 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Weighted Feature Back-Projection: A Fast Alternative to Feature Distillation in 3D Gaussian Splatting
Nov 19, 2024We introduce a training-free method for feature field rendering in Gaussian splatting. Our approach back-projects 2D features into pre-trained 3D Gaussians, using a weighted sum based on each Gaussian's influence in the final rendering. While most training-based feature field rendering methods excel at 2D segmentation but perform poorly at 3D segmentation without post-processing, our method achieves high-quality results in both 2D and 3D segmentation. Experimental results demonstrate that our approach is fast, scalable, and offers performance comparable to training-based methods.
Gradient-Driven 3D Segmentation and Affordance Transfer in Gaussian Splatting Using 2D Masks
Sep 18, 20243D Gaussian Splatting has emerged as a powerful 3D scene representation technique, capturing fine details with high efficiency. In this paper, we introduce a novel voting-based method that extends 2D segmentation models to 3D Gaussian splats. Our approach leverages masked gradients, where gradients are filtered by input 2D masks, and these gradients are used as votes to achieve accurate segmentation. As a byproduct, we discovered that inference-time gradients can also be used to prune Gaussians, resulting in up to 21% compression. Additionally, we explore few-shot affordance transfer, allowing annotations from 2D images to be effectively transferred onto 3D Gaussian splats. The robust yet straightforward mathematical formulation underlying this approach makes it a highly effective tool for numerous downstream applications, such as augmented reality (AR), object editing, and robotics. The project code and additional resources are available at https://jojijoseph.github.io/3dgs-segmentation.
Block-level Text Spotting with LLMs
Jun 19, 2024Text spotting has seen tremendous progress in recent years yielding performant techniques which can extract text at the character, word or line level. However, extracting blocks of text from images (block-level text spotting) is relatively unexplored. Blocks contain more context than individual lines, words or characters and so block-level text spotting would enhance downstream applications, such as translation, which benefit from added context. We propose a novel method, BTS-LLM (Block-level Text Spotting with LLMs), to identify text at the block level. BTS-LLM has three parts: 1) detecting and recognizing text at the line level, 2) grouping lines into blocks and 3) finding the best order of lines within a block using a large language model (LLM). We aim to exploit the strong semantic knowledge in LLMs for accurate block-level text spotting. Consequently if the text spotted is semantically meaningful but has been corrupted during text recognition, the LLM is also able to rectify mistakes in the text and produce a reconstruction of it.
CORNET 2.0: A Co-Simulation Middleware forRobot Networks
Sep 14, 2021
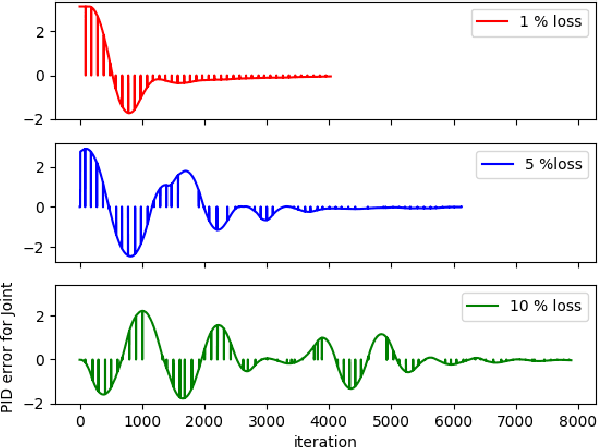
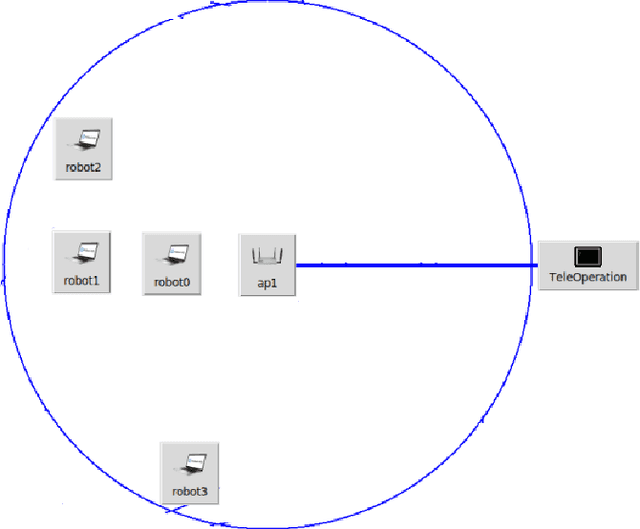

We present a networked co-simulation framework for multi-robot systems applications. We require a simulation framework that captures both physical interactions and communications aspects to effectively design such complex systems. This is necessary to co-design the multi-robots' autonomy logic and the communication protocols. The proposed framework extends existing tools to simulate the robot's autonomy and network-related aspects. We have used Gazebo with ROS/ROS2 to develop the autonomy logic for robots and mininet-WiFi as the network simulator to capture the cyber-physical systems properties of the multi-robot system. This framework addresses the need to seamlessly integrate the two simulation environments by synchronizing mobility and time, allowing for easy migration of the algorithms to real platforms.
