 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing In-context Learning via Linear Probe Calibration
Jan 22, 2024In-context learning (ICL) is a new paradigm for natural language processing that utilizes Generative Pre-trained Transformer (GPT)-like models. This approach uses prompts that include in-context demonstrations to generate the corresponding output for a new query input. However, applying ICL in real cases does not scale with the number of samples, and lacks robustness to different prompt templates and demonstration permutations. In this paper, we first show that GPT-like models using ICL result in unreliable predictions based on a new metric based on Shannon entropy. Then, to solve this problem, we propose a new technique called the Linear Probe Calibration (LinC), a method that calibrates the model's output probabilities, resulting in reliable predictions and improved performance, while requiring only minimal additional samples (as few as five labeled data samples). LinC significantly enhances the ICL test performance of GPT models on various benchmark datasets, with an average improvement of up to 21%, and up to a 50% improvement in some cases, and significantly boosts the performance of PEFT methods, especially in the low resource regime. Moreover, LinC achieves lower expected calibration error, and is highly robust to varying label proportions, prompt templates, and demonstration permutations. Our code is available at \url{https://github.com/mominabbass/LinC}.
Single-shot Hyper-parameter Optimization for Federated Learning: A General Algorithm & Analysis
Feb 16, 2022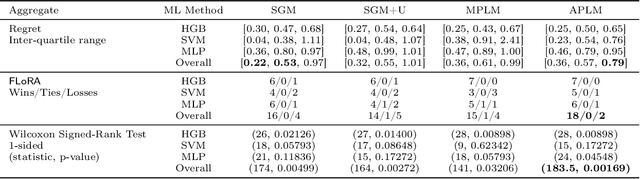
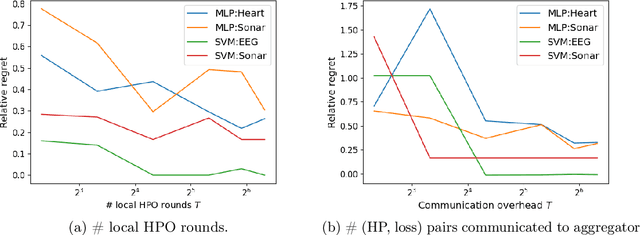
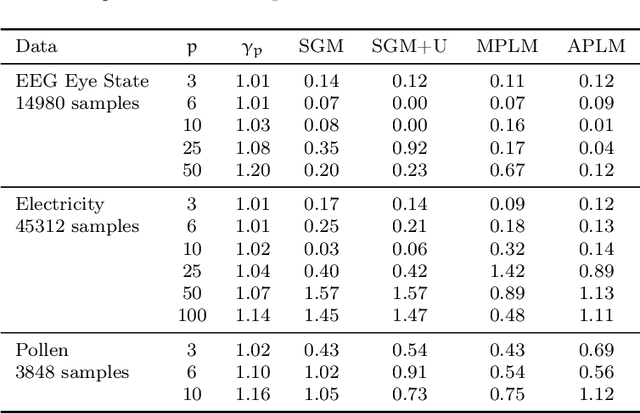

We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss SuRface Aggregation (FLoRA), a general FL-HPO solution framework that can address use cases of tabular data and any Machine Learning (ML) model including gradient boosting training algorithms and therefore further expands the scope of FL-HPO. FLoRA enables single-shot FL-HPO: identifying a single set of good hyper-parameters that are subsequently used in a single FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. We theoretically characterize the optimality gap of FL-HPO, which explicitly accounts for the heterogeneous non-IID nature of the parties' local data distributions, a dominant characteristic of FL systems. Our empirical evaluation of FLoRA for multiple ML algorithms on seven OpenML datasets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
FLoRA: Single-shot Hyper-parameter Optimization for Federated Learning
Dec 15, 2021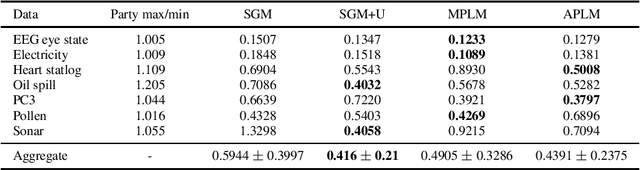
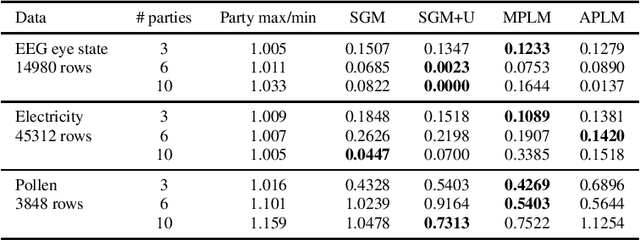

We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss suRface Aggregation (FLoRA), the first FL-HPO solution framework that can address use cases of tabular data and gradient boosting training algorithms in addition to stochastic gradient descent/neural networks commonly addressed in the FL literature. The framework enables single-shot FL-HPO, by first identifying a good set of hyper-parameters that are used in a **single** FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. Our empirical evaluation of FLoRA for Gradient Boosted Decision Trees on seven OpenML data sets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
