 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate, Adapt, Anonymize (3A): a Framework for Privacy Preserving Training Data Release for Machine Learning
Jul 04, 2023



The availability of large amounts of informative data is crucial for successful machine learning. However, in domains with sensitive information, the release of high-utility data which protects the privacy of individuals has proven challenging. Despite progress in differential privacy and generative modeling for privacy-preserving data release in the literature, only a few approaches optimize for machine learning utility: most approaches only take into account statistical metrics on the data itself and fail to explicitly preserve the loss metrics of machine learning models that are to be subsequently trained on the generated data. In this paper, we introduce a data release framework, 3A (Approximate, Adapt, Anonymize), to maximize data utility for machine learning, while preserving differential privacy. We also describe a specific implementation of this framework that leverages mixture models to approximate, kernel-inducing points to adapt, and Gaussian differential privacy to anonymize a dataset, in order to ensure that the resulting data is both privacy-preserving and high utility. We present experimental evidence showing minimal discrepancy between performance metrics of models trained on real versus privatized datasets, when evaluated on held-out real data. We also compare our results with several privacy-preserving synthetic data generation models (such as differentially private generative adversarial networks), and report significant increases in classification performance metrics compared to state-of-the-art models. These favorable comparisons show that the presented framework is a promising direction of research, increasing the utility of low-risk synthetic data release for machine learning.
* 10 pages, 3 figures, AAAI Workshop
Federated Learning on Heterogenous Data using Chest CT
Mar 23, 2023Large data have accelerated advances in AI. While it is well known that population differences from genetics, sex, race, diet, and various environmental factors contribute significantly to disease, AI studies in medicine have largely focused on locoregional patient cohorts with less diverse data sources. Such limitation stems from barriers to large-scale data share in medicine and ethical concerns over data privacy. Federated learning (FL) is one potential pathway for AI development that enables learning across hospitals without data share. In this study, we show the results of various FL strategies on one of the largest and most diverse COVID-19 chest CT datasets: 21 participating hospitals across five continents that comprise >10,000 patients with >1 million images. We present three techniques: Fed Averaging (FedAvg), Incremental Institutional Learning (IIL), and Cyclical Incremental Institutional Learning (CIIL). We also propose an FL strategy that leverages synthetically generated data to overcome class imbalances and data size disparities across centers. We show that FL can achieve comparable performance to Centralized Data Sharing (CDS) while maintaining high performance across sites with small, underrepresented data. We investigate the strengths and weaknesses for all technical approaches on this heterogeneous dataset including the robustness to non-Independent and identically distributed (non-IID) diversity of data. We also describe the sources of data heterogeneity such as age, sex, and site locations in the context of FL and show how even among the correctly labeled populations, disparities can arise due to these biases.
Anonymizing Data for Privacy-Preserving Federated Learning
Feb 21, 2020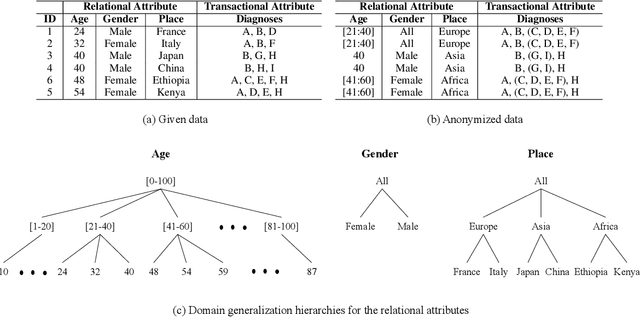
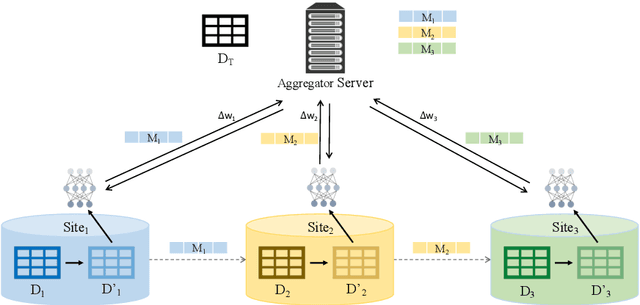
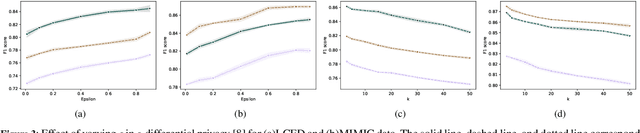
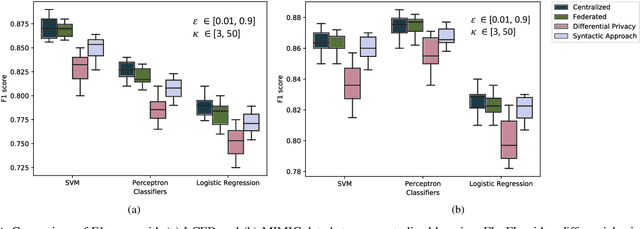
Federated learning enables training a global machine learning model from data distributed across multiple sites, without having to move the data. This is particularly relevant in healthcare applications, where data is rife with personal, highly-sensitive information, and data analysis methods must provably comply with regulatory guidelines. Although federated learning prevents sharing raw data, it is still possible to launch privacy attacks on the model parameters that are exposed during the training process, or on the generated machine learning model. In this paper, we propose the first syntactic approach for offering privacy in the context of federated learning. Unlike the state-of-the-art differential privacy-based frameworks, our approach aims to maximize utility or model performance, while supporting a defensible level of privacy, as demanded by GDPR and HIPAA. We perform a comprehensive empirical evaluation on two important problems in the healthcare domain, using real-world electronic health data of 1 million patients. The results demonstrate the effectiveness of our approach in achieving high model performance, while offering the desired level of privacy. Through comparative studies, we also show that, for varying datasets, experimental setups, and privacy budgets, our approach offers higher model performance than differential privacy-based techniques in federated learning.
Differential Privacy-enabled Federated Learning for Sensitive Health Data
Nov 14, 2019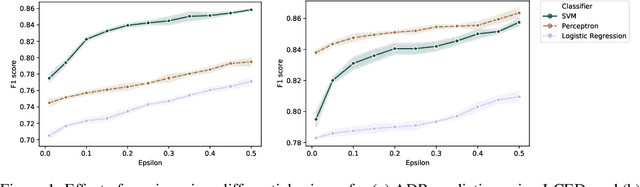
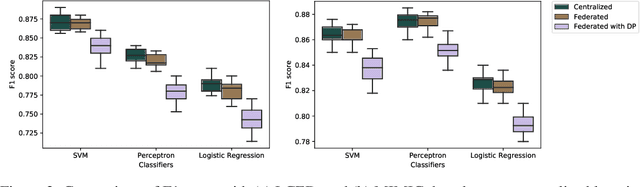
Leveraging real-world health data for machine learning tasks requires addressing many practical challenges, such as distributed data silos, privacy concerns with creating a centralized database from person-specific sensitive data, resource constraints for transferring and integrating data from multiple sites, and risk of a single point of failure. In this paper, we introduce a federated learning framework that can learn a global model from distributed health data held locally at different sites. The framework offers two levels of privacy protection. First, it does not move or share raw data across sites or with a centralized server during the model training process. Second, it uses a differential privacy mechanism to further protect the model from potential privacy attacks. We perform a comprehensive evaluation of our approach on two healthcare applications, using real-world electronic health data of 1 million patients. We demonstrate the feasibility and effectiveness of the federated learning framework in offering an elevated level of privacy and maintaining utility of the global model.