 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Arms: Open-Source Arms, Hands & Control
May 20, 2022

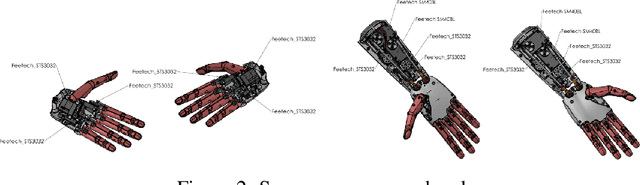
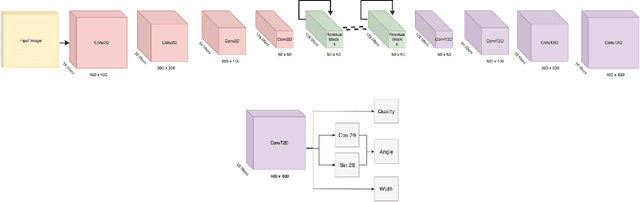
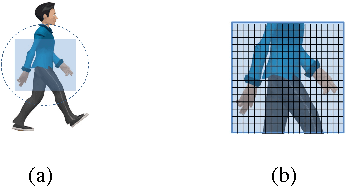
Open Arms is a novel open-source platform of realistic human-like robotic hands and arms hardware with 28 Degree-of-Freedom (DoF), designed to extend the capabilities and accessibility of humanoid robotic grasping and manipulation. The Open Arms framework includes an open SDK and development environment, simulation tools, and application development tools to build and operate Open Arms. This paper describes these hands controls, sensing, mechanisms, aesthetic design, and manufacturing and their real-world applications with a teleoperated nursing robot. From 2015 to 2022, we have designed and established the manufacturing of Open Arms as a low-cost, high functionality robotic arms hardware and software framework to serve both humanoid robot applications and the urgent demand for low-cost prosthetics. Using the techniques of consumer product manufacturing, we set out to define modular, low-cost techniques for approximating the dexterity and sensitivity of human hands. To demonstrate the dexterity and control of our hands, we present a novel Generative Grasping Residual CNN (GGR-CNN) model that can generate robust antipodal grasps from input images of various objects at real-time speeds (22ms). We achieved state-of-the-art accuracy of 92.4% using our model architecture on a standard Cornell Grasping Dataset, which contains a diverse set of household objects.
Multi-Instance Aware Localization for End-to-End Imitation Learning
Dec 26, 2020

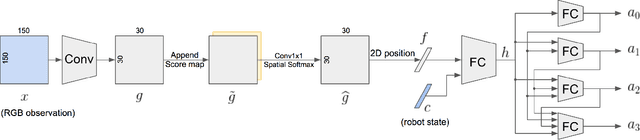
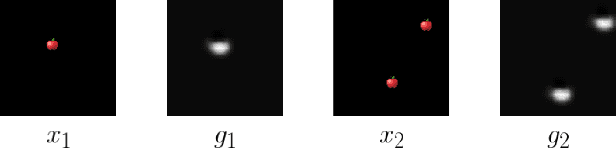
Existing architectures for imitation learning using image-to-action policy networks perform poorly when presented with an input image containing multiple instances of the object of interest, especially when the number of expert demonstrations available for training are limited. We show that end-to-end policy networks can be trained in a sample efficient manner by (a) appending the feature map output of the vision layers with an embedding that can indicate instance preference or take advantage of an implicit preference present in the expert demonstrations, and (b) employing an autoregressive action generator network for the control layers. The proposed architecture for localization has improved accuracy and sample efficiency and can generalize to the presence of more instances of objects than seen during training. When used for end-to-end imitation learning to perform reach, push, and pick-and-place tasks on a real robot, training is achieved with as few as 15 expert demonstrations.
Translating Natural Language Instructions to Computer Programs for Robot Manipulation
Dec 26, 2020
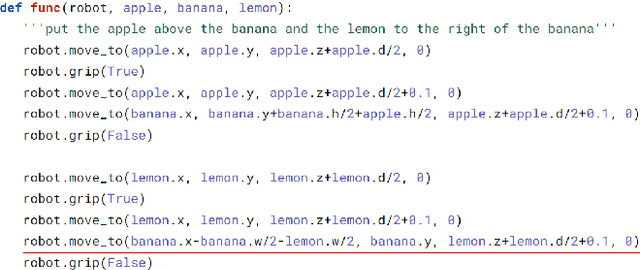


It is highly desirable for robots that work alongside humans to be able to understand instructions in natural language. Existing language conditioned imitation learning methods predict the actuator commands from the image observation and the instruction text. Rather than directly predicting actuator commands, we propose translating the natural language instruction to a Python function which when executed queries the scene by accessing the output of the object detector and controls the robot to perform the specified task. This enables the use of non-differentiable modules such as a constraint solver when computing commands to the robot. Moreover, the labels in this setup are significantly more descriptive computer programs rather than teleoperated demonstrations. We show that the proposed method performs better than training a neural network to directly predict the robot actions.
