 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSNA Large Language Model Benchmark Dataset for Chest Radiographs of Cardiothoracic Disease: Radiologist Evaluation and Validation Enhanced by AI Labels (REVEAL-CXR)
Jan 21, 2026Multimodal large language models have demonstrated comparable performance to that of radiology trainees on multiple-choice board-style exams. However, to develop clinically useful multimodal LLM tools, high-quality benchmarks curated by domain experts are essential. To curate released and holdout datasets of 100 chest radiographic studies each and propose an artificial intelligence (AI)-assisted expert labeling procedure to allow radiologists to label studies more efficiently. A total of 13,735 deidentified chest radiographs and their corresponding reports from the MIDRC were used. GPT-4o extracted abnormal findings from the reports, which were then mapped to 12 benchmark labels with a locally hosted LLM (Phi-4-Reasoning). From these studies, 1,000 were sampled on the basis of the AI-suggested benchmark labels for expert review; the sampling algorithm ensured that the selected studies were clinically relevant and captured a range of difficulty levels. Seventeen chest radiologists participated, and they marked "Agree all", "Agree mostly" or "Disagree" to indicate their assessment of the correctness of the LLM suggested labels. Each chest radiograph was evaluated by three experts. Of these, at least two radiologists selected "Agree All" for 381 radiographs. From this set, 200 were selected, prioritizing those with less common or multiple finding labels, and divided into 100 released radiographs and 100 reserved as the holdout dataset. The holdout dataset is used exclusively by RSNA to independently evaluate different models. A benchmark of 200 chest radiographic studies with 12 benchmark labels was created and made publicly available https://imaging.rsna.org, with each chest radiograph verified by three radiologists. In addition, an AI-assisted labeling procedure was developed to help radiologists label at scale, minimize unnecessary omissions, and support a semicollaborative environment.
A Multi-agent Large Language Model Framework to Automatically Assess Performance of a Clinical AI Triage Tool
Oct 30, 2025Purpose: The purpose of this study was to determine if an ensemble of multiple LLM agents could be used collectively to provide a more reliable assessment of a pixel-based AI triage tool than a single LLM. Methods: 29,766 non-contrast CT head exams from fourteen hospitals were processed by a commercial intracranial hemorrhage (ICH) AI detection tool. Radiology reports were analyzed by an ensemble of eight open-source LLM models and a HIPAA compliant internal version of GPT-4o using a single multi-shot prompt that assessed for presence of ICH. 1,726 examples were manually reviewed. Performance characteristics of the eight open-source models and consensus were compared to GPT-4o. Three ideal consensus LLM ensembles were tested for rating the performance of the triage tool. Results: The cohort consisted of 29,766 head CTs exam-report pairs. The highest AUC performance was achieved with llama3.3:70b and GPT-4o (AUC= 0.78). The average precision was highest for Llama3.3:70b and GPT-4o (AP=0.75 & 0.76). Llama3.3:70b had the highest F1 score (0.81) and recall (0.85), greater precision (0.78), specificity (0.72), and MCC (0.57). Using MCC (95% CI) the ideal combination of LLMs were: Full-9 Ensemble 0.571 (0.552-0.591), Top-3 Ensemble 0.558 (0.537-0.579), Consensus 0.556 (0.539-0.574), and GPT4o 0.522 (0.500-0.543). No statistically significant differences were observed between Top-3, Full-9, and Consensus (p > 0.05). Conclusion: An ensemble of medium to large sized open-source LLMs provides a more consistent and reliable method to derive a ground truth retrospective evaluation of a clinical AI triage tool over a single LLM alone.
