 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: A Neurosymbolic Framework for Automated Conjecture and Reasoning in Quantum Circuit Analysis
May 11, 2026In this paper, we present SCALAR (Symbolic Conjecture and LLM-Assisted Reasoning), a neurosymbolic framework for automated conjecture generation in quantum circuit analysis built on top of the CUDA-Q open source framework. The system integrates quantum simulation, symbolic conjecture generation, and LLM-based interpretation. We evaluate SCALAR on 82 MaxCut instances from the MQLib benchmark dataset and extend the analysis to 2,000 randomly generated graphs across four topologies: regular, Erdos-Renyi, Barabasi-Albert, and Watts-Strogatz. The framework generates conjectured bounds relating optimal QAOA parameters to graph invariants, including known relationships such as periodicity constraints on the phase separation parameter $γ$. SCALAR also recovers previously reported parameter transfer phenomena across structurally similar instances. Additionally, the system identifies correlations between graph structural features and optimization landscape properties, which we characterize through invariant-based descriptors. Using CUDA-Q tensor network simulator, we scale experiments to instances of up to 77 qubits. We discuss the accuracy, generality, and limitations of the generated conjectures, including sensitivity to graph class and quantum circuit depth.
MobileASR: A resource-aware on-device personalisation framework for automatic speech recognition in mobile phones
Jun 15, 2023We describe a comprehensive methodology for developing user-voice personalised ASR models by effectively training models on mobile phones, allowing user data and models to be stored and used locally. To achieve this, we propose a resource-aware sub-model based training approach that considers the RAM, and battery capabilities of mobile phones. We also investigate the relationship between available resources and training time, highlighting the effectiveness of using sub-models in such scenarios. By taking into account the evaluation metric and battery constraints of the mobile phones, we are able to perform efficient training and halt the process accordingly. To simulate real users, we use speakers with various accents. The entire on-device training and evaluation framework was then tested on various mobile phones across brands. We show that fine-tuning the models and selecting the right hyperparameter values is a trade-off between the lowest achievable performance metric, on-device training time, and memory consumption. Overall, our methodology offers a comprehensive solution for developing personalized ASR models while leveraging the capabilities of mobile phones, and balancing the need for accuracy with resource constraints.
A quantum generative model for multi-dimensional time series using Hamiltonian learning
Apr 13, 2022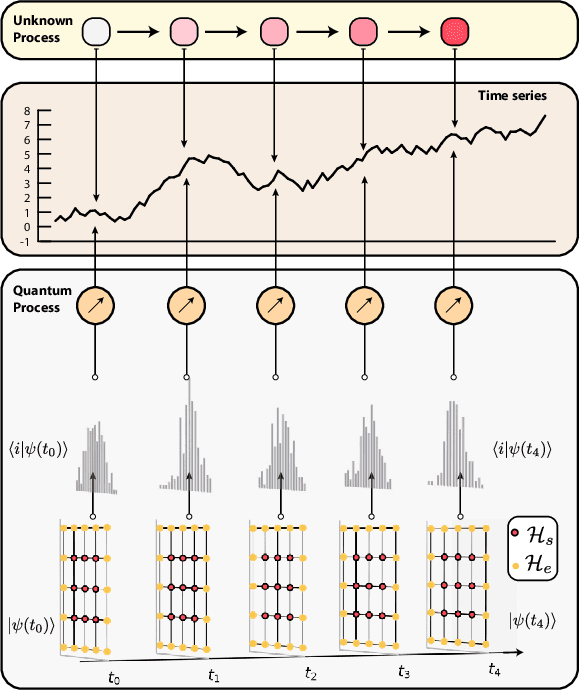
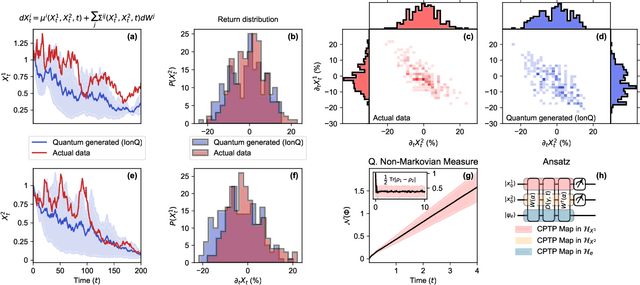
Synthetic data generation has proven to be a promising solution for addressing data availability issues in various domains. Even more challenging is the generation of synthetic time series data, where one has to preserve temporal dynamics, i.e., the generated time series must respect the original relationships between variables across time. Recently proposed techniques such as generative adversarial networks (GANs) and quantum-GANs lack the ability to attend to the time series specific temporal correlations adequately. We propose using the inherent nature of quantum computers to simulate quantum dynamics as a technique to encode such features. We start by assuming that a given time series can be generated by a quantum process, after which we proceed to learn that quantum process using quantum machine learning. We then use the learned model to generate out-of-sample time series and show that it captures unique and complex features of the learned time series. We also study the class of time series that can be modeled using this technique. Finally, we experimentally demonstrate the proposed algorithm on an 11-qubit trapped-ion quantum machine.
