 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGIF: UI Grounded Instruction Following
Nov 14, 2022



New smartphone users have difficulty engaging with it and often use only a limited set of features like calling and messaging. These users are hesitant to explore using the smartphone and rely on experienced users to teach them how to use the phone. However, experienced users are not always around to guide them. To help new users learn how to use the phone on their own, we propose a natural language based instruction following agent that operates over the UI and shows the user how to perform various tasks. Common how-to questions, such as "How to block calls from unknown numbers?", are documented on support sites with a sequence of steps in natural language describing what the user should do. We parse these steps using Large Language Models (LLMs) and generate macros that can be executed on-device when the user asks a query. To evaluate this agent, we introduce UGIF-DataSet, a multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone. It contains 523 natural language instructions with paired sequences of multilingual UI screens and actions that show how to execute the task in eight languages. We compare the performance of different large language models including PaLM, GPT3, etc. and find that the end-to-end task completion success rate is 48% for English UI but the performance drops to 32% for non-English languages. We analyse the common failure modes of existing models on this task and point out areas for improvement.
Multi-Instance Aware Localization for End-to-End Imitation Learning
Dec 26, 2020

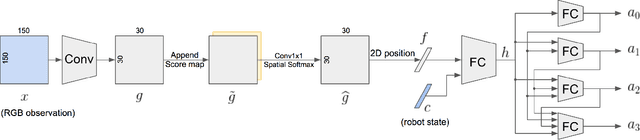
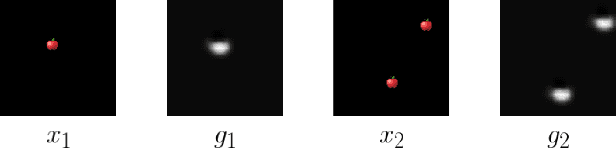
Existing architectures for imitation learning using image-to-action policy networks perform poorly when presented with an input image containing multiple instances of the object of interest, especially when the number of expert demonstrations available for training are limited. We show that end-to-end policy networks can be trained in a sample efficient manner by (a) appending the feature map output of the vision layers with an embedding that can indicate instance preference or take advantage of an implicit preference present in the expert demonstrations, and (b) employing an autoregressive action generator network for the control layers. The proposed architecture for localization has improved accuracy and sample efficiency and can generalize to the presence of more instances of objects than seen during training. When used for end-to-end imitation learning to perform reach, push, and pick-and-place tasks on a real robot, training is achieved with as few as 15 expert demonstrations.
Stochastic Action Prediction for Imitation Learning
Dec 26, 2020


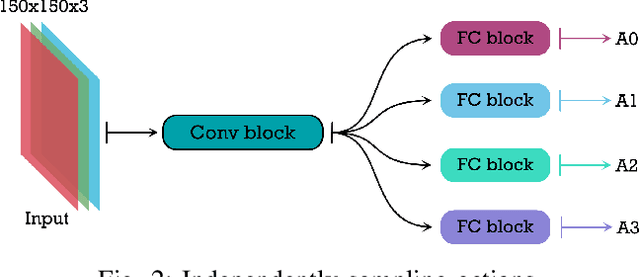
Imitation learning is a data-driven approach to acquiring skills that relies on expert demonstrations to learn a policy that maps observations to actions. When performing demonstrations, experts are not always consistent and might accomplish the same task in slightly different ways. In this paper, we demonstrate inherent stochasticity in demonstrations collected for tasks including line following with a remote-controlled car and manipulation tasks including reaching, pushing, and picking and placing an object. We model stochasticity in the data distribution using autoregressive action generation, generative adversarial nets, and variational prediction and compare the performance of these approaches. We find that accounting for stochasticity in the expert data leads to substantial improvement in the success rate of task completion.
Translating Natural Language Instructions to Computer Programs for Robot Manipulation
Dec 26, 2020
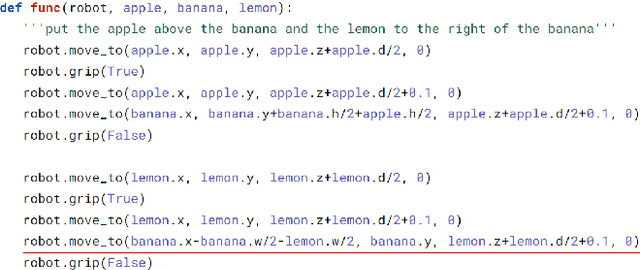


