 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Epochs in AI Supervision: Design and Implementation of an Autonomous Radiology AI Monitoring System
Nov 24, 2023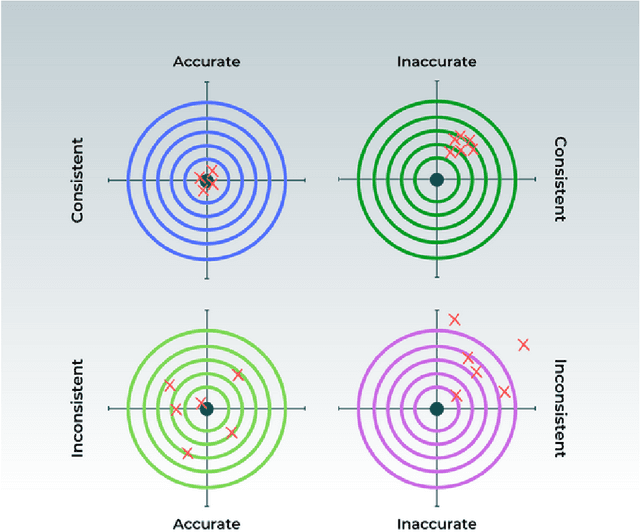
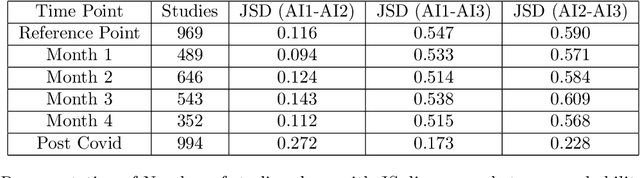
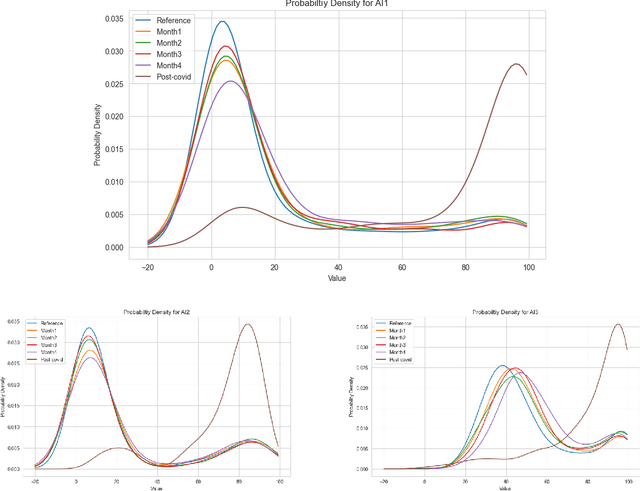

With the increasingly widespread adoption of AI in healthcare, maintaining the accuracy and reliability of AI models in clinical practice has become crucial. In this context, we introduce novel methods for monitoring the performance of radiology AI classification models in practice, addressing the challenges of obtaining real-time ground truth for performance monitoring. We propose two metrics - predictive divergence and temporal stability - to be used for preemptive alerts of AI performance changes. Predictive divergence, measured using Kullback-Leibler and Jensen-Shannon divergences, evaluates model accuracy by comparing predictions with those of two supplementary models. Temporal stability is assessed through a comparison of current predictions against historical moving averages, identifying potential model decay or data drift. This approach was retrospectively validated using chest X-ray data from a single-center imaging clinic, demonstrating its effectiveness in maintaining AI model reliability. By providing continuous, real-time insights into model performance, our system ensures the safe and effective use of AI in clinical decision-making, paving the way for more robust AI integration in healthcare
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 31, 2023



Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
Navigating Fairness in Radiology AI: Concepts, Consequences,and Crucial Considerations
Jun 02, 2023
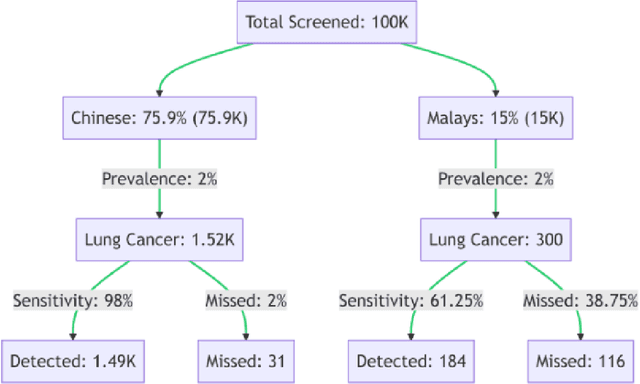