Anonymizing Data for Privacy-Preserving Federated Learning
Feb 21, 2020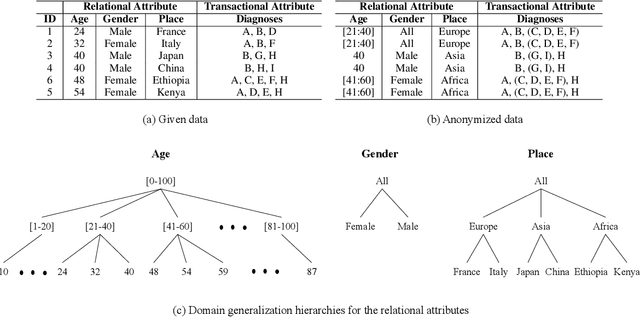
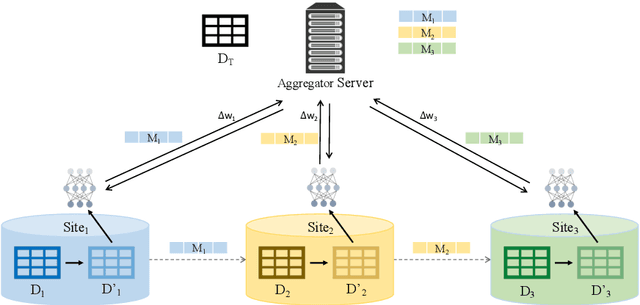
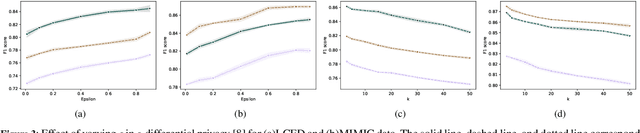
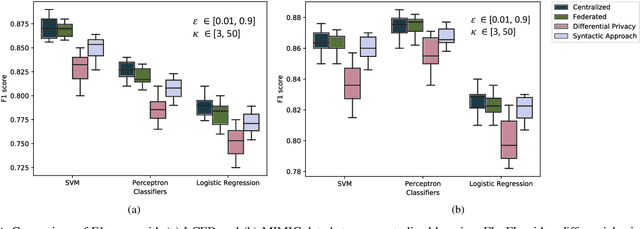
Federated learning enables training a global machine learning model from data distributed across multiple sites, without having to move the data. This is particularly relevant in healthcare applications, where data is rife with personal, highly-sensitive information, and data analysis methods must provably comply with regulatory guidelines. Although federated learning prevents sharing raw data, it is still possible to launch privacy attacks on the model parameters that are exposed during the training process, or on the generated machine learning model. In this paper, we propose the first syntactic approach for offering privacy in the context of federated learning. Unlike the state-of-the-art differential privacy-based frameworks, our approach aims to maximize utility or model performance, while supporting a defensible level of privacy, as demanded by GDPR and HIPAA. We perform a comprehensive empirical evaluation on two important problems in the healthcare domain, using real-world electronic health data of 1 million patients. The results demonstrate the effectiveness of our approach in achieving high model performance, while offering the desired level of privacy. Through comparative studies, we also show that, for varying datasets, experimental setups, and privacy budgets, our approach offers higher model performance than differential privacy-based techniques in federated learning.
Differential Privacy-enabled Federated Learning for Sensitive Health Data
Nov 14, 2019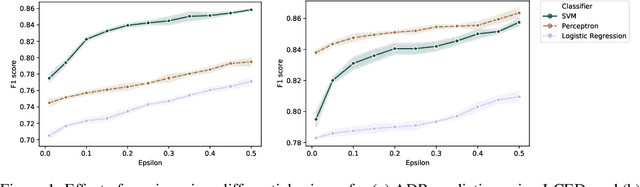
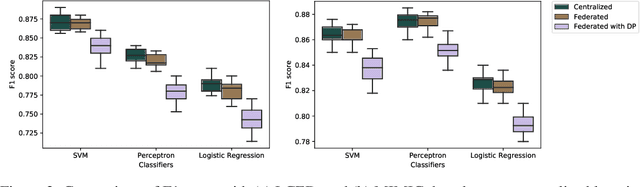
Leveraging real-world health data for machine learning tasks requires addressing many practical challenges, such as distributed data silos, privacy concerns with creating a centralized database from person-specific sensitive data, resource constraints for transferring and integrating data from multiple sites, and risk of a single point of failure. In this paper, we introduce a federated learning framework that can learn a global model from distributed health data held locally at different sites. The framework offers two levels of privacy protection. First, it does not move or share raw data across sites or with a centralized server during the model training process. Second, it uses a differential privacy mechanism to further protect the model from potential privacy attacks. We perform a comprehensive evaluation of our approach on two healthcare applications, using real-world electronic health data of 1 million patients. We demonstrate the feasibility and effectiveness of the federated learning framework in offering an elevated level of privacy and maintaining utility of the global model.