The RSNA Lumbar Degenerative Imaging Spine Classification (LumbarDISC) Dataset
Jun 10, 2025The Radiological Society of North America (RSNA) Lumbar Degenerative Imaging Spine Classification (LumbarDISC) dataset is the largest publicly available dataset of adult MRI lumbar spine examinations annotated for degenerative changes. The dataset includes 2,697 patients with a total of 8,593 image series from 8 institutions across 6 countries and 5 continents. The dataset is available for free for non-commercial use via Kaggle and RSNA Medical Imaging Resource of AI (MIRA). The dataset was created for the RSNA 2024 Lumbar Spine Degenerative Classification competition where competitors developed deep learning models to grade degenerative changes in the lumbar spine. The degree of spinal canal, subarticular recess, and neural foraminal stenosis was graded at each intervertebral disc level in the lumbar spine. The images were annotated by expert volunteer neuroradiologists and musculoskeletal radiologists from the RSNA, American Society of Neuroradiology, and the American Society of Spine Radiology. This dataset aims to facilitate research and development in machine learning and lumbar spine imaging to lead to improved patient care and clinical efficiency.
The RSNA Abdominal Traumatic Injury CT (RATIC) Dataset
May 30, 2024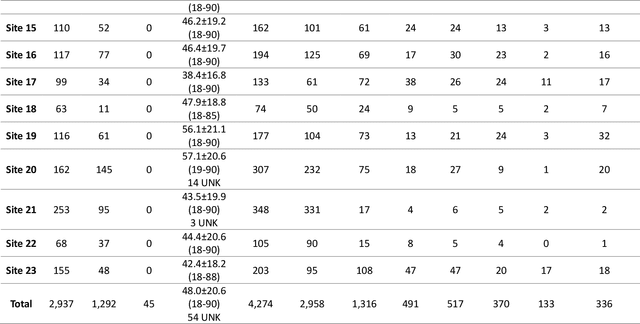
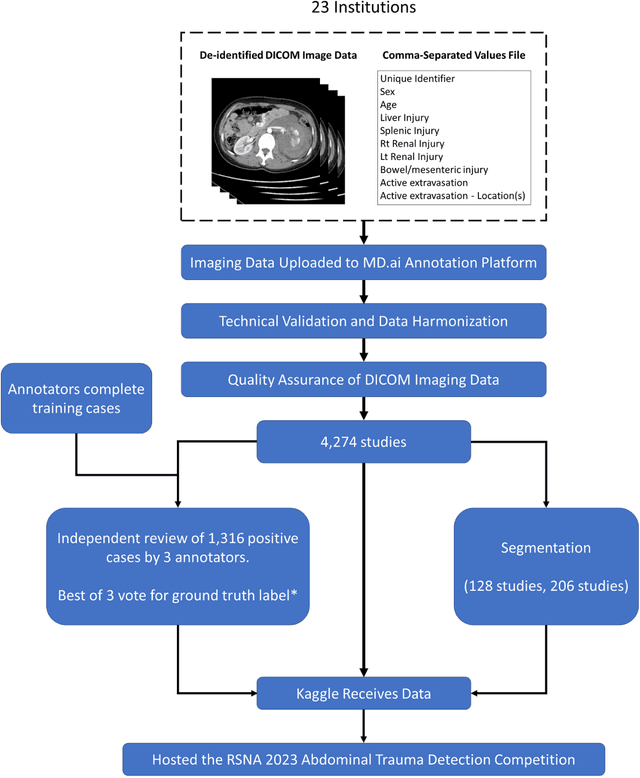
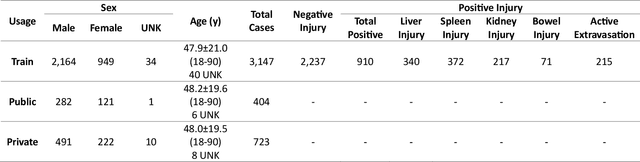
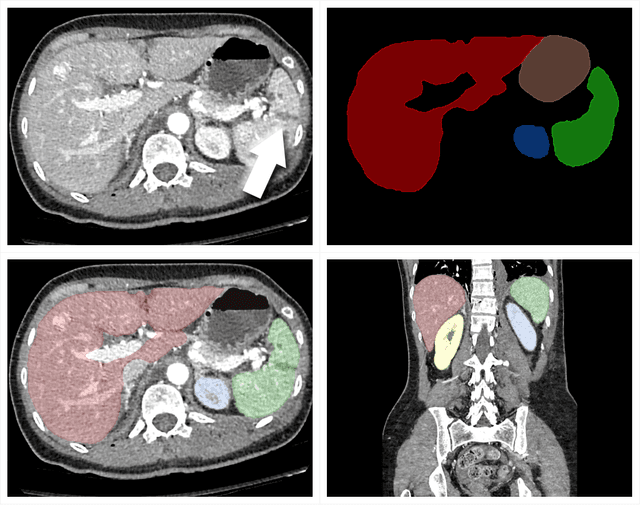
The RSNA Abdominal Traumatic Injury CT (RATIC) dataset is the largest publicly available collection of adult abdominal CT studies annotated for traumatic injuries. This dataset includes 4,274 studies from 23 institutions across 14 countries. The dataset is freely available for non-commercial use via Kaggle at https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection. Created for the RSNA 2023 Abdominal Trauma Detection competition, the dataset encourages the