 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeMaScore : a new evaluation metric for automatic speech recognition tasks
Jan 15, 2024In this study, we present SeMaScore, generated using a segment-wise mapping and scoring algorithm that serves as an evaluation metric for automatic speech recognition tasks. SeMaScore leverages both the error rate and a more robust similarity score. We show that our algorithm's score generation improves upon the state-of-the-art BERTscore. Our experimental results show that SeMaScore corresponds well with expert human assessments, signal-to-noise ratio levels, and other natural language metrics. We outperform BERTscore by 41x in metric computation speed. Overall, we demonstrate that SeMaScore serves as a more dependable evaluation metric, particularly in real-world situations involving atypical speech patterns.
PUF Probe: A PUF-based Hardware Authentication Equipment for IEDs
Jul 28, 2023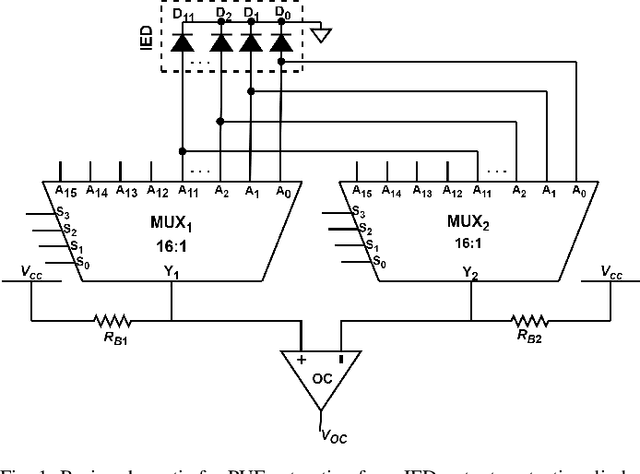
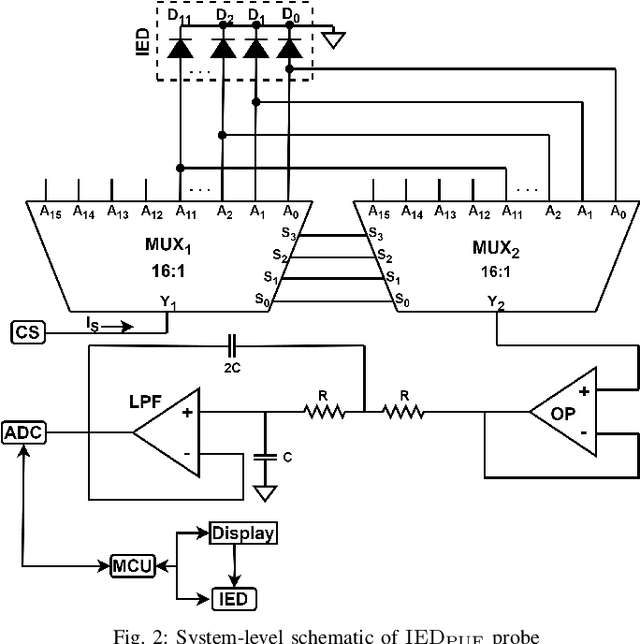
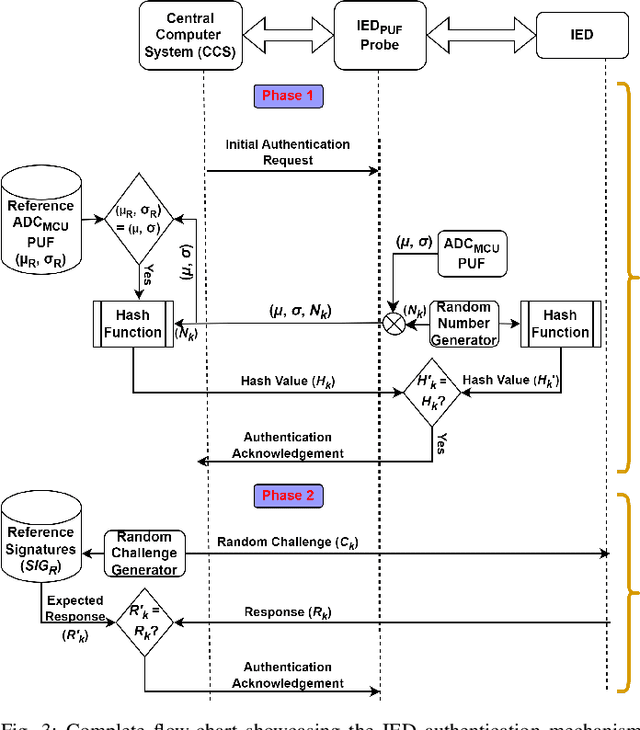
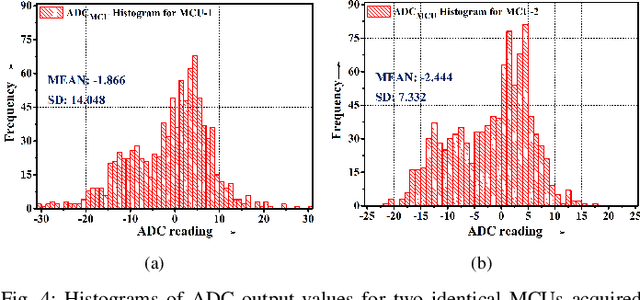
Intelligent Electronic Devices (IEDs) are vital components in modern electrical substations, collectively responsible for monitoring electrical parameters and performing protective functions. As a result, ensuring the integrity of IEDs is an essential criteria. While standards like IEC 61850 and IEC 60870-5-104 establish cyber-security protocols for secure information exchange in IED-based power systems, the physical integrity of IEDs is often overlooked, leading to a rise in counterfeit and tainted electronic products. This paper proposes a physical unclonable function (PUF)-based device (IEDPUF probe) capable of extracting unique hardware signatures from commercial IEDs. These signatures can serve as identifiers, facilitating the authentication and protection of IEDs against counterfeiting. The paper presents the complete hardware architecture of the IEDPUF probe, along with algorithms for signature extraction and authentication. The process involves the central computer system (CCS) initiating IED authentication requests by sending random challenges to the IEDPUF probe. Based on the challenges, the IEDPUF probe generates responses, which are then verified by the CCS to authenticate the IED. Additionally, a two-way authentication technique is employed to ensure that only verified requests are granted access for signature extraction. Experimental results confirm the efficacy of the proposed IEDPUF probe. The results demonstrate its ability to provide real-time responses possessing randomness while uniquely identifying the IED under investigation. The proposed IEDPUF probe offers a simple, cost-effective, accurate solution with minimal storage requirements, enhancing the authenticity and integrity of IEDs within electrical substations
