 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Feature Imputing - A Technique for Error-resilient Semantic Communication
Aug 25, 2025Semantic communication (SemCom) has emerged as a promising paradigm for achieving unprecedented communication efficiency in sixth-generation (6G) networks by leveraging artificial intelligence (AI) to extract and transmit the underlying meanings of source data. However, deploying SemCom over digital systems presents new challenges, particularly in ensuring robustness against transmission errors that may distort semantically critical content. To address this issue, this paper proposes a novel framework, termed generative feature imputing, which comprises three key techniques. First, we introduce a spatial error concentration packetization strategy that spatially concentrates feature distortions by encoding feature elements based on their channel mappings, a property crucial for both the effectiveness and reduced complexity of the subsequent techniques. Second, building on this strategy, we propose a generative feature imputing method that utilizes a diffusion model to efficiently reconstruct missing features caused by packet losses. Finally, we develop a semantic-aware power allocation scheme that enables unequal error protection by allocating transmission power according to the semantic importance of each packet. Experimental results demonstrate that the proposed framework outperforms conventional approaches, such as Deep Joint Source-Channel Coding (DJSCC) and JPEG2000, under block fading conditions, achieving higher semantic accuracy and lower Learned Perceptual Image Patch Similarity (LPIPS) scores.
In-Memory Computing Enabled Deep MIMO Detection to Support Ultra-Low-Latency Communications
Aug 25, 2025The development of sixth-generation (6G) mobile networks imposes unprecedented latency and reliability demands on multiple-input multiple-output (MIMO) communication systems, a key enabler of high-speed radio access. Recently, deep unfolding-based detectors, which map iterative algorithms onto neural network architectures, have emerged as a promising approach, combining the strengths of model-driven and data-driven methods to achieve high detection accuracy with relatively low complexity. However, algorithmic innovation alone is insufficient; software-hardware co-design is essential to meet the extreme latency requirements of 6G (i.e., 0.1 milliseconds). This motivates us to propose leveraging in-memory computing, which is an analog computing technology that integrates memory and computation within memristor circuits, to perform the intensive matrix-vector multiplication (MVM) operations inherent in deep MIMO detection at the nanosecond scale. Specifically, we introduce a novel architecture, called the deep in-memory MIMO (IM-MIMO) detector, characterized by two key features. First, each of its cascaded computational blocks is decomposed into channel-dependent and channel-independent neural network modules. Such a design minimizes the latency of memristor reprogramming in response to channel variations, which significantly exceeds computation time. Second, we develop a customized detector-training method that exploits prior knowledge of memristor-value statistics to enhance robustness against programming noise. Furthermore, we conduct a comprehensive analysis of the IM-MIMO detector's performance, evaluating detection accuracy, processing latency, and hardware complexity. Our study quantifies detection error as a function of various factors, including channel noise, memristor programming noise, and neural network size.
Rydberg Atomic Receivers for Multi-Band Communications and Sensing
May 30, 2025Harnessing multi-level electron transitions, Rydberg Atomic Receivers (RAREs) can detect wireless signals across a wide range of frequency bands, from Megahertz to Terahertz, enabling multi-band communications and sensing (C&S). Current research on multi-band RAREs primarily focuses on experimental demonstrations, lacking an interpretable model to mathematically characterize their mechanisms. This issue leaves the multi-band RARE as a black box, posing challenges in its practical C&S applications. To fill in this gap, this paper investigates the underlying mechanism of multi-band RAREs and explores their optimal performance. For the first time, the closed-form expression of the transfer function of a multi-band RARE is derived by solving the quantum response of Rydberg atoms excited by multi-band signals. The function reveals that a multiband RARE simultaneously serves as both a multi-band atomic mixer for down-converting multi-band signals and a multi-band atomic amplifier that reflects its sensitivity to each band. Further analysis of the atomic amplifier unveils that the gain factor at each frequency band can be decoupled into a global gain term and a Rabi attention term. The former determines the overall sensitivity of a RARE to all frequency bands of wireless signals. The latter influences the allocation of the overall sensitivity to each frequency band, representing a unique attention mechanism of multi-band RAREs. The optimal design of the global gain is provided to maximize the overall sensitivity of multi-band RAREs. Subsequently, the optimal Rabi attentions are also derived to maximize the practical multi-band C&S performance. Numerical results confirm the effectiveness of the derived transfer function and the superiority of multi-band RAREs.
