 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotonic Quantum-Enhanced Knowledge Distillation
Mar 16, 2026Photonic quantum processors naturally produce intrinsically stochastic measurement outcomes, offering a hardware-native source of structured randomness that can be exploited during machine-learning training. Here we introduce Photonic Quantum-Enhanced Knowledge Distillation (PQKD), a hybrid quantum photonic--classical framework in which a programmable photonic circuit generates a compact conditioning signal that constrains and guides a parameter-efficient student network during distillation from a high-capacity teacher. PQKD replaces fully trainable convolutional kernels with dictionary convolutions: each layer learns only a small set of shared spatial basis filters, while sample-dependent channel-mixing weights are derived from shot-limited photonic features and mapped through a fixed linear transform. Training alternates between standard gradient-based optimisation of the student and sampling-robust, gradient-free updates of photonic parameters, avoiding differentiation through photonic hardware. Across MNIST, Fashion-MNIST and CIFAR-10, PQKD traces a controllable compression--accuracy frontier, remaining close to teacher performance on simpler benchmarks under aggressive convolutional compression. Performance degrades predictably with finite sampling, consistent with shot-noise scaling, and exponential moving-average feature smoothing suppresses high-frequency shot-noise fluctuations, extending the practical operating regime at moderate shot budgets.
Distributed Quantum Neural Networks on Distributed Photonic Quantum Computing
May 13, 2025We introduce a distributed quantum-classical framework that synergizes photonic quantum neural networks (QNNs) with matrix-product-state (MPS) mapping to achieve parameter-efficient training of classical neural networks. By leveraging universal linear-optical decompositions of $M$-mode interferometers and photon-counting measurement statistics, our architecture generates neural parameters through a hybrid quantum-classical workflow: photonic QNNs with $M(M+1)/2$ trainable parameters produce high-dimensional probability distributions that are mapped to classical network weights via an MPS model with bond dimension $\chi$. Empirical validation on MNIST classification demonstrates that photonic QT achieves an accuracy of $95.50\% \pm 0.84\%$ using 3,292 parameters ($\chi = 10$), compared to $96.89\% \pm 0.31\%$ for classical baselines with 6,690 parameters. Moreover, a ten-fold compression ratio is achieved at $\chi = 4$, with a relative accuracy loss of less than $3\%$. The framework outperforms classical compression techniques (weight sharing/pruning) by 6--12\% absolute accuracy while eliminating quantum hardware requirements during inference through classical deployment of compressed parameters. Simulations incorporating realistic photonic noise demonstrate the framework's robustness to near-term hardware imperfections. Ablation studies confirm quantum necessity: replacing photonic QNNs with random inputs collapses accuracy to chance level ($10.0\% \pm 0.5\%$). Photonic quantum computing's room-temperature operation, inherent scalability through spatial-mode multiplexing, and HPC-integrated architecture establish a practical pathway for distributed quantum machine learning, combining the expressivity of photonic Hilbert spaces with the deployability of classical neural networks.
Belief States for Cooperative Multi-Agent Reinforcement Learning under Partial Observability
Apr 11, 2025Reinforcement learning in partially observable environments is typically challenging, as it requires agents to learn an estimate of the underlying system state. These challenges are exacerbated in multi-agent settings, where agents learn simultaneously and influence the underlying state as well as each others' observations. We propose the use of learned beliefs on the underlying state of the system to overcome these challenges and enable reinforcement learning with fully decentralized training and execution. Our approach leverages state information to pre-train a probabilistic belief model in a self-supervised fashion. The resulting belief states, which capture both inferred state information as well as uncertainty over this information, are then used in a state-based reinforcement learning algorithm to create an end-to-end model for cooperative multi-agent reinforcement learning under partial observability. By separating the belief and reinforcement learning tasks, we are able to significantly simplify the policy and value function learning tasks and improve both the convergence speed and the final performance. We evaluate our proposed method on diverse partially observable multi-agent tasks designed to exhibit different variants of partial observability.
Toward Large-Scale Distributed Quantum Long Short-Term Memory with Modular Quantum Computers
Mar 18, 2025In this work, we introduce a Distributed Quantum Long Short-Term Memory (QLSTM) framework that leverages modular quantum computing to address scalability challenges on Noisy Intermediate-Scale Quantum (NISQ) devices. By embedding variational quantum circuits into LSTM cells, the QLSTM captures long-range temporal dependencies, while a distributed architecture partitions the underlying Variational Quantum Circuits (VQCs) into smaller, manageable subcircuits that can be executed on a network of quantum processing units. We assess the proposed framework using nontrivial benchmark problems such as damped harmonic oscillators and Nonlinear Autoregressive Moving Average sequences. Our results demonstrate that the distributed QLSTM achieves stable convergence and improved training dynamics compared to classical approaches. This work underscores the potential of modular, distributed quantum computing architectures for large-scale sequence modelling, providing a foundation for the future integration of hybrid quantum-classical solutions into advanced Quantum High-performance computing (HPC) ecosystems.