Ed-Fed: A generic federated learning framework with resource-aware client selection for edge devices
Jul 14, 2023Federated learning (FL) has evolved as a prominent method for edge devices to cooperatively create a unified prediction model while securing their sensitive training data local to the device. Despite the existence of numerous research frameworks for simulating FL algorithms, they do not facilitate comprehensive deployment for automatic speech recognition tasks on heterogeneous edge devices. This is where Ed-Fed, a comprehensive and generic FL framework, comes in as a foundation for future practical FL system research. We also propose a novel resource-aware client selection algorithm to optimise the waiting time in the FL settings. We show that our approach can handle the straggler devices and dynamically set the training time for the selected devices in a round. Our evaluation has shown that the proposed approach significantly optimises waiting time in FL compared to conventional random client selection methods.
MobileASR: A resource-aware on-device personalisation framework for automatic speech recognition in mobile phones
Jun 15, 2023We describe a comprehensive methodology for developing user-voice personalised ASR models by effectively training models on mobile phones, allowing user data and models to be stored and used locally. To achieve this, we propose a resource-aware sub-model based training approach that considers the RAM, and battery capabilities of mobile phones. We also investigate the relationship between available resources and training time, highlighting the effectiveness of using sub-models in such scenarios. By taking into account the evaluation metric and battery constraints of the mobile phones, we are able to perform efficient training and halt the process accordingly. To simulate real users, we use speakers with various accents. The entire on-device training and evaluation framework was then tested on various mobile phones across brands. We show that fine-tuning the models and selecting the right hyperparameter values is a trade-off between the lowest achievable performance metric, on-device training time, and memory consumption. Overall, our methodology offers a comprehensive solution for developing personalized ASR models while leveraging the capabilities of mobile phones, and balancing the need for accuracy with resource constraints.