Scene Text Detection for Augmented Reality -- Character Bigram Approach to reduce False Positive Rate
Dec 26, 2020

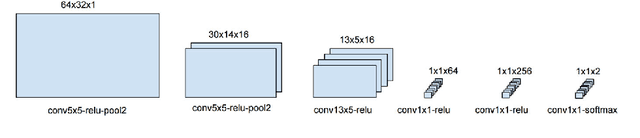

Natural scene text detection is an important aspect of scene understanding and could be a useful tool in building engaging augmented reality applications. In this work, we address the problem of false positives in text spotting. We propose improving the performace of sliding window text spotters by looking for character pairs (bigrams) rather than single characters. An efficient convolutional neural network is designed and trained to detect bigrams. The proposed detector reduces false positive rate by 28.16% on the ICDAR 2015 dataset. We demonstrate that detecting bigrams is a computationally inexpensive way to improve sliding window text spotters.
Imitation Learning for High Precision Peg-in-Hole Tasks
Dec 26, 2020
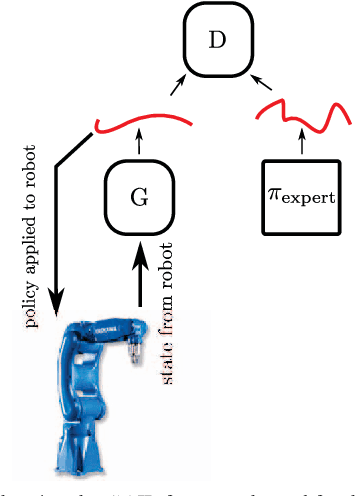
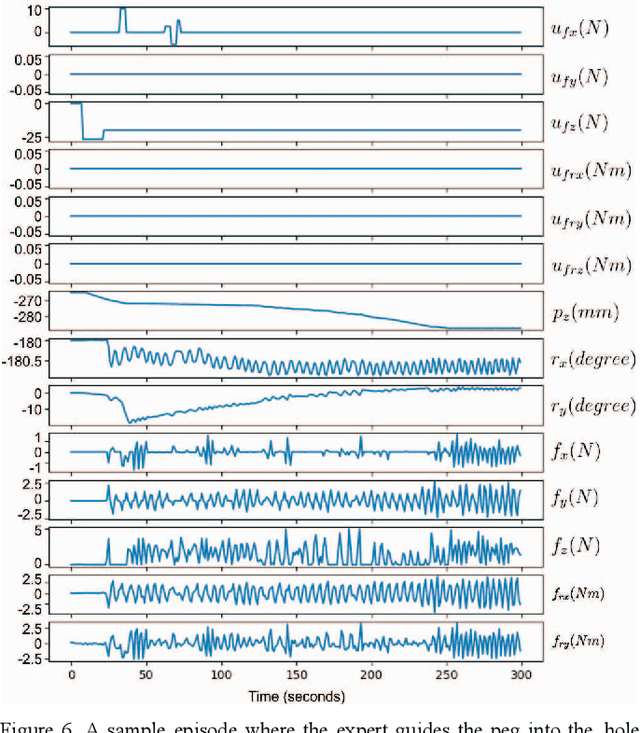
Industrial robot manipulators are not able to match the precision and speed with which humans are able to execute contact rich tasks even to this day. Therefore, as a means overcome this gap, we demonstrate generative methods for imitating a peg-in-hole insertion task in a 6-DOF robot manipulator. In particular, generative adversarial imitation learning (GAIL) is used to successfully achieve this task with a 10 um, and a 6 um peg-hole clearance on the Yaskawa GP8 industrial robot. Experimental results show that the policy successfully learns within 20 episodes from a handful of human expert demonstrations on the robot (i.e., < 10 tele-operated robot demonstrations). The insertion time improves from > 20 seconds (which also includes failed insertions) to < 15 seconds, thereby validating the effectiveness of this approach.