development of advanced machine learning models for detecting abdominal injuries on CT scans. The dataset encompasses detection and classification of traumatic injuries across multiple organs, including the liver, spleen, kidneys, bowel, and mesentery. Annotations were created by expert radiologists from the American Society of Emergency Radiology (ASER) and Society of Abdominal Radiology (SAR). The dataset is annotated at multiple levels, including the presence of injuries in three solid organs with injury grading, image-level annotations for active extravasations and bowel injury, and voxelwise segmentations of each of the potentially injured organs. With the release of this dataset, we hope to facilitate research and development in machine learning and abdominal trauma that can lead to improved patient care and outcomes.
The Brain Tumor Segmentation Challenge 2023: Local Synthesis of Healthy Brain Tissue via Inpainting
May 15, 2023



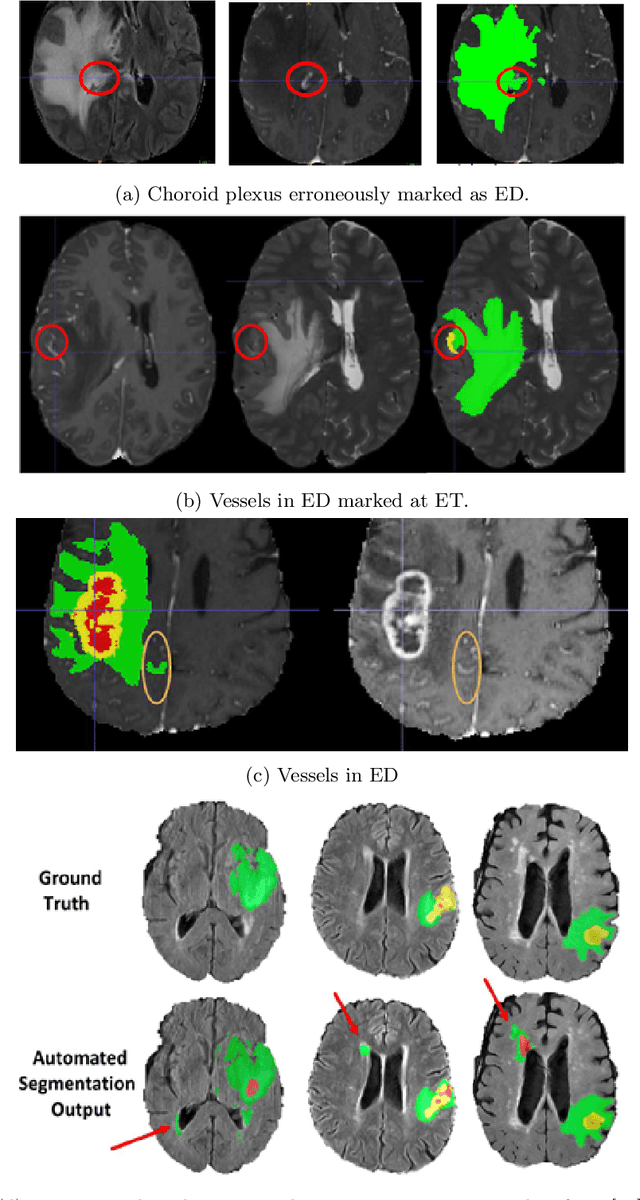
A myriad of algorithms for the automatic analysis of brain MR images is available to support clinicians in their decision-making. For brain tumor patients, the image acquisition time series typically starts with a scan that is already pathological. This poses problems, as many algorithms are designed to analyze healthy brains and provide no guarantees for images featuring lesions. Examples include but are not limited to algorithms for brain anatomy parcellation, tissue segmentation, and brain extraction. To solve this dilemma, we introduce the BraTS 2023 inpainting challenge. Here, the participants' task is to explore inpainting techniques to synthesize healthy brain scans from lesioned ones. The following manuscript contains the task formulation, dataset, and submission procedure. Later it will be updated to summarize the findings of the challenge. The challenge is organized as part of the BraTS 2023 challenge hosted at the MICCAI 2023 conference in Vancouver, Canada.