PreMa: Predictive Maintenance of Solenoid Valve in Real-Time at Embedded Edge-Level
Nov 21, 2022In industrial process automation, sensors (pressure, temperature, etc.), controllers, and actuators (solenoid valves, electro-mechanical relays, circuit breakers, motors, etc.) make sure that production lines are working under the pre-defined conditions. When these systems malfunction or sometimes completely fail, alerts have to be generated in real-time to make sure not only production quality is not compromised but also safety of humans and equipment is assured. In this work, we describe the construction of a smart and real-time edge-based electronic product called PreMa, which is basically a sensor for monitoring the health of a Solenoid Valve (SV). PreMa is compact, low power, easy to install, and cost effective. It has data fidelity and measurement accuracy comparable to signals captured using high end equipment. The smart solenoid sensor runs TinyML, a compact version of TensorFlow (a.k.a. TFLite) machine learning framework. While fault detection inferencing is in-situ, model training uses mobile phones to accomplish the `on-device' training. Our product evaluation shows that the sensor is able to differentiate between the distinct types of faults. These faults include: (a) Spool stuck (b) Spring failure and (c) Under voltage. Furthermore, the product provides maintenance personnel, the remaining useful life (RUL) of the SV. The RUL provides assistance to decide valve replacement or otherwise. We perform an extensive evaluation on optimizing metrics related to performance of the entire system (i.e. embedded platform and the neural network model). The proposed implementation is such that, given any electro-mechanical actuator with similar transient response to that of the SV, the system is capable of condition monitoring, hence presenting a first of its kind generic infrastructure.
Hybrid-SD : A new hybrid evaluation metric for automatic speech recognition tasks
Nov 09, 2022Many studies have examined the shortcomings of word error rate (WER) as an evaluation metric for automatic speech recognition (ASR) systems, particularly when used for spoken language understanding tasks such as intent recognition and dialogue systems. In this paper, we propose Hybrid-SD (H_SD), a new hybrid evaluation metric for ASR systems that takes into account both semantic correctness and error rate. To generate sentence dissimilarity scores (SD), we built a fast and lightweight SNanoBERT model using distillation techniques. Our experiments show that the SNanoBERT model is 25.9x smaller and 38.8x faster than SRoBERTa while achieving comparable results on well-known benchmarks. Hence, making it suitable for deploying with ASR models on edge devices. We also show that H_SD correlates more strongly with downstream tasks such as intent recognition and named-entity recognition (NER).
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021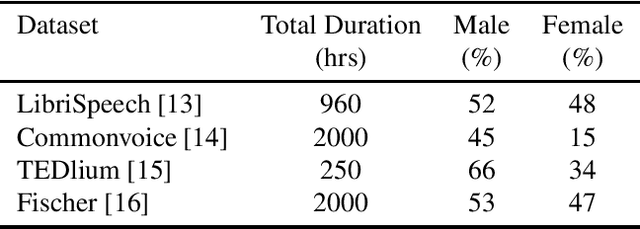
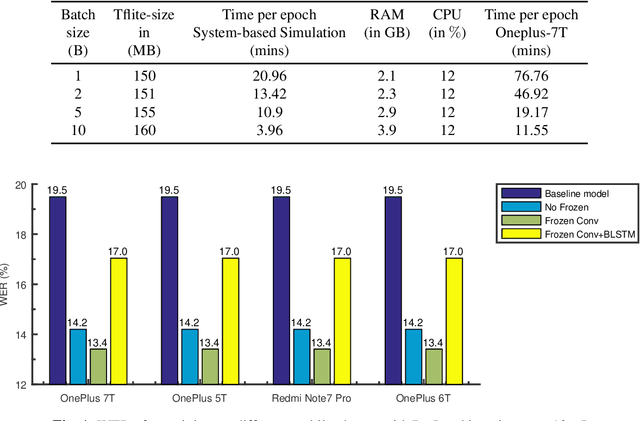
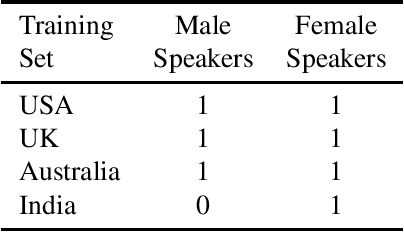
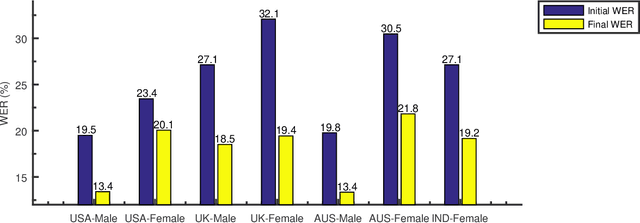
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.