Multi-Instance Aware Localization for End-to-End Imitation Learning
Dec 26, 2020

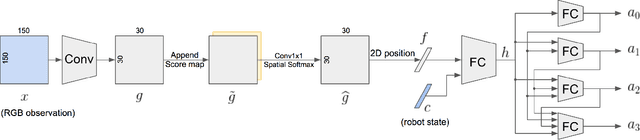
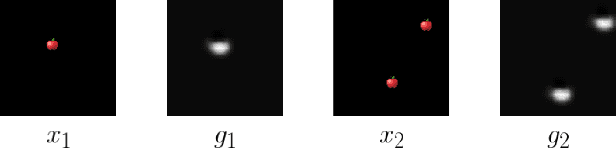
Existing architectures for imitation learning using image-to-action policy networks perform poorly when presented with an input image containing multiple instances of the object of interest, especially when the number of expert demonstrations available for training are limited. We show that end-to-end policy networks can be trained in a sample efficient manner by (a) appending the feature map output of the vision layers with an embedding that can indicate instance preference or take advantage of an implicit preference present in the expert demonstrations, and (b) employing an autoregressive action generator network for the control layers. The proposed architecture for localization has improved accuracy and sample efficiency and can generalize to the presence of more instances of objects than seen during training. When used for end-to-end imitation learning to perform reach, push, and pick-and-place tasks on a real robot, training is achieved with as few as 15 expert demonstrations.
Stochastic Action Prediction for Imitation Learning
Dec 26, 2020


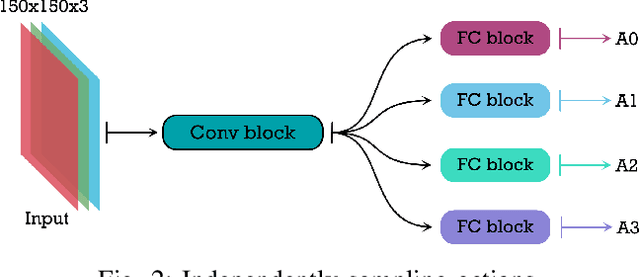
Imitation learning is a data-driven approach to acquiring skills that relies on expert demonstrations to learn a policy that maps observations to actions. When performing demonstrations, experts are not always consistent and might accomplish the same task in slightly different ways. In this paper, we demonstrate inherent stochasticity in demonstrations collected for tasks including line following with a remote-controlled car and manipulation tasks including reaching, pushing, and picking and placing an object. We model stochasticity in the data distribution using autoregressive action generation, generative adversarial nets, and variational prediction and compare the performance of these approaches. We find that accounting for stochasticity in the expert data leads to substantial improvement in the success rate of task completion.