BenchMD: A Benchmark for Modality-Agnostic Learning on Medical Images and Sensors
Apr 17, 2023



Medical data poses a daunting challenge for AI algorithms: it exists in many different modalities, experiences frequent distribution shifts, and suffers from a scarcity of examples and labels. Recent advances, including transformers and self-supervised learning, promise a more universal approach that can be applied flexibly across these diverse conditions. To measure and drive progress in this direction, we present BenchMD: a benchmark that tests how modality-agnostic methods, including architectures and training techniques (e.g. self-supervised learning, ImageNet pretraining), perform on a diverse array of clinically-relevant medical tasks. BenchMD combines 19 publicly available datasets for 7 medical modalities, including 1D sensor data, 2D images, and 3D volumetric scans. Our benchmark reflects real-world data constraints by evaluating methods across a range of dataset sizes, including challenging few-shot settings that incentivize the use of pretraining. Finally, we evaluate performance on out-of-distribution data collected at different hospitals than the training data, representing naturally-occurring distribution shifts that frequently degrade the performance of medical AI models. Our baseline results demonstrate that no modality-agnostic technique achieves strong performance across all modalities, leaving ample room for improvement on the benchmark. Code is released at https://github.com/rajpurkarlab/BenchMD .
Federated Learning on Heterogenous Data using Chest CT
Mar 23, 2023Large data have accelerated advances in AI. While it is well known that population differences from genetics, sex, race, diet, and various environmental factors contribute significantly to disease, AI studies in medicine have largely focused on locoregional patient cohorts with less diverse data sources. Such limitation stems from barriers to large-scale data share in medicine and ethical concerns over data privacy. Federated learning (FL) is one potential pathway for AI development that enables learning across hospitals without data share. In this study, we show the results of various FL strategies on one of the largest and most diverse COVID-19 chest CT datasets: 21 participating hospitals across five continents that comprise >10,000 patients with >1 million images. We present three techniques: Fed Averaging (FedAvg), Incremental Institutional Learning (IIL), and Cyclical Incremental Institutional Learning (CIIL). We also propose an FL strategy that leverages synthetically generated data to overcome class imbalances and data size disparities across centers. We show that FL can achieve comparable performance to Centralized Data Sharing (CDS) while maintaining high performance across sites with small, underrepresented data. We investigate the strengths and weaknesses for all technical approaches on this heterogeneous dataset including the robustness to non-Independent and identically distributed (non-IID) diversity of data. We also describe the sources of data heterogeneity such as age, sex, and site locations in the context of FL and show how even among the correctly labeled populations, disparities can arise due to these biases.
