 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RSNA Lumbar Degenerative Imaging Spine Classification (LumbarDISC) Dataset
Jun 10, 2025The Radiological Society of North America (RSNA) Lumbar Degenerative Imaging Spine Classification (LumbarDISC) dataset is the largest publicly available dataset of adult MRI lumbar spine examinations annotated for degenerative changes. The dataset includes 2,697 patients with a total of 8,593 image series from 8 institutions across 6 countries and 5 continents. The dataset is available for free for non-commercial use via Kaggle and RSNA Medical Imaging Resource of AI (MIRA). The dataset was created for the RSNA 2024 Lumbar Spine Degenerative Classification competition where competitors developed deep learning models to grade degenerative changes in the lumbar spine. The degree of spinal canal, subarticular recess, and neural foraminal stenosis was graded at each intervertebral disc level in the lumbar spine. The images were annotated by expert volunteer neuroradiologists and musculoskeletal radiologists from the RSNA, American Society of Neuroradiology, and the American Society of Spine Radiology. This dataset aims to facilitate research and development in machine learning and lumbar spine imaging to lead to improved patient care and clinical efficiency.
The RSNA Abdominal Traumatic Injury CT (RATIC) Dataset
May 30, 2024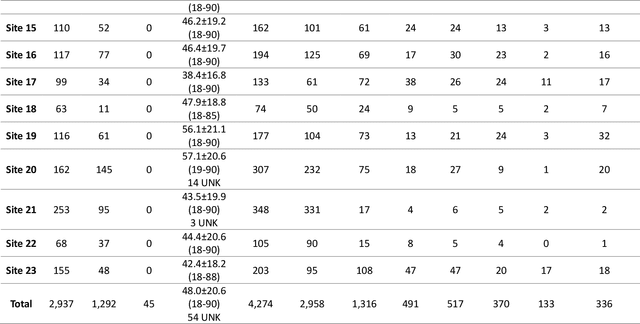
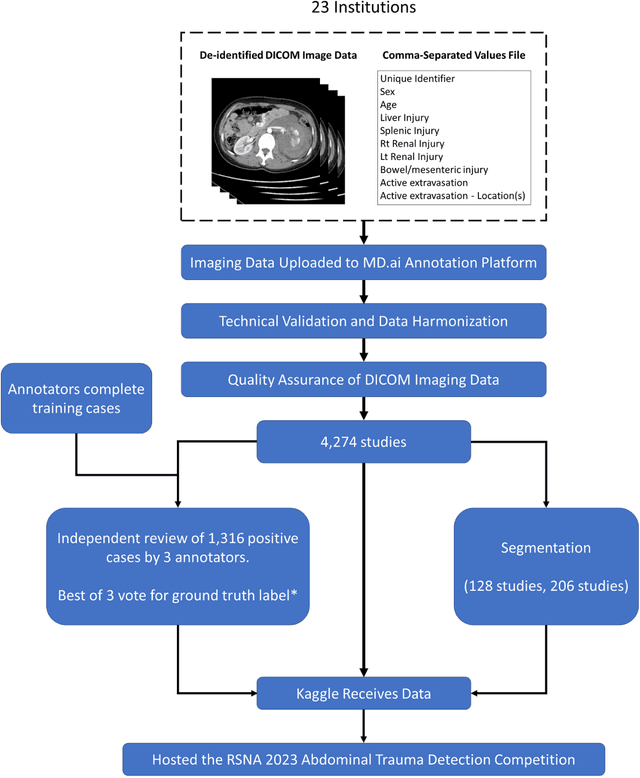
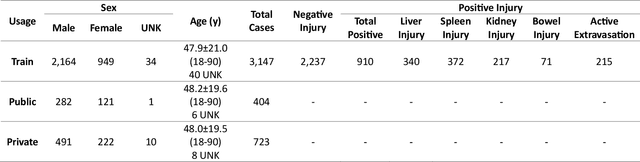
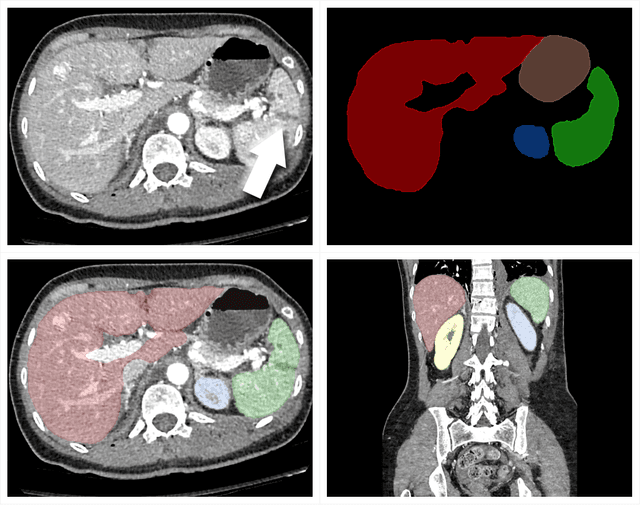
The RSNA Abdominal Traumatic Injury CT (RATIC) dataset is the largest publicly available collection of adult abdominal CT studies annotated for traumatic injuries. This dataset includes 4,274 studies from 23 institutions across 14 countries. The dataset is freely available for non-commercial use via Kaggle at https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection. Created for the RSNA 2023 Abdominal Trauma Detection competition, the dataset encourages the development of advanced machine learning models for detecting abdominal injuries on CT scans. The dataset encompasses detection and classification of traumatic injuries across multiple organs, including the liver, spleen, kidneys, bowel, and mesentery. Annotations were created by expert radiologists from the American Society of Emergency Radiology (ASER) and Society of Abdominal Radiology (SAR). The dataset is annotated at multiple levels, including the presence of injuries in three solid organs with injury grading, image-level annotations for active extravasations and bowel injury, and voxelwise segmentations of each of the potentially injured organs. With the release of this dataset, we hope to facilitate research and development in machine learning and abdominal trauma that can lead to improved patient care and outcomes.
Federated Learning on Heterogenous Data using Chest CT
Mar 23, 2023Large data have accelerated advances in AI. While it is well known that population differences from genetics, sex, race, diet, and various environmental factors contribute significantly to disease, AI studies in medicine have largely focused on locoregional patient cohorts with less diverse data sources. Such limitation stems from barriers to large-scale data share in medicine and ethical concerns over data privacy. Federated learning (FL) is one potential pathway for AI development that enables learning across hospitals without data share. In this study, we show the results of various FL strategies on one of the largest and most diverse COVID-19 chest CT datasets: 21 participating hospitals across five continents that comprise >10,000 patients with >1 million images. We present three techniques: Fed Averaging (FedAvg), Incremental Institutional Learning (IIL), and Cyclical Incremental Institutional Learning (CIIL). We also propose an FL strategy that leverages synthetically generated data to overcome class imbalances and data size disparities across centers. We show that FL can achieve comparable performance to Centralized Data Sharing (CDS) while maintaining high performance across sites with small, underrepresented data. We investigate the strengths and weaknesses for all technical approaches on this heterogeneous dataset including the robustness to non-Independent and identically distributed (non-IID) diversity of data. We also describe the sources of data heterogeneity such as age, sex, and site locations in the context of FL and show how even among the correctly labeled populations, disparities can arise due to these biases.