Ultra-Low-Latency Edge Intelligent Sensing: A Source-Channel Tradeoff and Its Application to Coding Rate Adaptation
Mar 06, 2025The forthcoming sixth-generation (6G) mobile network is set to merge edge artificial intelligence (AI) and integrated sensing and communication (ISAC) extensively, giving rise to the new paradigm of edge intelligent sensing (EI-Sense). This paradigm leverages ubiquitous edge devices for environmental sensing and deploys AI algorithms at edge servers to interpret the observations via remote inference on wirelessly uploaded features. A significant challenge arises in designing EI-Sense systems for 6G mission-critical applications, which demand high performance under stringent latency constraints. To tackle this challenge, we focus on the end-to-end (E2E) performance of EI-Sense and characterize a source-channel tradeoff that balances source distortion and channel reliability. In this work, we establish a theoretical foundation for the source-channel tradeoff by quantifying the effects of source coding on feature discriminant gains and channel reliability on packet loss. Building on this foundation, we design the coding rate control by optimizing the tradeoff to minimize the E2E sensing error probability, leading to a low-complexity algorithm for ultra-low-latency EI-Sense. Finally, we validate our theoretical analysis and proposed coding rate control algorithm through extensive experiments on both synthetic and real datasets, demonstrating the sensing performance gain of our approach with respect to traditional reliability-centric methods.
DRL-based Dolph-Tschebyscheff Beamforming in Downlink Transmission for Mobile Users
Feb 03, 2025



With the emergence of AI technologies in next-generation communication systems, machine learning plays a pivotal role due to its ability to address high-dimensional, non-stationary optimization problems within dynamic environments while maintaining computational efficiency. One such application is directional beamforming, achieved through learning-based blind beamforming techniques that utilize already existing radio frequency (RF) fingerprints of the user equipment obtained from the base stations and eliminate the need for additional hardware or channel and angle estimations. However, as the number of users and antenna dimensions increase, thereby expanding the problem's complexity, the learning process becomes increasingly challenging, and the performance of the learning-based method cannot match that of the optimal solution. In such a scenario, we propose a deep reinforcement learning-based blind beamforming technique using a learnable Dolph-Tschebyscheff antenna array that can change its beam pattern to accommodate mobile users. Our simulation results show that the proposed method can support data rates very close to the best possible values.
Quantum-Train-Based Distributed Multi-Agent Reinforcement Learning
Dec 12, 2024


In this paper, we introduce Quantum-Train-Based Distributed Multi-Agent Reinforcement Learning (Dist-QTRL), a novel approach to addressing the scalability challenges of traditional Reinforcement Learning (RL) by integrating quantum computing principles. Quantum-Train Reinforcement Learning (QTRL) leverages parameterized quantum circuits to efficiently generate neural network parameters, achieving a \(poly(\log(N))\) reduction in the dimensionality of trainable parameters while harnessing quantum entanglement for superior data representation. The framework is designed for distributed multi-agent environments, where multiple agents, modeled as Quantum Processing Units (QPUs), operate in parallel, enabling faster convergence and enhanced scalability. Additionally, the Dist-QTRL framework can be extended to high-performance computing (HPC) environments by utilizing distributed quantum training for parameter reduction in classical neural networks, followed by inference using classical CPUs or GPUs. This hybrid quantum-HPC approach allows for further optimization in real-world applications. In this paper, we provide a mathematical formulation of the Dist-QTRL framework and explore its convergence properties, supported by empirical results demonstrating performance improvements over centric QTRL models. The results highlight the potential of quantum-enhanced RL in tackling complex, high-dimensional tasks, particularly in distributed computing settings, where our framework achieves significant speedups through parallelization without compromising model accuracy. This work paves the way for scalable, quantum-enhanced RL systems in practical applications, leveraging both quantum and classical computational resources.
