 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
Navigating Fairness in Radiology AI: Concepts, Consequences,and Crucial Considerations
Jun 02, 2023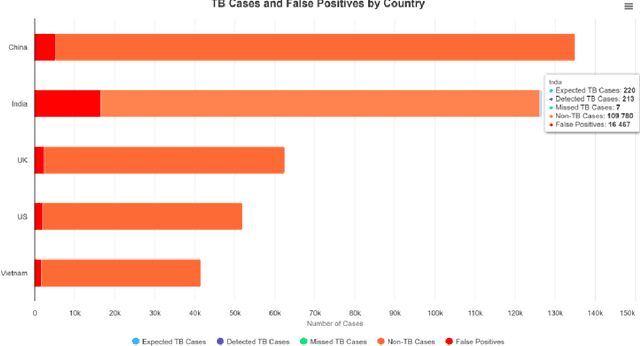
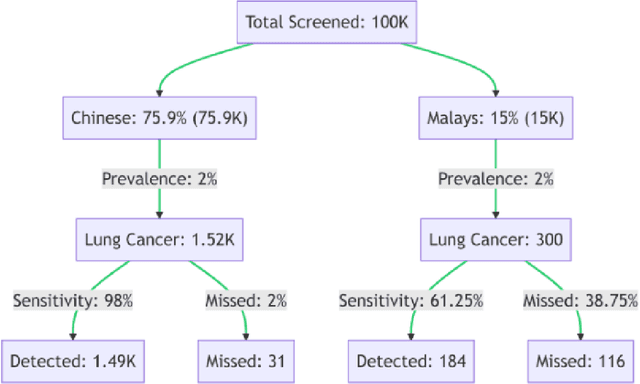
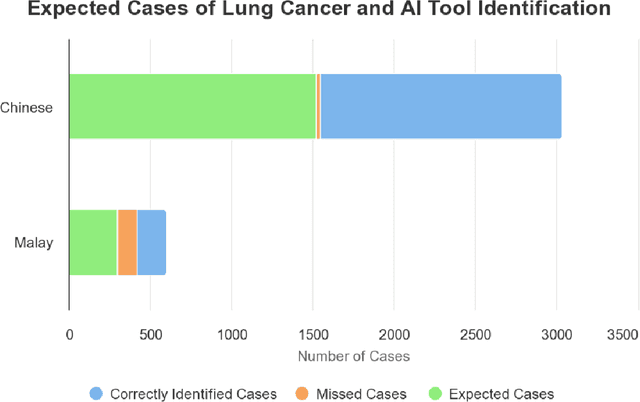
Artificial Intelligence (AI) has significantly revolutionized radiology, promising improved patient outcomes and streamlined processes. However, it's critical to ensure the fairness of AI models to prevent stealthy bias and disparities from leading to unequal outcomes. This review discusses the concept of fairness in AI, focusing on bias auditing using the Aequitas toolkit, and its real-world implications in radiology, particularly in disease screening scenarios. Aequitas, an open-source bias audit toolkit, scrutinizes AI models' decisions, identifying hidden biases that may result in disparities across different demographic groups and imaging equipment brands. This toolkit operates on statistical theories, analyzing a large dataset to reveal a model's fairness. It excels in its versatility to handle various variables simultaneously, especially in a field as diverse as radiology. The review explicates essential fairness metrics: Equal and Proportional Parity, False Positive Rate Parity, False Discovery Rate Parity, False Negative Rate Parity, and False Omission Rate Parity. Each metric serves unique purposes and offers different insights. We present hypothetical scenarios to demonstrate their relevance in disease screening settings, and how disparities can lead to significant real-world impacts.