NanoBatch DPSGD: Exploring Differentially Private learning on ImageNet with low batch sizes on the IPU
Sep 24, 2021
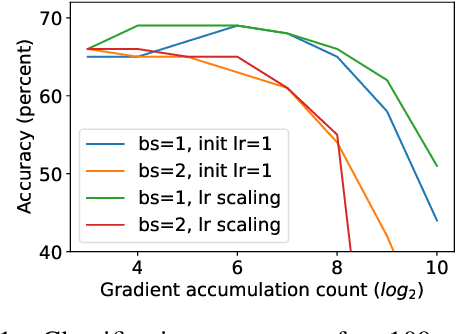
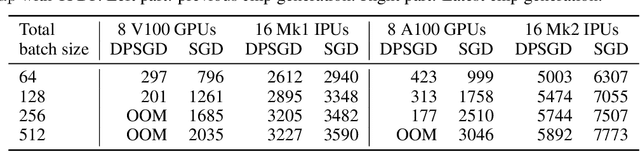

Differentially private SGD (DPSGD) has recently shown promise in deep learning. However, compared to non-private SGD, the DPSGD algorithm places computational overheads that can undo the benefit of batching in GPUs. Microbatching is a standard method to alleviate this and is fully supported in the TensorFlow Privacy library (TFDP). However, this technique, while improving training times also reduces the quality of the gradients and degrades the classification accuracy. Recent works that for example use the JAX framework show promise in also alleviating this but still show degradation in throughput from non-private to private SGD on CNNs, and have not yet shown ImageNet implementations. In our work, we argue that low batch sizes using group normalization on ResNet-50 can yield high accuracy and privacy on Graphcore IPUs. This enables DPSGD training of ResNet-50 on ImageNet in just 6 hours (100 epochs) on an IPU-POD16 system.
The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification
Jul 05, 2021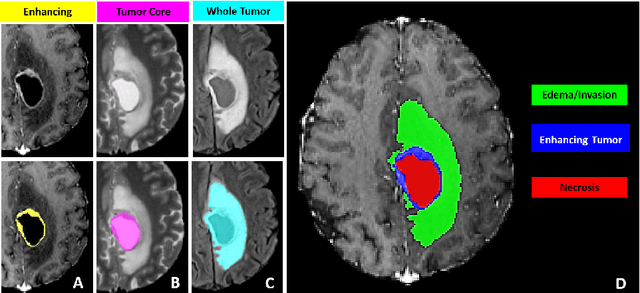
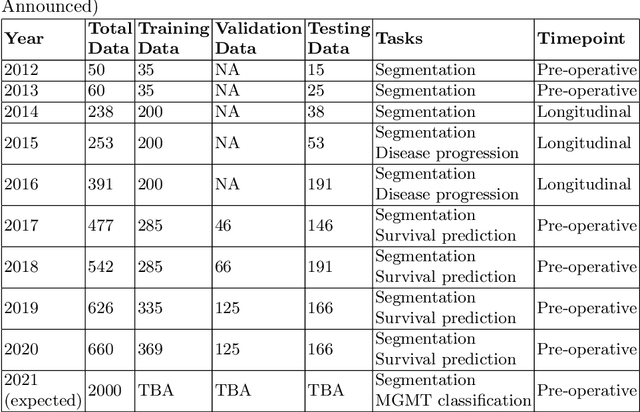
The BraTS 2021 challenge celebrates its 10th anniversary and is jointly organized by the Radiological Society of North America (RSNA), the American Society of Neuroradiology (ASNR), and the Medical Image Computing and Computer Assisted Interventions (MICCAI) society. Since its inception, BraTS has been focusing on being a common benchmarking venue for brain glioma segmentation algorithms, with well-curated multi-institutional multi-parametric magnetic resonance imaging (mpMRI) data. Gliomas are the most common primary malignancies of the central nervous system, with varying degrees of aggressiveness and prognosis. The RSNA-ASNR-MICCAI BraTS 2021 challenge targets the evaluation of computational algorithms assessing the same tumor compartmentalization, as well as the underlying tumor's molecular characterization, in pre-operative baseline mpMRI data from 2,000 patients. Specifically, the two tasks that BraTS 2021 focuses on are: a) the segmentation of the histologically distinct brain tumor sub-regions, and b) the classification of the tumor's O[6]-methylguanine-DNA methyltransferase (MGMT) promoter methylation status. The performance evaluation of all participating algorithms in BraTS 2021 will be conducted through the Sage Bionetworks Synapse platform (Task 1) and Kaggle (Task 2), concluding in distributing to the top ranked participants monetary awards of $60,000 collectively.