Spatial Reasoning from Natural Language Instructions for Robot Manipulation
Dec 26, 2020
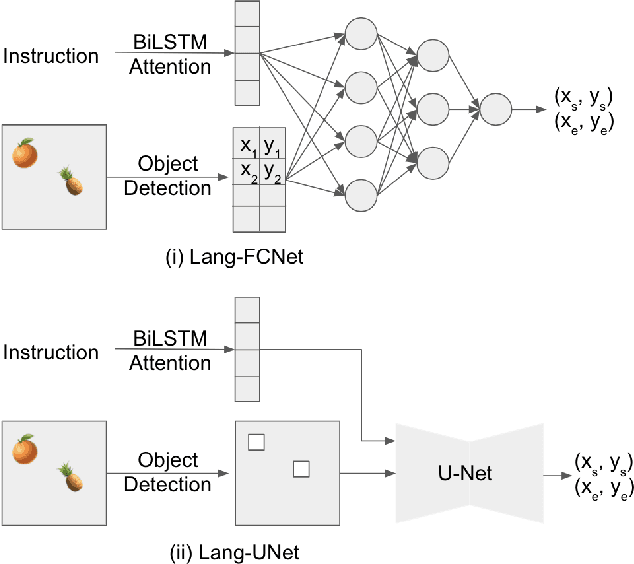
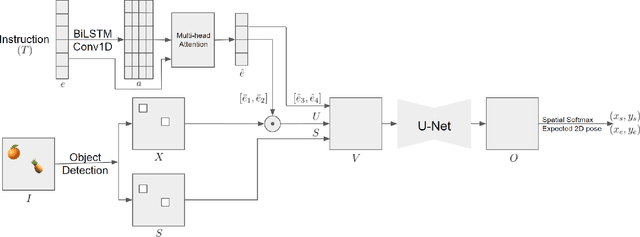
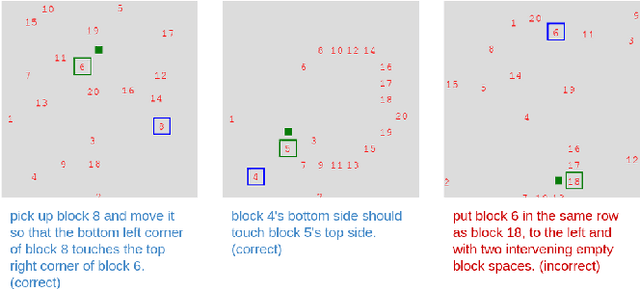
Robots that can manipulate objects in unstructured environments and collaborate with humans can benefit immensely by understanding natural language. We propose a pipelined architecture of two stages to perform spatial reasoning on the text input. All the objects in the scene are first localized, and then the instruction for the robot in natural language and the localized co-ordinates are mapped to the start and end co-ordinates corresponding to the locations where the robot must pick up and place the object respectively. We show that representing the localized objects by quantizing their positions to a binary grid is preferable to representing them as a list of 2D co-ordinates. We also show that attention improves generalization and can overcome biases in the dataset. The proposed method is used to pick-and-place playing cards using a robot arm.
