 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
May 29, 2025



The deployment of robot controllers is hindered by modeling discrepancies due to necessary simplifications for computational tractability or inaccuracies in data-generating simulators. Such discrepancies typically require ad-hoc tuning to meet the desired performance, thereby ensuring successful transfer to a target domain. We propose a framework for automated, gradient-based tuning to enhance performance in the deployment domain by leveraging differentiable simulators. Our method collects rollouts in an iterative manner to co-tune the simulator and controller parameters, enabling systematic transfer within a few trials in the deployment domain. Specifically, we formulate multi-step objectives for tuning and employ alternating optimization to effectively adapt the controller to the deployment domain. The scalability of our framework is demonstrated by co-tuning model-based and learning-based controllers of arbitrary complexity for tasks ranging from low-dimensional cart-pole stabilization to high-dimensional quadruped and biped tracking, showing performance improvements across different deployment domains.
Dynamic Bipedal Loco-manipulation using Oracle Guided Multi-mode Policies with Mode-transition Preference
Oct 01, 2024



Loco-manipulation calls for effective whole-body control and contact-rich interactions with the object and the environment. Existing learning-based control frameworks rely on task-specific engineered rewards, training a set of low-level skill policies and explicitly switching between them with a high-level policy or FSM, leading to quasi-static and fragile transitions between skills. In contrast, for solving highly dynamic tasks such as soccer, the robot should run towards the ball, decelerating into an optimal approach configuration to seamlessly switch to dribbling and eventually score a goal - a continuum of smooth motion. To this end, we propose to learn a single Oracle Guided Multi-mode Policy (OGMP) for mastering all the required modes and transition maneuvers to solve uni-object bipedal loco-manipulation tasks. Specifically, we design a multi-mode oracle as a closed loop state-reference generator, viewing it as a hybrid automaton with continuous reference generating dynamics and discrete mode jumps. Given such an oracle, we then train an OGMP through bounded exploration around the generated reference. Furthermore, to enforce the policy to learn the desired sequence of mode transitions, we present a novel task-agnostic mode-switching preference reward that enhances performance. The proposed approach results in successful dynamic loco-manipulation in omnidirectional soccer and box-moving tasks with a 16-DoF bipedal robot HECTOR. Supplementary video results are available at https://www.youtube.com/watch?v=gfDaRqobheg
OGMP: Oracle Guided Multimodal Policies for Agile and Versatile Robot Control
Mar 07, 2024Amidst task-specific learning-based control synthesis frameworks that achieve impressive empirical results, a unified framework that systematically constructs an optimal policy for sufficiently solving a general notion of a task is absent. Hence, we propose a theoretical framework for a task-centered control synthesis leveraging two critical ideas: 1) oracle-guided policy optimization for the non-limiting integration of sub-optimal task-based priors to guide the policy optimization and 2) task-vital multimodality to break down solving a task into executing a sequence of behavioral modes. The proposed approach results in highly agile parkour and diving on a 16-DoF dynamic bipedal robot. The obtained policy advances indefinitely on a track, performing leaps and jumps of varying lengths and heights for the parkour task. Corresponding to the dive task, the policy demonstrates front, back, and side flips from various initial heights. Finally, we introduce a novel latent mode space reachability analysis to study our policies' versatility and generalization by computing a feasible mode set function through which we certify a set of failure-free modes for our policy to perform at any given state.
Learning Multimodal Bipedal Locomotion and Implicit Transitions: A Versatile Policy Approach
Mar 10, 2023In this paper, we propose a novel framework for synthesizing a single multimodal control policy capable of generating diverse behaviors (or modes) and emergent inherent transition maneuvers for bipedal locomotion. In our method, we first learn efficient latent encodings for each behavior by training an autoencoder from a dataset of rough reference motions. These latent encodings are used as commands to train a multimodal policy through an adaptive sampling of modes and transitions to ensure consistent performance across different behaviors. We validate the policy performance in simulation for various distinct locomotion modes such as walking, leaping, jumping on a block, standing idle, and all possible combinations of inter-mode transitions. Finally, we integrate a task-based planner to rapidly generate open-loop mode plans for the trained multimodal policy to solve high-level tasks like reaching a goal position on a challenging terrain. Complex parkour-like motions by smoothly combining the discrete locomotion modes were generated in 3 min. to traverse tracks with a gap of width 0.45 m, a plateau of height 0.2 m, and a block of height 0.4 m, which are all significant compared to the dimensions of our mini-biped platform.