AdaptSFL: Adaptive Split Federated Learning in Resource-constrained Edge Networks
Mar 19, 2024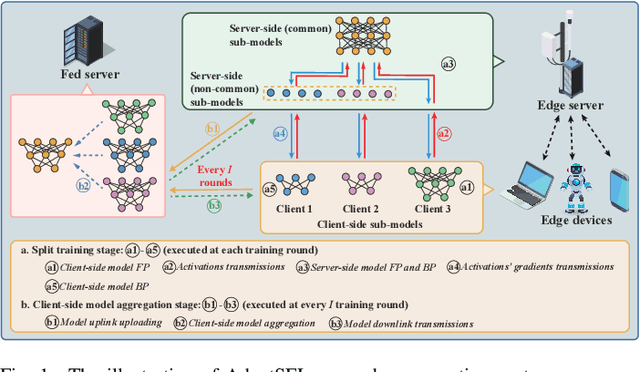
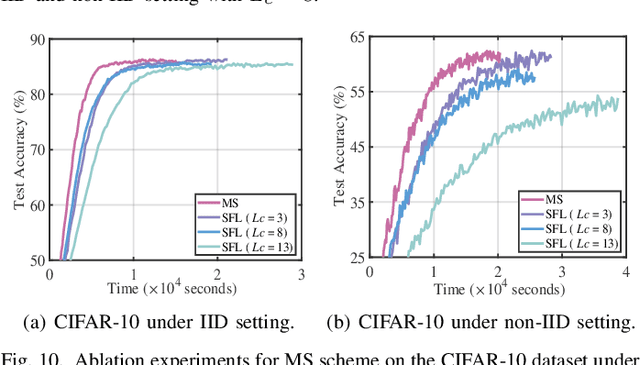
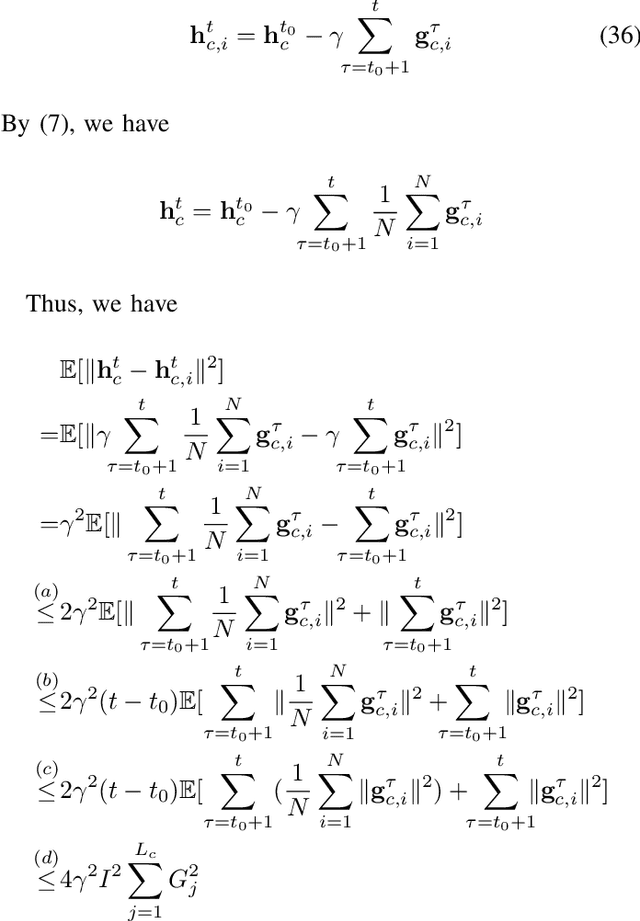
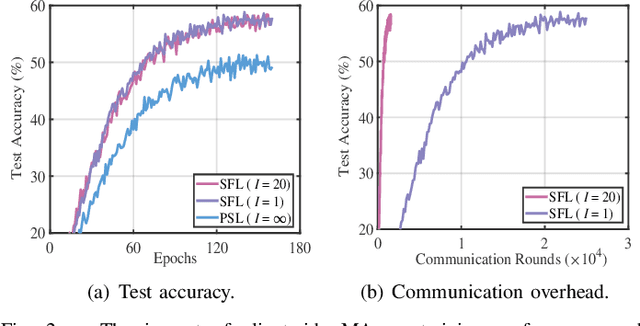
The increasing complexity of deep neural networks poses significant barriers to democratizing them to resource-limited edge devices. To address this challenge, split federated learning (SFL) has emerged as a promising solution by of floading the primary training workload to a server via model partitioning while enabling parallel training among edge devices. However, although system optimization substantially influences the performance of SFL under resource-constrained systems, the problem remains largely uncharted. In this paper, we provide a convergence analysis of SFL which quantifies the impact of model splitting (MS) and client-side model aggregation (MA) on the learning performance, serving as a theoretical foundation. Then, we propose AdaptSFL, a novel resource-adaptive SFL framework, to expedite SFL under resource-constrained edge computing systems. Specifically, AdaptSFL adaptively controls client-side MA and MS to balance communication-computing latency and training convergence. Extensive simulations across various datasets validate that our proposed AdaptSFL framework takes considerably less time to achieve a target accuracy than benchmarks, demonstrating the effectiveness of the proposed strategies.