Adaptive Federated Learning in Resource Constrained Edge Computing Systems
Aug 02, 2018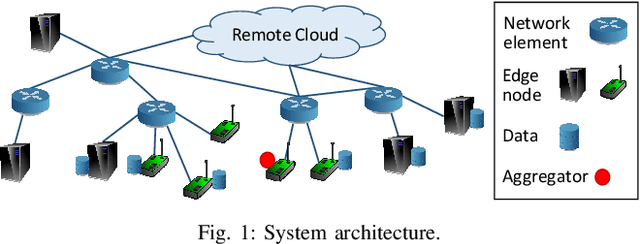
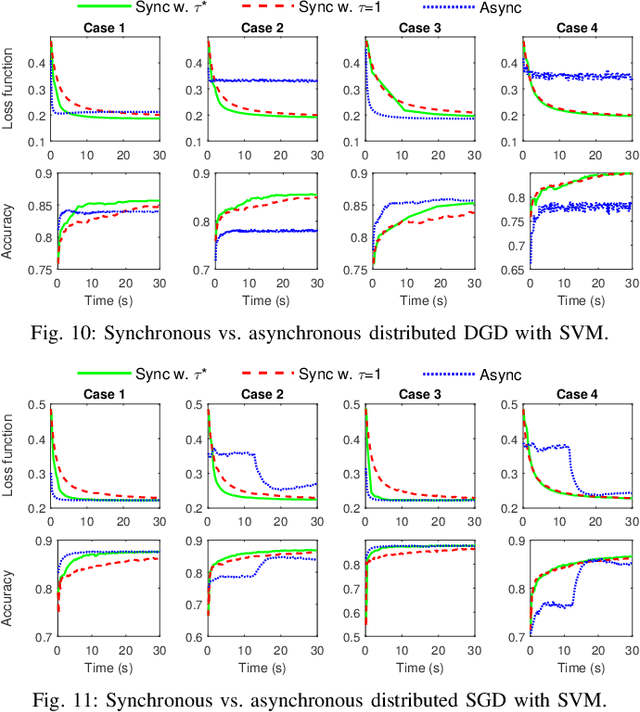
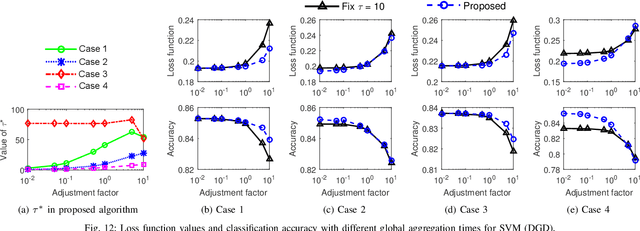
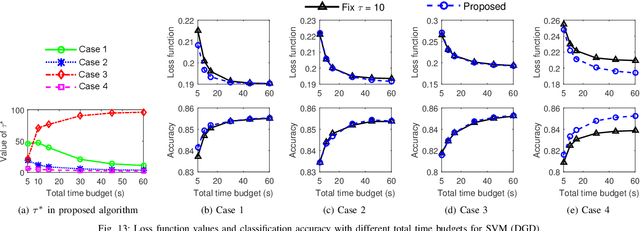
Emerging technologies and applications including Internet of Things (IoT), social networking, and crowd-sourcing generate large amounts of data at the network edge. Machine learning models are often built from the collected data, to enable the detection, classification, and prediction of future events. Due to bandwidth, storage, and privacy concerns, it is often impractical to send all the data to a centralized location. In this paper, we consider the problem of learning model parameters from data distributed across multiple edge nodes, without sending raw data to a centralized place. Our focus is on a generic class of machine learning models that are trained using gradient-descent based approaches. We analyze the convergence bound of distributed gradient descent from a theoretical point of view, based on which we propose a control algorithm that determines the best trade-off between local update and global parameter aggregation to minimize the loss function under a given resource budget. The performance of the proposed algorithm is evaluated via extensive experiments with real datasets, both on a networked prototype system and in a larger-scale simulated environment. The experimentation results show that our proposed approach performs near to the optimum with various machine learning models and different data distributions.