 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate, Adapt, Anonymize (3A): a Framework for Privacy Preserving Training Data Release for Machine Learning
Jul 04, 2023



The availability of large amounts of informative data is crucial for successful machine learning. However, in domains with sensitive information, the release of high-utility data which protects the privacy of individuals has proven challenging. Despite progress in differential privacy and generative modeling for privacy-preserving data release in the literature, only a few approaches optimize for machine learning utility: most approaches only take into account statistical metrics on the data itself and fail to explicitly preserve the loss metrics of machine learning models that are to be subsequently trained on the generated data. In this paper, we introduce a data release framework, 3A (Approximate, Adapt, Anonymize), to maximize data utility for machine learning, while preserving differential privacy. We also describe a specific implementation of this framework that leverages mixture models to approximate, kernel-inducing points to adapt, and Gaussian differential privacy to anonymize a dataset, in order to ensure that the resulting data is both privacy-preserving and high utility. We present experimental evidence showing minimal discrepancy between performance metrics of models trained on real versus privatized datasets, when evaluated on held-out real data. We also compare our results with several privacy-preserving synthetic data generation models (such as differentially private generative adversarial networks), and report significant increases in classification performance metrics compared to state-of-the-art models. These favorable comparisons show that the presented framework is a promising direction of research, increasing the utility of low-risk synthetic data release for machine learning.
* 10 pages, 3 figures, AAAI Workshop
Safe Semi-Supervised Learning of Sum-Product Networks
Oct 10, 2017
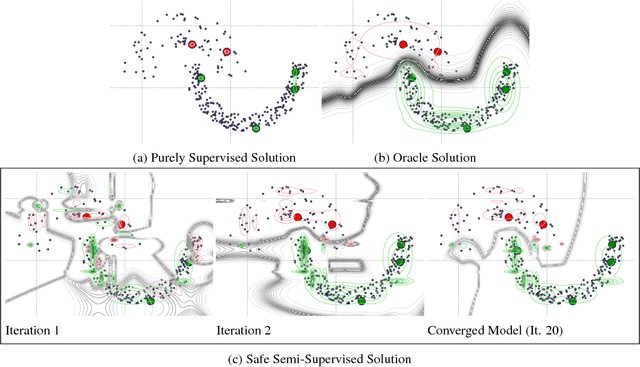
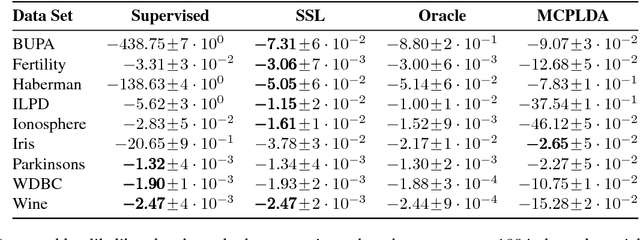
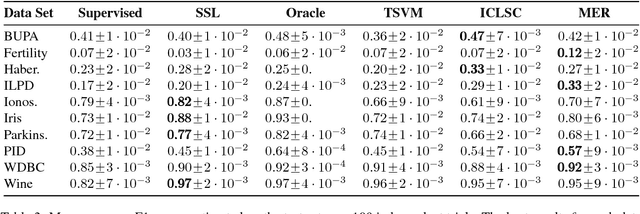
In several domains obtaining class annotations is expensive while at the same time unlabelled data are abundant. While most semi-supervised approaches enforce restrictive assumptions on the data distribution, recent work has managed to learn semi-supervised models in a non-restrictive regime. However, so far such approaches have only been proposed for linear models. In this work, we introduce semi-supervised parameter learning for Sum-Product Networks (SPNs). SPNs are deep probabilistic models admitting inference in linear time in number of network edges. Our approach has several advantages, as it (1) allows generative and discriminative semi-supervised learning, (2) guarantees that adding unlabelled data can increase, but not degrade, the performance (safe), and (3) is computationally efficient and does not enforce restrictive assumptions on the data distribution. We show on a variety of data sets that safe semi-supervised learning with SPNs is competitive compared to state-of-the-art and can lead to a better generative and discriminative objective value than a purely supervised approach.
Deep neural heart rate variability analysis
Dec 29, 2016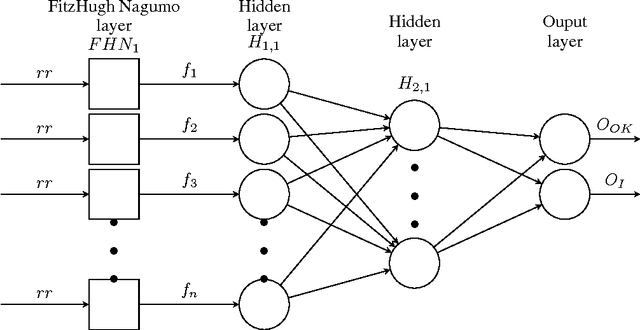


Despite of the pain and limited accuracy of blood tests for early recognition of cardiovascular disease, they dominate risk screening and triage. On the other hand, heart rate variability is non-invasive and cheap, but not considered accurate enough for clinical practice. Here, we tackle heart beat interval based classification with deep learning. We introduce an end to end differentiable hybrid architecture, consisting of a layer of biological neuron models of cardiac dynamics (modified FitzHugh Nagumo neurons) and several layers of a standard feed-forward neural network. The proposed model is evaluated on ECGs from 474 stable at-risk (coronary artery disease) patients, and 1172 chest pain patients of an emergency department. We show that it can significantly outperform models based on traditional heart rate variability predictors, as well as approaching or in some cases outperforming clinical blood tests, based only on 60 seconds of inter-beat intervals.