Visual Fidelity Index for Generative Semantic Communications with Critical Information Embedding
May 15, 2025


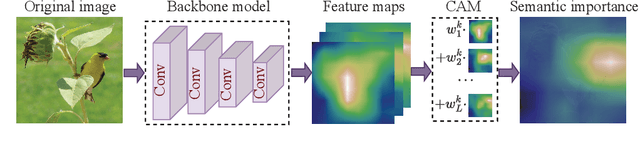
Generative semantic communication (Gen-SemCom) with large artificial intelligence (AI) model promises a transformative paradigm for 6G networks, which reduces communication costs by transmitting low-dimensional prompts rather than raw data. However, purely prompt-driven generation loses fine-grained visual details. Additionally, there is a lack of systematic metrics to evaluate the performance of Gen-SemCom systems. To address these issues, we develop a hybrid Gen-SemCom system with a critical information embedding (CIE) framework, where both text prompts and semantically critical features are extracted for transmissions. First, a novel approach of semantic filtering is proposed to select and transmit the semantically critical features of images relevant to semantic label. By integrating the text prompt and critical features, the receiver reconstructs high-fidelity images using a diffusion-based generative model. Next, we propose the generative visual information fidelity (GVIF) metric to evaluate the visual quality of the generated image. By characterizing the statistical models of image features, the GVIF metric quantifies the mutual information between the distorted features and their original counterparts. By maximizing the GVIF metric, we design a channel-adaptive Gen-SemCom system that adaptively control the volume of features and compression rate according to the channel state. Experimental results validate the GVIF metric's sensitivity to visual fidelity, correlating with both the PSNR and critical information volume. In addition, the optimized system achieves superior performance over benchmarking schemes in terms of higher PSNR and lower FID scores.
Ultra-Low-Latency Edge Intelligent Sensing: A Source-Channel Tradeoff and Its Application to Coding Rate Adaptation
Mar 06, 2025The forthcoming sixth-generation (6G) mobile network is set to merge edge artificial intelligence (AI) and integrated sensing and communication (ISAC) extensively, giving rise to the new paradigm of edge intelligent sensing (EI-Sense). This paradigm leverages ubiquitous edge devices for environmental sensing and deploys AI algorithms at edge servers to interpret the observations via remote inference on wirelessly uploaded features. A significant challenge arises in designing EI-Sense systems for 6G mission-critical applications, which demand high performance under stringent latency constraints. To tackle this challenge, we focus on the end-to-end (E2E) performance of EI-Sense and characterize a source-channel tradeoff that balances source distortion and channel reliability. In this work, we establish a theoretical foundation for the source-channel tradeoff by quantifying the effects of source coding on feature discriminant gains and channel reliability on packet loss. Building on this foundation, we design the coding rate control by optimizing the tradeoff to minimize the E2E sensing error probability, leading to a low-complexity algorithm for ultra-low-latency EI-Sense. Finally, we validate our theoretical analysis and proposed coding rate control algorithm through extensive experiments on both synthetic and real datasets, demonstrating the sensing performance gain of our approach with respect to traditional reliability-centric methods.
Rydberg Atomic Receiver: Next Frontier of Wireless Communications
Dec 17, 2024



The advancement of Rydberg Atomic REceiver (RARE) is driving a paradigm shift in electromagnetic (EM) wave measurement. RAREs utilize the electron transition phenomenon of highly-excited atoms to interact with EM waves, thereby enabling wireless signal detection. Operating at the quantum scale, such new receivers have the potential to breakthrough the sensitivity limit of classical receivers, sparking a revolution in physical-layer wireless communications. The objective of this paper is to offer insights into RARE-aided communication systems. We first provide a comprehensive introduction to the fundamental principles of RAREs. Then, a thorough comparison between RAREs and classical receivers is conducted in terms of the antenna size, sensitivity, coverage, and bandwidth. Subsequently, we overview the state-of-the-art design in RARE-aided wireless communications, exploring the latest progresses in frequency-division multiplexing, multiple-input-multiple-output, wireless sensing, and quantum many-body techniques. Finally, we highlight several wireless-communication related open problems as important research directions.
Towards ubiquitous radio access using nanodiamond based quantum receivers
Sep 28, 2024The development of sixth-generation (6G) wireless communication systems demands innovative solutions to address challenges in the deployment of a large number of base stations and the detection of multi-band signals. Quantum technology, specifically nitrogen vacancy (NV) centers in diamonds, offers promising potential for the development of compact, robust receivers capable of supporting multiple users. For the first time, we propose a multiple access scheme using fluorescent nanodiamonds (FNDs) containing NV centers as nano-antennas. The unique response of each FND to applied microwaves allows for distinguishable patterns of fluorescence intensities, enabling multi-user signal demodulation. We demonstrate the effectiveness of our FNDs-implemented receiver by simultaneously transmitting two uncoded digitally modulated information bit streams from two separate transmitters, achieving a low bit error ratio. Moreover, our design supports tunable frequency band communication and reference-free signal decoupling, reducing communication overhead. Furthermore, we implement a miniaturized device comprising all essential components, highlighting its practicality as a receiver serving multiple users simultaneously. This approach paves the way for the integration of quantum sensing technologies in future 6G wireless communication networks.