PUTWorkbench: Analysing Privacy in AI-intensive Systems
Feb 05, 2019

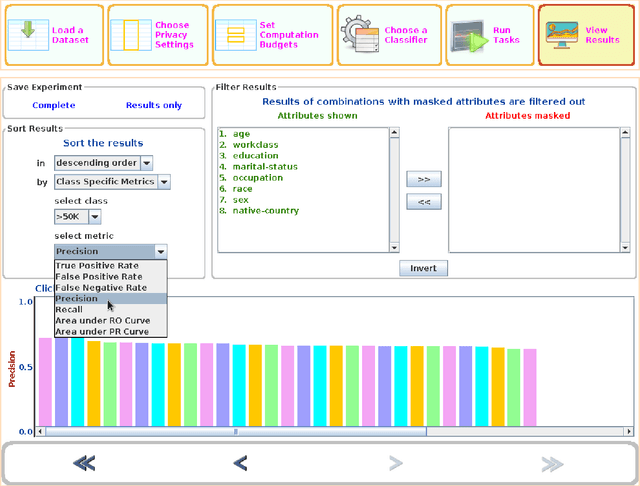

AI intensive systems that operate upon user data face the challenge of balancing data utility with privacy concerns. We propose the idea and present the prototype of an open-source tool called Privacy Utility Trade-off (PUT) Workbench which seeks to aid software practitioners to take such crucial decisions. We pick a simple privacy model that doesn't require any background knowledge in Data Science and show how even that can achieve significant results over standard and real-life datasets. The tool and the source code is made freely available for extensions and usage.
Animation and Chirplet-Based Development of a PIR Sensor Array for Intruder Classification in an Outdoor Environment
Apr 13, 2016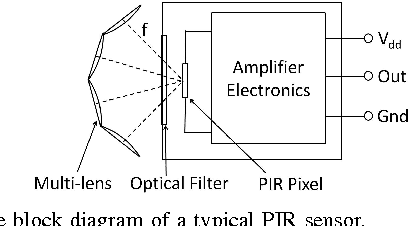
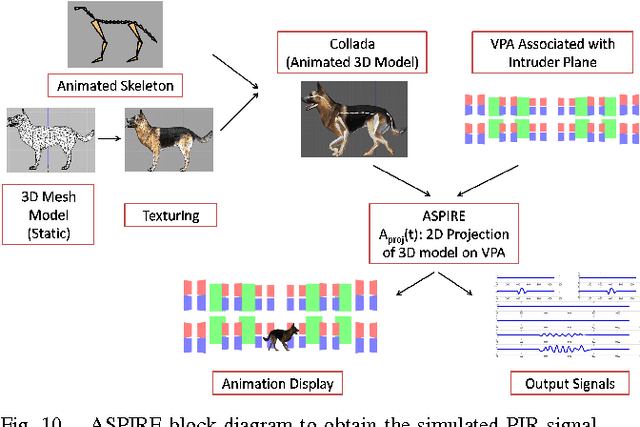
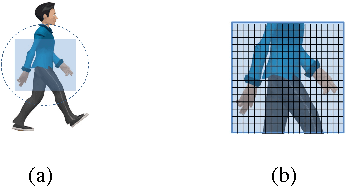
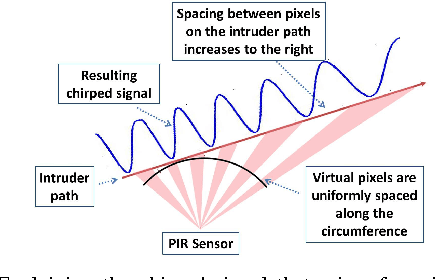
This paper presents the development of a passive infra-red sensor tower platform along with a classification algorithm to distinguish between human intrusion, animal intrusion and clutter arising from wind-blown vegetative movement in an outdoor environment. The research was aimed at exploring the potential use of wireless sensor networks as an early-warning system to help mitigate human-wildlife conflicts occurring at the edge of a forest. There are three important features to the development. Firstly, the sensor platform employs multiple sensors arranged in the form of a two-dimensional array to give it a key spatial-resolution capability that aids in classification. Secondly, given the challenges of collecting data involving animal intrusion, an Animation-based Simulation tool for Passive Infra-Red sEnsor (ASPIRE) was developed that simulates signals corresponding to human and animal intrusion and some limited models of vegetative clutter. This speeded up the process of algorithm development by allowing us to test different hypotheses in a time-efficient manner. Finally, a chirplet-based model for intruder signal was developed that significantly helped boost classification accuracy despite drawing data from a smaller number of sensors. An SVM-based classifier was used which made use of chirplet, energy and signal cross-correlation-based features. The average accuracy obtained for intruder detection and classification on real-world and simulated data sets was in excess of 97%.