Translating Natural Language Instructions to Computer Programs for Robot Manipulation
Dec 26, 2020
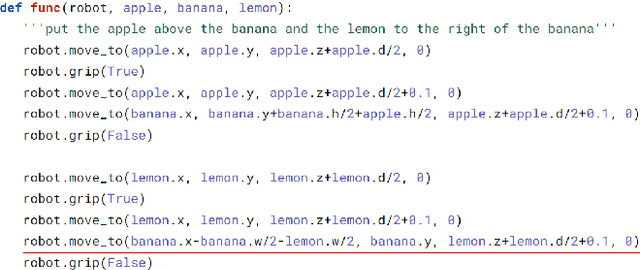


It is highly desirable for robots that work alongside humans to be able to understand instructions in natural language. Existing language conditioned imitation learning methods predict the actuator commands from the image observation and the instruction text. Rather than directly predicting actuator commands, we propose translating the natural language instruction to a Python function which when executed queries the scene by accessing the output of the object detector and controls the robot to perform the specified task. This enables the use of non-differentiable modules such as a constraint solver when computing commands to the robot. Moreover, the labels in this setup are significantly more descriptive computer programs rather than teleoperated demonstrations. We show that the proposed method performs better than training a neural network to directly predict the robot actions.
Spatial Reasoning from Natural Language Instructions for Robot Manipulation
Dec 26, 2020
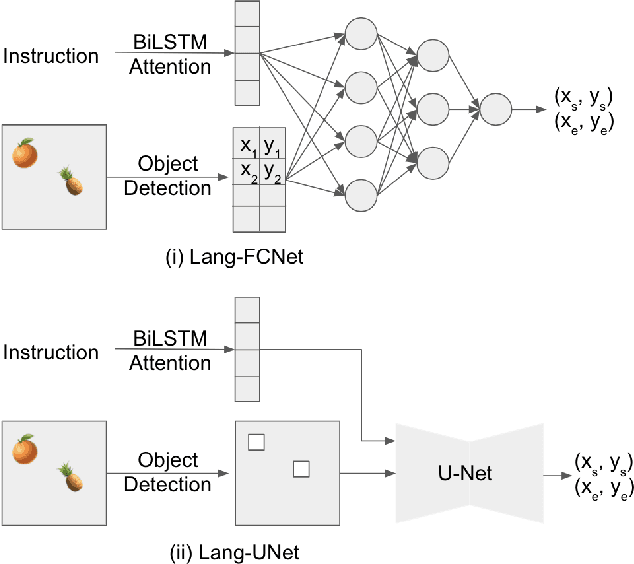
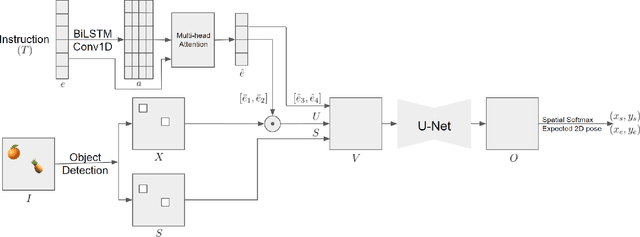
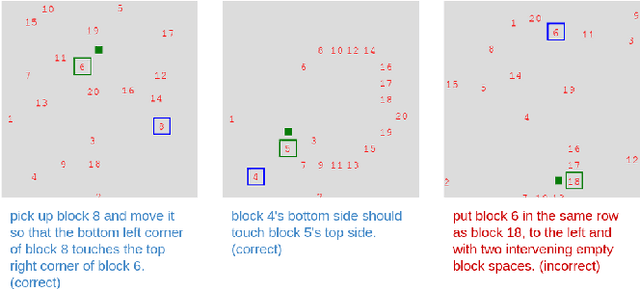
Robots that can manipulate objects in unstructured environments and collaborate with humans can benefit immensely by understanding natural language. We propose a pipelined architecture of two stages to perform spatial reasoning on the text input. All the objects in the scene are first localized, and then the instruction for the robot in natural language and the localized co-ordinates are mapped to the start and end co-ordinates corresponding to the locations where the robot must pick up and place the object respectively. We show that representing the localized objects by quantizing their positions to a binary grid is preferable to representing them as a list of 2D co-ordinates. We also show that attention improves generalization and can overcome biases in the dataset. The proposed method is used to pick-and-place playing cards using a robot arm.