Teaching Robots Novel Objects by Pointing at Them
Dec 25, 2020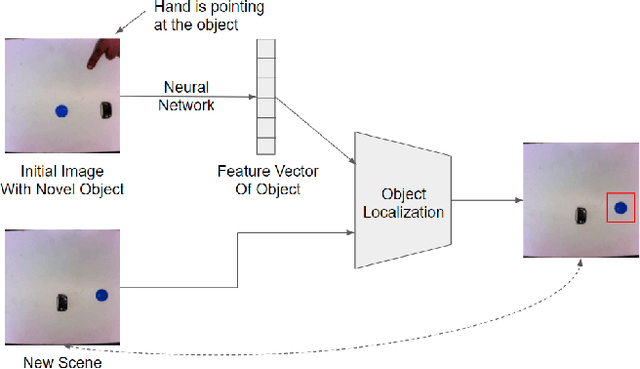


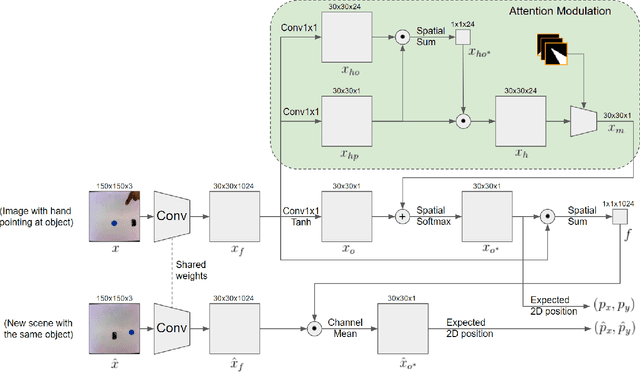
Robots that must operate in novel environments and collaborate with humans must be capable of acquiring new knowledge from human experts during operation. We propose teaching a robot novel objects it has not encountered before by pointing a hand at the new object of interest. An end-to-end neural network is used to attend to the novel object of interest indicated by the pointing hand and then to localize the object in new scenes. In order to attend to the novel object indicated by the pointing hand, we propose a spatial attention modulation mechanism that learns to focus on the highlighted object while ignoring the other objects in the scene. We show that a robot arm can manipulate novel objects that are highlighted by pointing a hand at them. We also evaluate the performance of the proposed architecture on a synthetic dataset constructed using emojis and on a real-world dataset of common objects.
Animation and Chirplet-Based Development of a PIR Sensor Array for Intruder Classification in an Outdoor Environment
Apr 13, 2016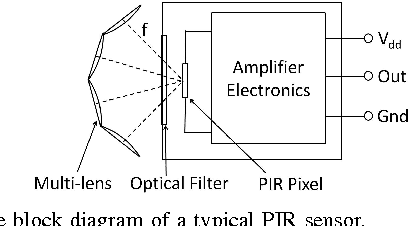
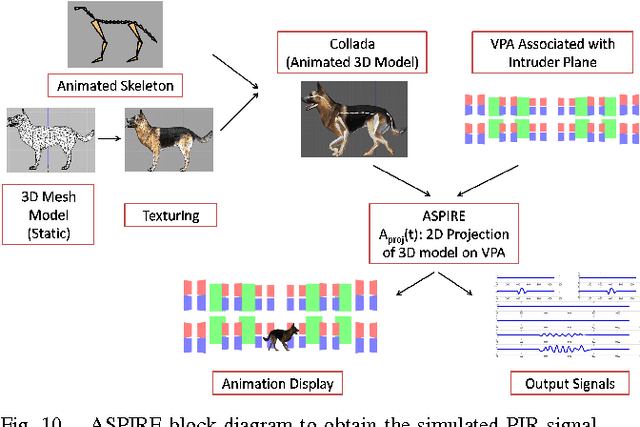
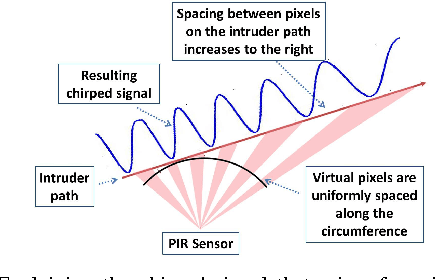
This paper presents the development of a passive infra-red sensor tower platform along with a classification algorithm to distinguish between human intrusion, animal intrusion and clutter arising from wind-blown vegetative movement in an outdoor environment. The research was aimed at exploring the potential use of wireless sensor networks as an early-warning system to help mitigate human-wildlife conflicts occurring at the edge of a forest. There are three important features to the development. Firstly, the sensor platform employs multiple sensors arranged in the form of a two-dimensional array to give it a key spatial-resolution capability that aids in classification. Secondly, given the challenges of collecting data involving animal intrusion, an Animation-based Simulation tool for Passive Infra-Red sEnsor (ASPIRE) was developed that simulates signals corresponding to human and animal intrusion and some limited models of vegetative clutter. This speeded up the process of algorithm development by allowing us to test different hypotheses in a time-efficient manner. Finally, a chirplet-based model for intruder signal was developed that significantly helped boost classification accuracy despite drawing data from a smaller number of sensors. An SVM-based classifier was used which made use of chirplet, energy and signal cross-correlation-based features. The average accuracy obtained for intruder detection and classification on real-world and simulated data sets was in excess of 97%.