 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reasoning from Natural Language Instructions for Robot Manipulation
Dec 26, 2020
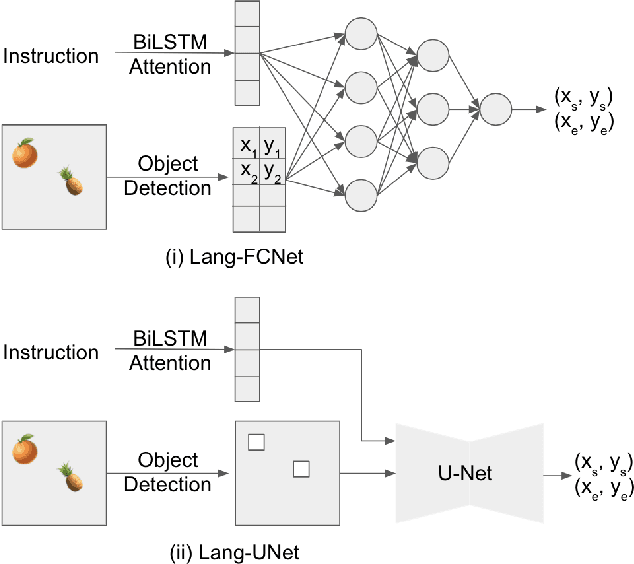
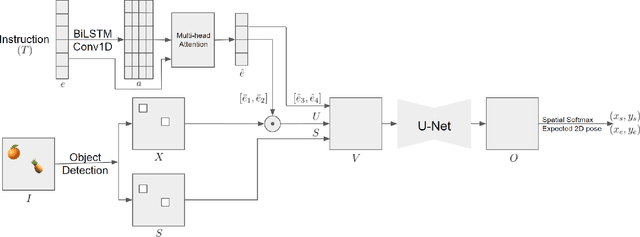
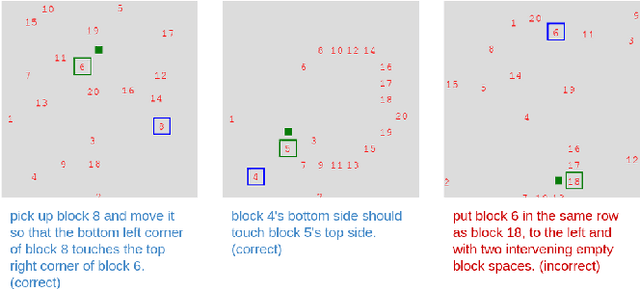
Robots that can manipulate objects in unstructured environments and collaborate with humans can benefit immensely by understanding natural language. We propose a pipelined architecture of two stages to perform spatial reasoning on the text input. All the objects in the scene are first localized, and then the instruction for the robot in natural language and the localized co-ordinates are mapped to the start and end co-ordinates corresponding to the locations where the robot must pick up and place the object respectively. We show that representing the localized objects by quantizing their positions to a binary grid is preferable to representing them as a list of 2D co-ordinates. We also show that attention improves generalization and can overcome biases in the dataset. The proposed method is used to pick-and-place playing cards using a robot arm.