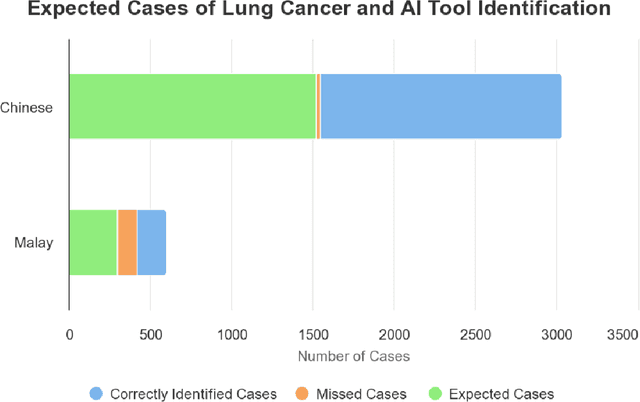
Artificial Intelligence (AI) has significantly revolutionized radiology, promising improved patient outcomes and streamlined processes. However, it's critical to ensure the fairness of AI models to prevent stealthy bias and disparities from leading to unequal outcomes. This review discusses the concept of fairness in AI, focusing on bias auditing using the Aequitas toolkit, and its real-world implications in radiology, particularly in disease screening scenarios. Aequitas, an open-source bias audit toolkit, scrutinizes AI models' decisions, identifying hidden biases that may result in disparities across different demographic groups and imaging equipment brands. This toolkit operates on statistical theories, analyzing a large dataset to reveal a model's fairness. It excels in its versatility to handle various variables simultaneously, especially in a field as diverse as radiology. The review explicates essential fairness metrics: Equal and Proportional Parity, False Positive Rate Parity, False Discovery Rate Parity, False Negative Rate Parity, and False Omission Rate Parity. Each metric serves unique purposes and offers different insights. We present hypothetical scenarios to demonstrate their relevance in disease screening settings, and how disparities can lead to significant real-world impacts.
Development and Validation of Deep Learning Algorithms for Detection of Critical Findings in Head CT Scans
Apr 12, 2018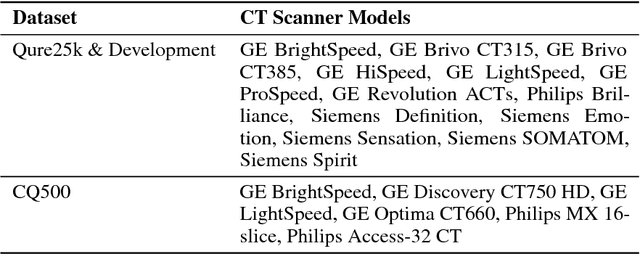
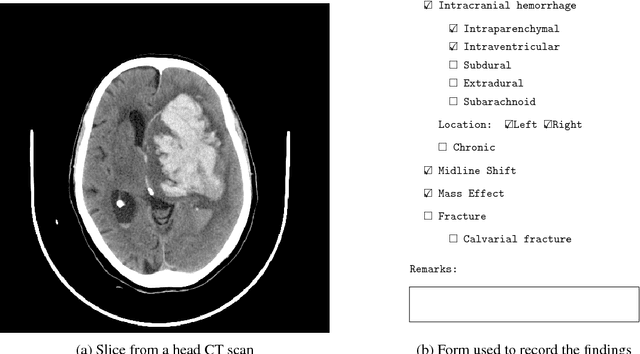
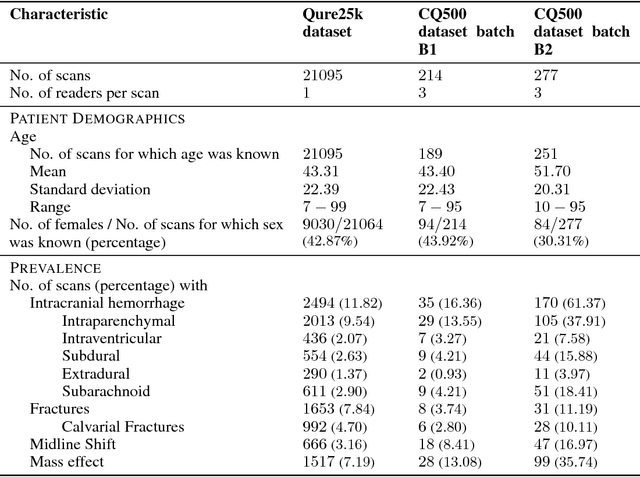
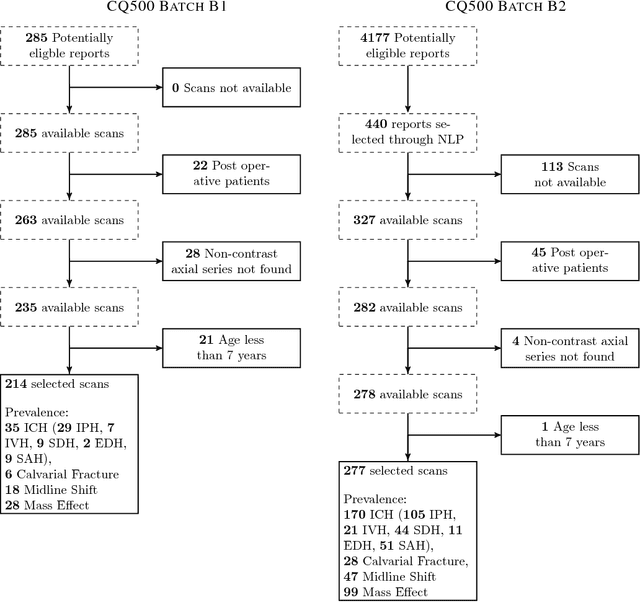