A Real-World Demonstration of Machine Learning Generalizability: Intracranial Hemorrhage Detection on Head CT
Feb 09, 2021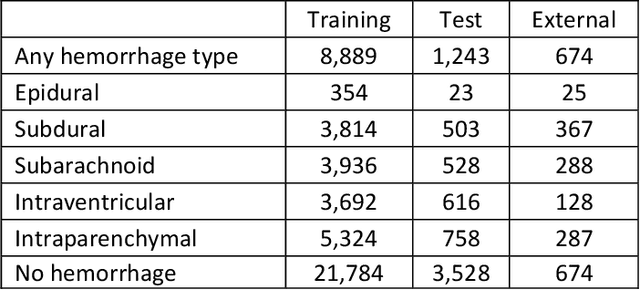

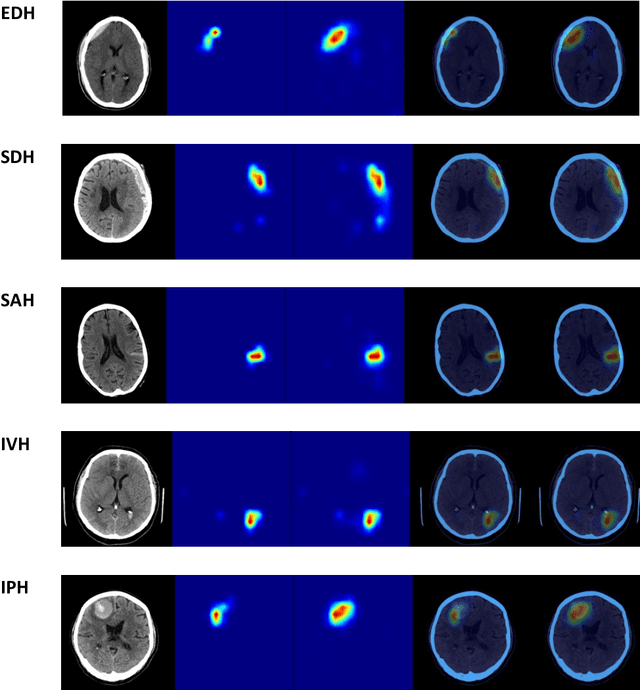

Machine learning (ML) holds great promise in transforming healthcare. While published studies have shown the utility of ML models in interpreting medical imaging examinations, these are often evaluated under laboratory settings. The importance of real world evaluation is best illustrated by case studies that have documented successes and failures in the translation of these models into clinical environments. A key prerequisite for the clinical adoption of these technologies is demonstrating generalizable ML model performance under real world circumstances. The purpose of this study was to demonstrate that ML model generalizability is achievable in medical imaging with the detection of intracranial hemorrhage (ICH) on non-contrast computed tomography (CT) scans serving as the use case. An ML model was trained using 21,784 scans from the RSNA Intracranial Hemorrhage CT dataset while generalizability was evaluated using an external validation dataset obtained from our busy trauma and neurosurgical center. This real world external validation dataset consisted of every unenhanced head CT scan (n = 5,965) performed in our emergency department in 2019 without exclusion. The model demonstrated an AUC of 98.4%, sensitivity of 98.8%, and specificity of 98.0%, on the test dataset. On external validation, the model demonstrated an AUC of 95.4%, sensitivity of 91.3%, and specificity of 94.1%. Evaluating the ML model using a real world external validation dataset that is temporally and geographically distinct from the training dataset indicates that ML generalizability is achievable in medical imaging applications.