Joint State-Action Embedding for Efficient Reinforcement Learning
Oct 12, 2020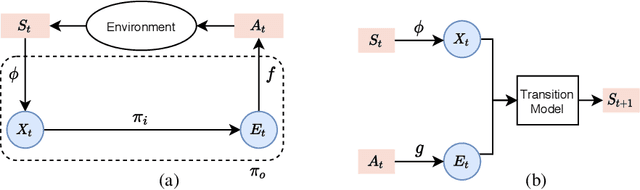
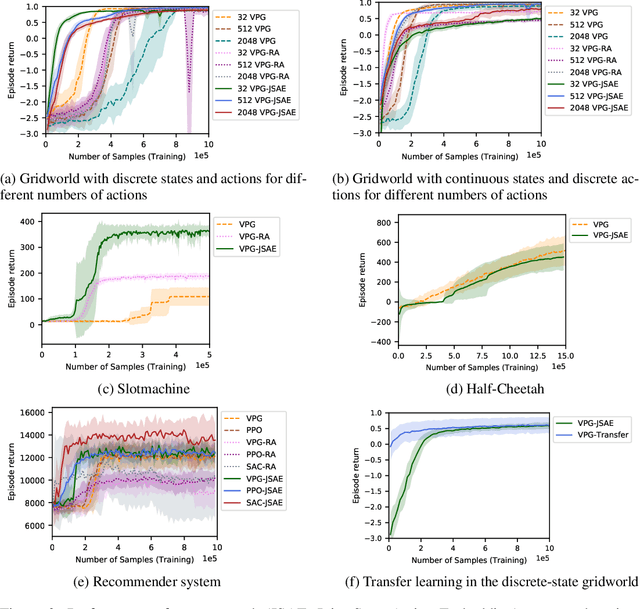
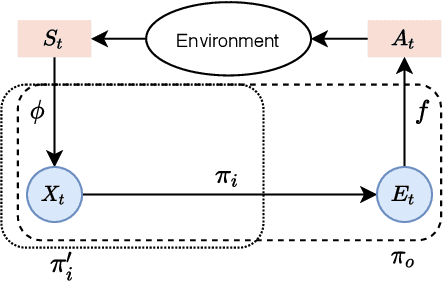
While reinforcement learning has achieved considerable successes in recent years, state-of-the-art models are often still limited by the size of state and action spaces. Model-free reinforcement learning approaches use some form of state representations and the latest work has explored embedding techniques for actions, both with the aim of achieving better generalization and applicability. However, these approaches consider only states or actions, ignoring the interaction between them when generating embedded representations. In this work, we propose a new approach for jointly embedding states and actions that combines aspects of model-free and model-based reinforcement learning, which can be applied in both discrete and continuous domains. Specifically, we use a model of the environment to obtain embeddings for states and actions and present a generic architecture that uses these to learn a policy. In this way, the embedded representations obtained via our approach enable better generalization over both states and actions by capturing similarities in the embedding spaces. Evaluations of our approach on several gaming and recommender system environments show it significantly outperforms state-of-the-art models in discrete domains with large state/action space, thus confirming the efficacy of joint embedding and its overall superior performance.
State Action Separable Reinforcement Learning
Jun 05, 2020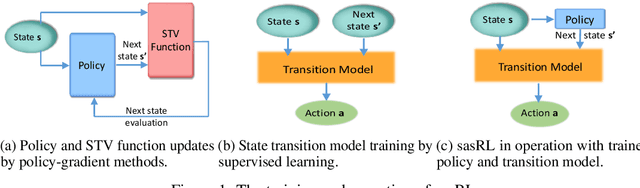
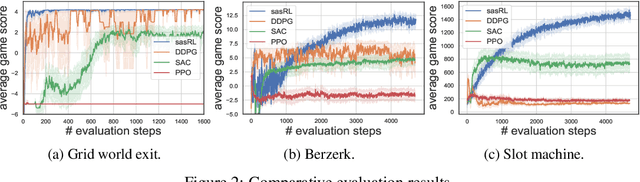
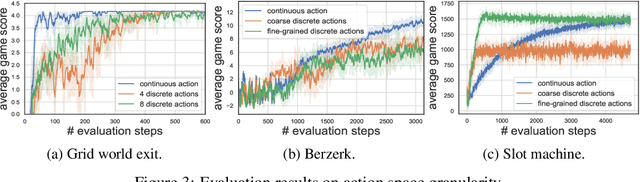
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.