Linear Policies are Sufficient to Realize Robust Bipedal Walking on Challenging Terrains
Oct 05, 2021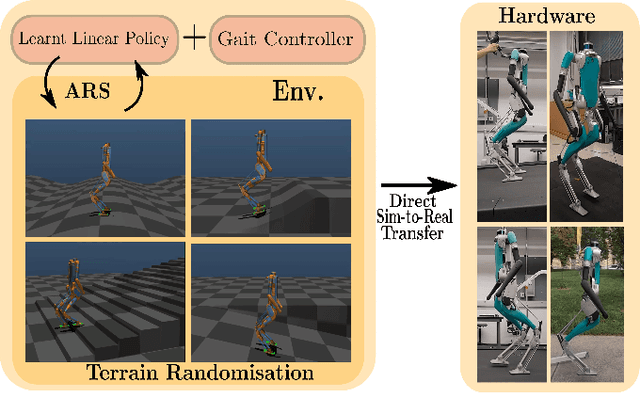
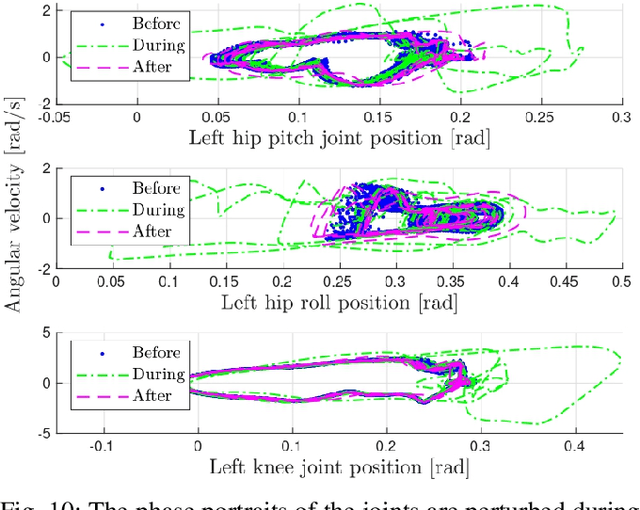
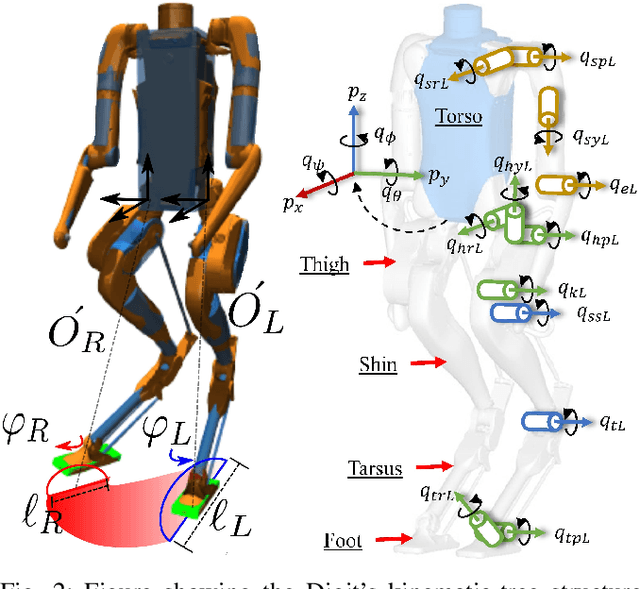
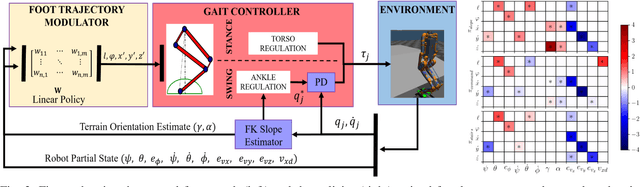
In this work, we demonstrate robust walking in the bipedal robot Digit on uneven terrains by just learning a single linear policy. In particular, we propose a new control pipeline, wherein the high-level trajectory modulator shapes the end-foot ellipsoidal trajectories, and the low-level gait controller regulates the torso and ankle orientation. The foot-trajectory modulator uses a linear policy and the regulator uses a linear PD control law. As opposed to neural network-based policies, the proposed linear policy has only 13 learnable parameters, thereby not only guaranteeing sample efficient learning but also enabling simplicity and interpretability of the policy. This is achieved with no loss of performance on challenging terrains like slopes, stairs and outdoor landscapes. We first demonstrate robust walking in the custom simulation environment, MuJoCo, and then directly transfer to hardware with no modification of the control pipeline. We subject the biped to a series of pushes and terrain height changes, both indoors and outdoors, thereby validating the presented work.