It is highly desirable for robots that work alongside humans to be able to understand instructions in natural language. Existing language conditioned imitation learning methods predict the actuator commands from the image observation and the instruction text. Rather than directly predicting actuator commands, we propose translating the natural language instruction to a Python function which when executed queries the scene by accessing the output of the object detector and controls the robot to perform the specified task. This enables the use of non-differentiable modules such as a constraint solver when computing commands to the robot. Moreover, the labels in this setup are significantly more descriptive computer programs rather than teleoperated demonstrations. We show that the proposed method performs better than training a neural network to directly predict the robot actions.
Spatial Reasoning from Natural Language Instructions for Robot Manipulation
Dec 26, 2020
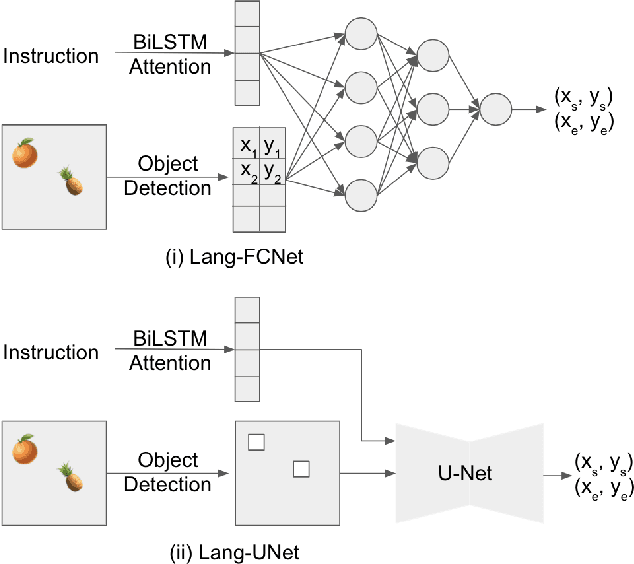
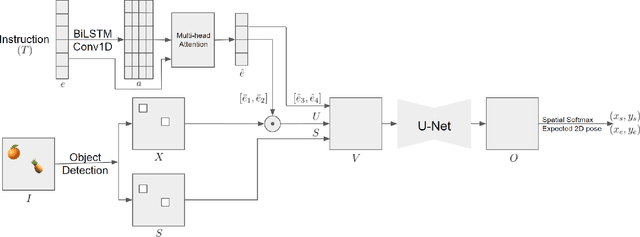
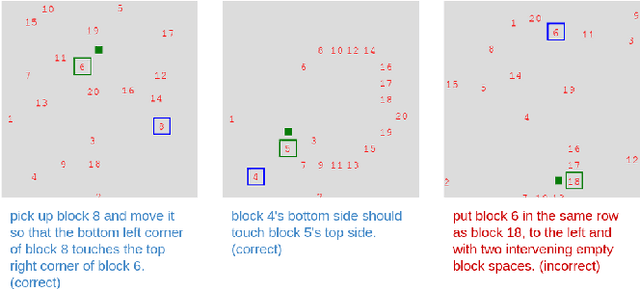
Robots that can manipulate objects in unstructured environments and collaborate with humans can benefit immensely by understanding natural language. We propose a pipelined architecture of two stages to perform spatial reasoning on the text input. All the objects in the scene are first localized, and then the instruction for the robot in natural language and the localized co-ordinates are mapped to the start and end co-ordinates corresponding to the locations where the robot must pick up and place the object respectively. We show that representing the localized objects by quantizing their positions to a binary grid is preferable to representing them as a list of 2D co-ordinates. We also show that attention improves generalization and can overcome biases in the dataset. The proposed method is used to pick-and-place playing cards using a robot arm.
One-Shot Object Localization Using Learnt Visual Cues via Siamese Networks
Dec 26, 2020



A robot that can operate in novel and unstructured environments must be capable of recognizing new, previously unseen, objects. In this work, a visual cue is used to specify a novel object of interest which must be localized in new environments. An end-to-end neural network equipped with a Siamese network is used to learn the cue, infer the object of interest, and then to localize it in new environments. We show that a simulated robot can pick-and-place novel objects pointed to by a laser pointer. We also evaluate the performance of the proposed approach on a dataset derived from the Omniglot handwritten character dataset and on a small dataset of toys.
Teaching Robots Novel Objects by Pointing at Them
Dec 25, 2020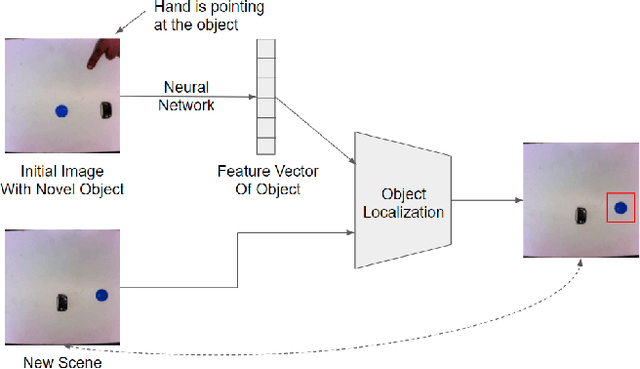


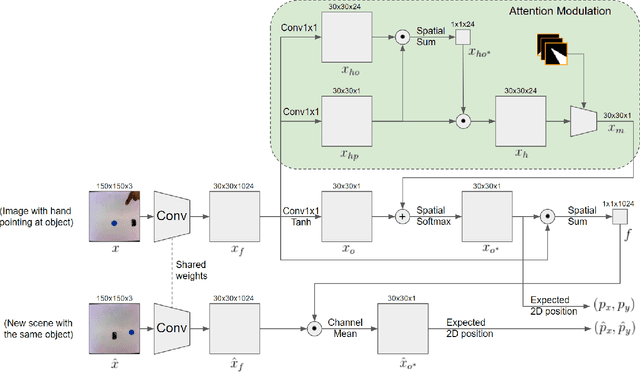
Robots that must operate in novel environments and collaborate with humans must be capable of acquiring new knowledge from human experts during operation. We propose teaching a robot novel objects it has not encountered before by pointing a hand at the new object of interest. An end-to-end neural network is used to attend to the novel object of interest indicated by the pointing hand and then to localize the object in new scenes. In order to attend to the novel object indicated by the pointing hand, we propose a spatial attention modulation mechanism that learns to focus on the highlighted object while ignoring the other objects in the scene. We show that a robot arm can manipulate novel objects that are highlighted by pointing a hand at them. We also evaluate the performance of the proposed architecture on a synthetic dataset constructed using emojis and on a real-world dataset of common objects.