Importance: Non-contrast head CT scan is the current standard for initial imaging of patients with head trauma or stroke symptoms. Objective: To develop and validate a set of deep learning algorithms for automated detection of following key findings from non-contrast head CT scans: intracranial hemorrhage (ICH) and its types, intraparenchymal (IPH), intraventricular (IVH), subdural (SDH), extradural (EDH) and subarachnoid (SAH) hemorrhages, calvarial fractures, midline shift and mass effect. Design and Settings: We retrospectively collected a dataset containing 313,318 head CT scans along with their clinical reports from various centers. A part of this dataset (Qure25k dataset) was used to validate and the rest to develop algorithms. Additionally, a dataset (CQ500 dataset) was collected from different centers in two batches B1 & B2 to clinically validate the algorithms. Main Outcomes and Measures: Original clinical radiology report and consensus of three independent radiologists were considered as gold standard for Qure25k and CQ500 datasets respectively. Area under receiver operating characteristics curve (AUC) for each finding was primarily used to evaluate the algorithms. Results: Qure25k dataset contained 21,095 scans (mean age 43.31; 42.87% female) while batches B1 and B2 of CQ500 dataset consisted of 214 (mean age 43.40; 43.92% female) and 277 (mean age 51.70; 30.31% female) scans respectively. On Qure25k dataset, the algorithms achieved AUCs of 0.9194, 0.8977, 0.9559, 0.9161, 0.9288 and 0.9044 for detecting ICH, IPH, IVH, SDH, EDH and SAH respectively. AUCs for the same on CQ500 dataset were 0.9419, 0.9544, 0.9310, 0.9521, 0.9731 and 0.9574 respectively. For detecting calvarial fractures, midline shift and mass effect, AUCs on Qure25k dataset were 0.9244, 0.9276 and 0.8583 respectively, while AUCs on CQ500 dataset were 0.9624, 0.9697 and 0.9216 respectively.