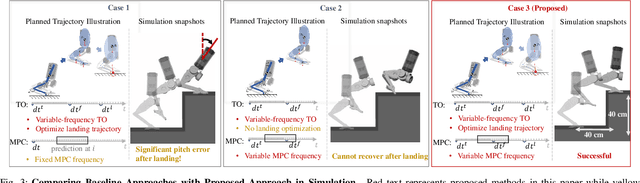
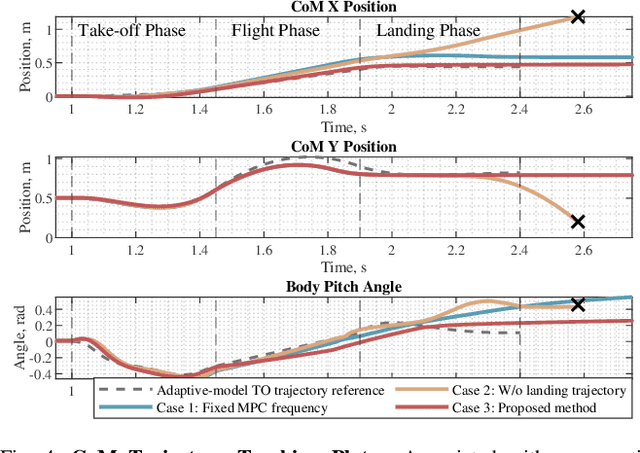
Dynamic and continuous jumping remains an open yet challenging problem in bipedal robot control. The choice of dynamic models in trajectory optimization (TO) problems plays a huge role in trajectory accuracy and computation efficiency, which normally cannot be ensured simultaneously. In this letter, we propose a novel adaptive-model optimization approach, a unified framework of Adaptive-model TO and Adaptive-frequency Model Predictive Control (MPC), to effectively realize continuous and robust jumping on HECTOR bipedal robot. The proposed Adaptive-model TO fuses adaptive-fidelity dynamics modeling of bipedal jumping motion for model fidelity necessities in different jumping phases to ensure trajectory accuracy and computation efficiency. In addition, conventional approaches have unsynchronized sampling frequencies in TO and real-time control, causing the framework to have mismatched modeling resolutions. We adapt MPC sampling frequency based on TO trajectory resolution in different phases for effective trajectory tracking. In hardware experiments, we have demonstrated robust and dynamic jumps covering a distance of up to 40 cm (57% of robot height). To verify the repeatability of this experiment, we run 53 jumping experiments and achieve 90% success rate. In continuous jumps, we demonstrate continuous bipedal jumping with terrain height perturbations (up to 5 cm) and discontinuities (up to 20 cm gap).