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021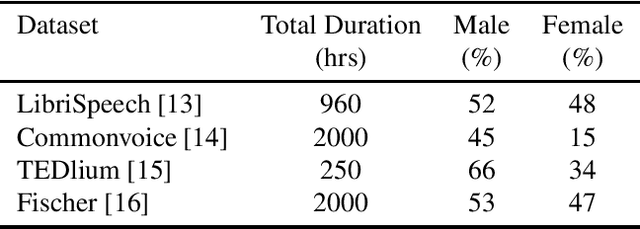
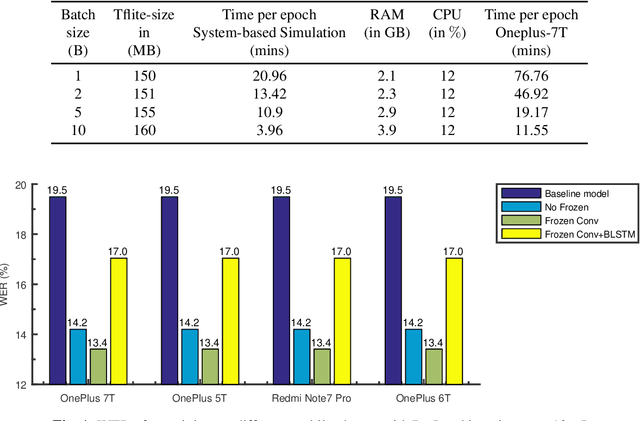
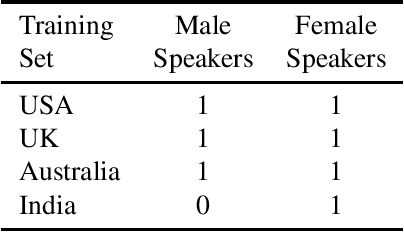
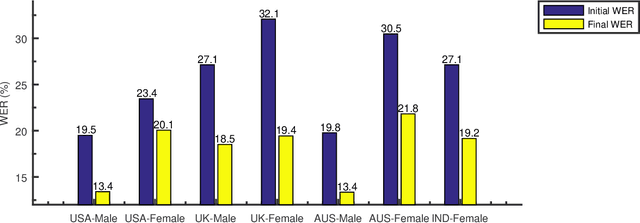
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.
Can Artificial Intelligence Reliably Report Chest X-Rays?: Radiologist Validation of an Algorithm trained on 1.2 Million X-Rays
Jul 19, 2018
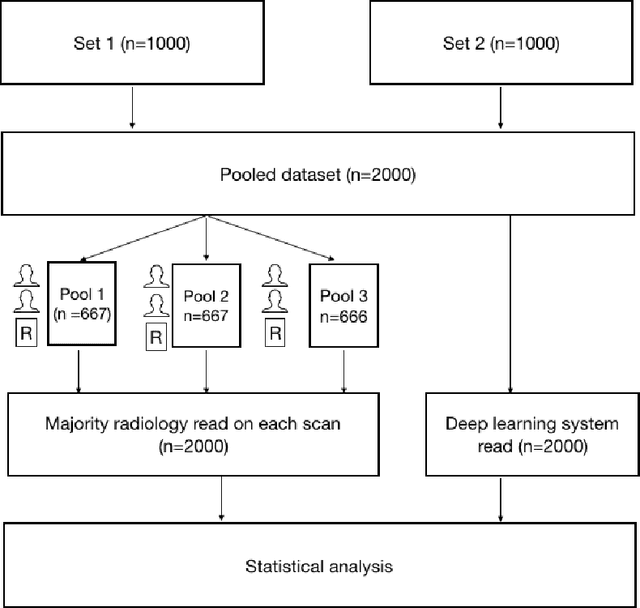
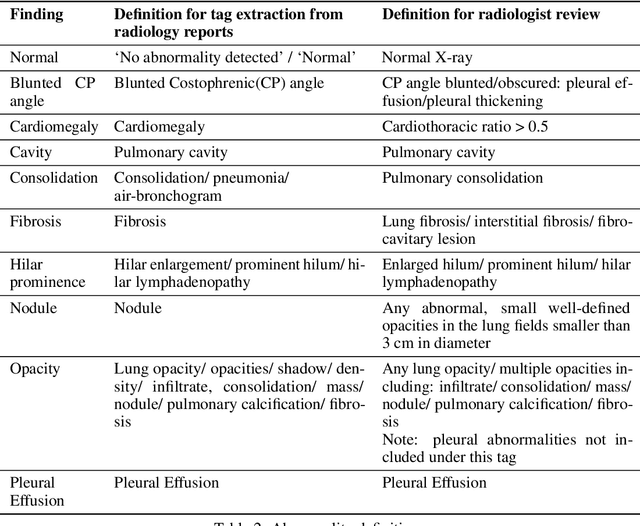
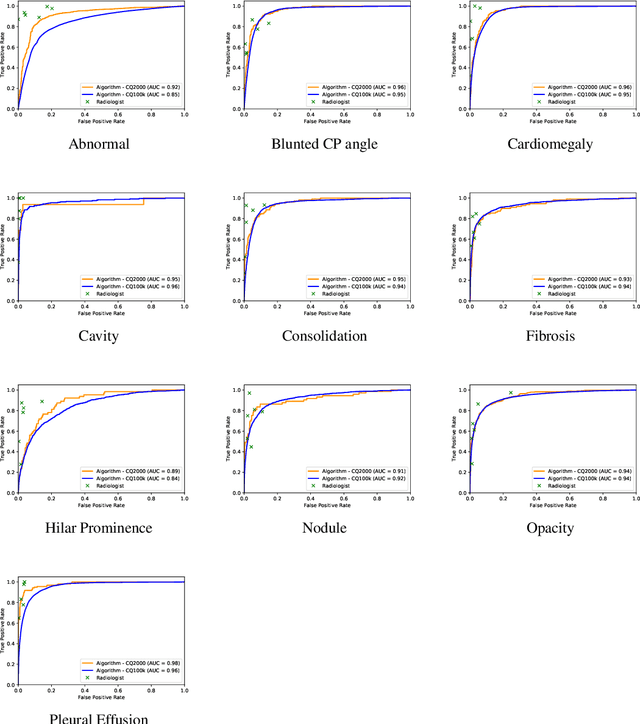
Background and Objectives: Chest x-rays are the most commonly performed, cost-effective diagnostic imaging tests ordered by physicians. A clinically validated, automated artificial intelligence system that can reliably separate normal from abnormal would be invaluable in addressing the problem of reporting backlogs and the lack of radiologists in low-resource settings. The aim of this study was to develop and validate a deep learning system to detect chest x-ray abnormalities. Methods: A deep learning system was trained on 1.2 million x-rays and their corresponding radiology reports to identify abnormal x-rays and the following specific abnormalities: blunted costophrenic angle, calcification, cardiomegaly, cavity, consolidation, fibrosis, hilar enlargement, opacity and pleural effusion. The system was tested versus a 3-radiologist majority on an independent, retrospectively collected de-identified set of 2000 x-rays. The primary accuracy measure was area under the ROC curve (AUC), estimated separately for each abnormality as well as for normal versus abnormal reports. Results: The deep learning system demonstrated an AUC of 0.93(CI 0.92-0.94) for detection of abnormal scans, and AUC(CI) of 0.94(0.92-0.97),0.88(0.85-0.91), 0.97(0.95-0.99), 0.92(0.82-1), 0.94(0.91-0.97), 0.92(0.88-0.95), 0.89(0.84-0.94), 0.93(0.92-0.95), 0.98(0.97-1), 0.93(0.0.87-0.99) for the detection of blunted CP angle, calcification, cardiomegaly, cavity, consolidation, fibrosis,hilar enlargement, opacity and pleural effusion respectively. Conclusions and Relevance: Our study shows that a deep learning algorithm trained on a large quantity of labelled data can accurately detect abnormalities on chest x-rays. As these systems further increase in accuracy, the feasibility of using artificial intelligence to extend the reach of chest x-ray interpretation and improve reporting efficiency will increase in tandem.