IQ-aware precoding for atomic MIMO receivers
Aug 26, 2024Leveraging the strong atom-light interaction, Rydberg atomic receivers significantly enhance the sensitivity of electromagnetic signal measurements, outperforming traditional antennas. Existing research primarily focuses on improving the architecture and signal detection algorithms of atomic receivers, while established signal processing schemes at the transmitter end have remained constant. However, these schemes fail to maximize the throughput of atomic receivers due to the nonlinearity of transmission model. To address this issue, we propose to design transmitter precoding in multiple-input multiple-output systems to achieve the capacity of atomic receivers. Initially, we harness a strong reference approximation to convert the nonlinear magnitude-detection model of atomic receivers into a linear real-part detector. Based on this approximation, we prove that the degree of freedom is min{Nr/2,Nt} for a MIMO system comprising an Nr-antenna atomic receiver and an Nt-antenna classic transmitter. To achieve the system capacity, we propose an IQ-aware fully digital precoding method. Unlike traditional complex-valued digital precoders that jointly manipulate the inphase and quadrature (IQ) symbols, our method employs four real matrices to independently precode the IQ baseband symbols, which is shown to be optimal for atomic receivers. Then, to eliminate the reliance on fully digital precoding architecture, we further explore IQ-aware hybrid precoding techniques. Our design incorporates a low-dimensional IQ-aware digital precoder and a high-dimensional complex analog precoder. Alternating minimization algorithms are proposed to produce IQ-aware hybrid precoders, with the objective of approaching the optimal IQ-aware fully digital precoder. Simulation results validate the superiority of proposed IQ-aware precoding methods over existing techniques in atomic MIMO communications.
Realizing In-Memory Baseband Processing for Ultra-Fast and Energy-Efficient 6G
Aug 19, 2023To support emerging applications ranging from holographic communications to extended reality, next-generation mobile wireless communication systems require ultra-fast and energy-efficient baseband processors. Traditional complementary metal-oxide-semiconductor (CMOS)-based baseband processors face two challenges in transistor scaling and the von Neumann bottleneck. To address these challenges, in-memory computing-based baseband processors using resistive random-access memory (RRAM) present an attractive solution. In this paper, we propose and demonstrate RRAM-implemented in-memory baseband processing for the widely adopted multiple-input-multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) air interface. Its key feature is to execute the key operations, including discrete Fourier transform (DFT) and MIMO detection using linear minimum mean square error (L-MMSE) and zero forcing (ZF), in one-step. In addition, RRAM-based channel estimation module is proposed and discussed. By prototyping and simulations, we demonstrate the feasibility of RRAM-based full-fledged communication system in hardware, and reveal it can outperform state-of-the-art baseband processors with a gain of 91.2$\times$ in latency and 671$\times$ in energy efficiency by large-scale simulations. Our results pave a potential pathway for RRAM-based in-memory computing to be implemented in the era of the sixth generation (6G) mobile communications.
Efficient Multiuser AI Downloading via Reusable Knowledge Broadcasting
Jul 28, 2023For the 6G mobile networks, in-situ model downloading has emerged as an important use case to enable real-time adaptive artificial intelligence on edge devices. However, the simultaneous downloading of diverse and high-dimensional models to multiple devices over wireless links presents a significant communication bottleneck. To overcome the bottleneck, we propose the framework of model broadcasting and assembling (MBA), which represents the first attempt on leveraging reusable knowledge, referring to shared parameters among tasks, to enable parameter broadcasting to reduce communication overhead. The MBA framework comprises two key components. The first, the MBA protocol, defines the system operations including parameter selection from a model library, power control for broadcasting, and model assembling at devices. The second component is the joint design of parameter-selection-and-power-control (PS-PC), which provides guarantees on devices' model performance and minimizes the downloading latency. The corresponding optimization problem is simplified by decomposition into the sequential PS and PC sub-problems without compromising its optimality. The PS sub-problem is solved efficiently by designing two efficient algorithms. On one hand, the low-complexity algorithm of greedy parameter selection features the construction of candidate model sets and a selection metric, both of which are designed under the criterion of maximum reusable knowledge among tasks. On the other hand, the optimal tree-search algorithm gains its efficiency via the proposed construction of a compact binary tree pruned using model architecture constraints and an intelligent branch-and-bound search. Given optimal PS, the optimal PC policy is derived in closed form. Extensive experiments demonstrate the substantial reduction in downloading latency achieved by the proposed MBA compared to traditional model downloading.