Learning Linear Policies for Robust Bipedal Locomotion on Terrains with Varying Slopes
Apr 04, 2021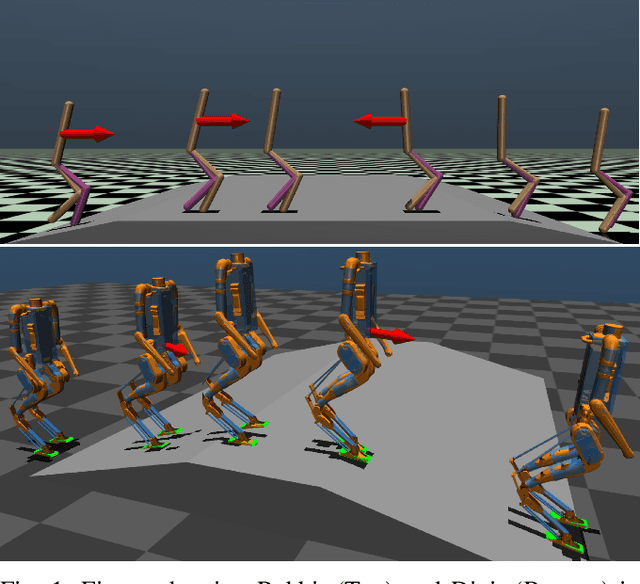
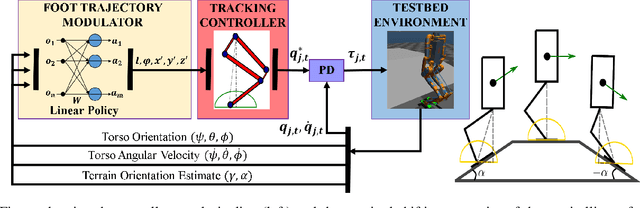
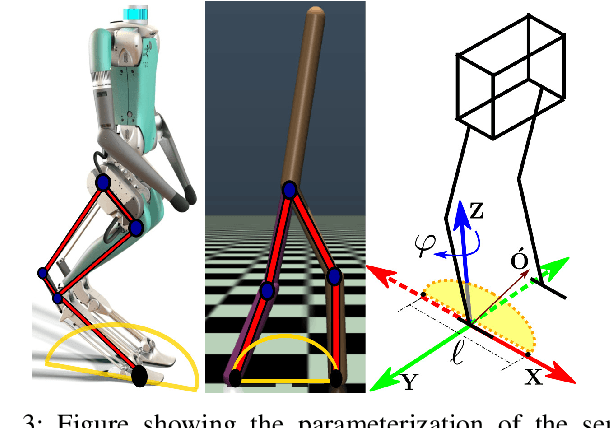
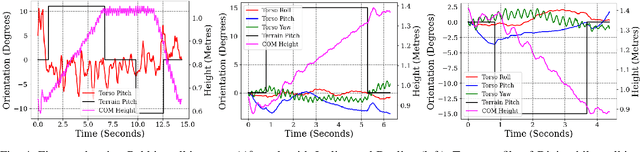
In this paper, with a view toward deployment of light-weight control frameworks for bipedal walking robots, we realize end-foot trajectories that are shaped by a single linear feedback policy. We learn this policy via a model-free and a gradient-free learning algorithm, Augmented Random Search (ARS), in the two robot platforms Rabbit and Digit. Our contributions are two-fold: a) By using torso and support plane orientation as inputs, we achieve robust walking on slopes of up to 20 degrees in simulation. b) We demonstrate additional behaviors like walking backwards, stepping-in-place, and recovery from external pushes of up to 120 N. The end result is a robust and a fast feedback control law for bipedal walking on terrains with varying slopes. Towards the end, we also provide preliminary results of hardware transfer to Digit.