Development and Validation of Deep Learning Algorithms for Detection of Critical Findings in Head CT Scans
Apr 12, 2018
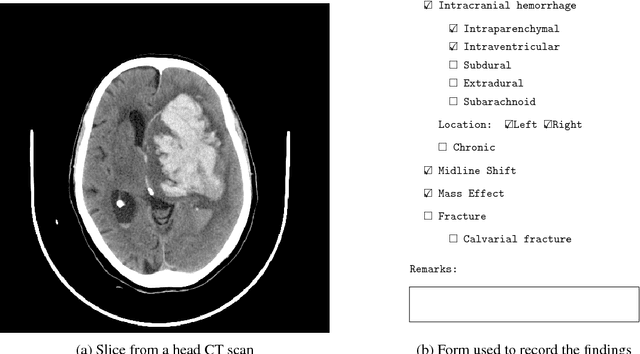
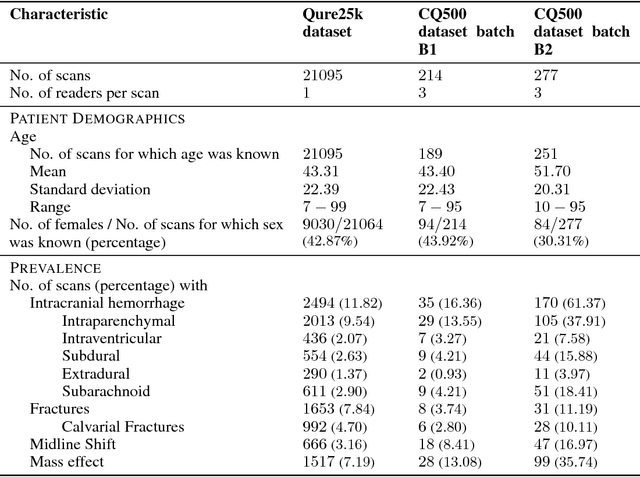
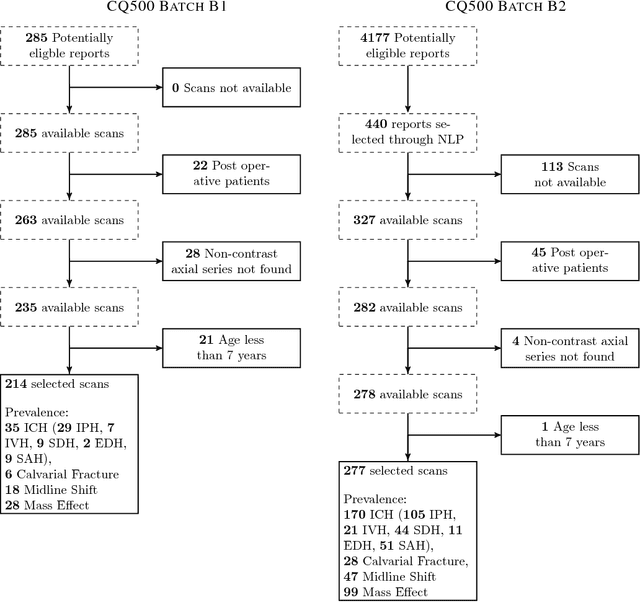
Importance: Non-contrast head CT scan is the current standard for initial imaging of patients with head trauma or stroke symptoms. Objective: To develop and validate a set of deep learning algorithms for automated detection of following key findings from non-contrast head CT scans: intracranial hemorrhage (ICH) and its types, intraparenchymal (IPH), intraventricular (IVH), subdural (SDH), extradural (EDH) and subarachnoid (SAH) hemorrhages, calvarial fractures, midline shift and mass effect. Design and Settings: We retrospectively collected a dataset containing 313,318 head CT scans along with their clinical reports from various centers. A part of this dataset (Qure25k dataset) was used to validate and the rest to develop algorithms. Additionally, a dataset (CQ500 dataset) was collected from different centers in two batches B1 & B2 to clinically validate the algorithms. Main Outcomes and Measures: Original clinical radiology report and consensus of three independent radiologists were considered as gold standard for Qure25k and CQ500 datasets respectively. Area under receiver operating characteristics curve (AUC) for each finding was primarily used to evaluate the algorithms. Results: Qure25k dataset contained 21,095 scans (mean age 43.31; 42.87% female) while batches B1 and B2 of CQ500 dataset consisted of 214 (mean age 43.40; 43.92% female) and 277 (mean age 51.70; 30.31% female) scans respectively. On Qure25k dataset, the algorithms achieved AUCs of 0.9194, 0.8977, 0.9559, 0.9161, 0.9288 and 0.9044 for detecting ICH, IPH, IVH, SDH, EDH and SAH respectively. AUCs for the same on CQ500 dataset were 0.9419, 0.9544, 0.9310, 0.9521, 0.9731 and 0.9574 respectively. For detecting calvarial fractures, midline shift and mass effect, AUCs on Qure25k dataset were 0.9244, 0.9276 and 0.8583 respectively, while AUCs on CQ500 dataset were 0.9624, 0.9697 and 0.9216 respectively.