Robust Quadrupedal Locomotion on Sloped Terrains: A Linear Policy Approach
Nov 10, 2020
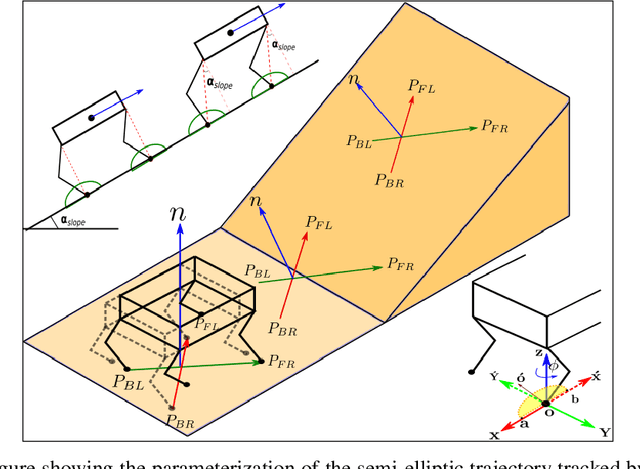
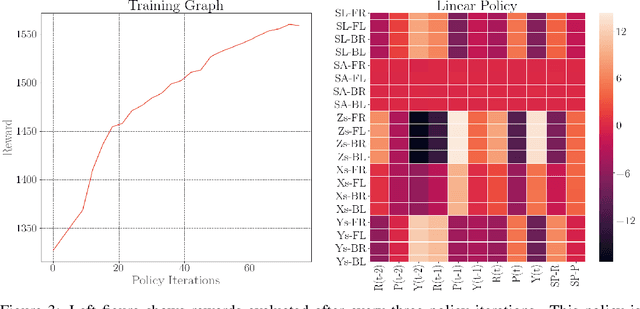
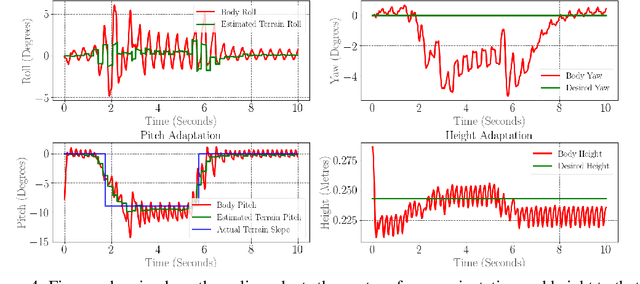
In this paper, with a view toward fast deployment of locomotion gaits in low-cost hardware, we use a linear policy for realizing end-foot trajectories in the quadruped robot, Stoch $2$. In particular, the parameters of the end-foot trajectories are shaped via a linear feedback policy that takes the torso orientation and the terrain slope as inputs. The corresponding desired joint angles are obtained via an inverse kinematics solver and tracked via a PID control law. Augmented Random Search, a model-free and a gradient-free learning algorithm is used to train this linear policy. Simulation results show that the resulting walking is robust to terrain slope variations and external pushes. This methodology is not only computationally light-weight but also uses minimal sensing and actuation capabilities in the robot, thereby justifying the approach.