 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRL-based Dolph-Tschebyscheff Beamforming in Downlink Transmission for Mobile Users
Feb 03, 2025



With the emergence of AI technologies in next-generation communication systems, machine learning plays a pivotal role due to its ability to address high-dimensional, non-stationary optimization problems within dynamic environments while maintaining computational efficiency. One such application is directional beamforming, achieved through learning-based blind beamforming techniques that utilize already existing radio frequency (RF) fingerprints of the user equipment obtained from the base stations and eliminate the need for additional hardware or channel and angle estimations. However, as the number of users and antenna dimensions increase, thereby expanding the problem's complexity, the learning process becomes increasingly challenging, and the performance of the learning-based method cannot match that of the optimal solution. In such a scenario, we propose a deep reinforcement learning-based blind beamforming technique using a learnable Dolph-Tschebyscheff antenna array that can change its beam pattern to accommodate mobile users. Our simulation results show that the proposed method can support data rates very close to the best possible values.
First line of defense: A robust first layer mitigates adversarial attacks
Aug 21, 2024



Adversarial training (AT) incurs significant computational overhead, leading to growing interest in designing inherently robust architectures. We demonstrate that a carefully designed first layer of the neural network can serve as an implicit adversarial noise filter (ANF). This filter is created using a combination of large kernel size, increased convolution filters, and a maxpool operation. We show that integrating this filter as the first layer in architectures such as ResNet, VGG, and EfficientNet results in adversarially robust networks. Our approach achieves higher adversarial accuracies than existing natively robust architectures without AT and is competitive with adversarial-trained architectures across a wide range of datasets. Supporting our findings, we show that (a) the decision regions for our method have better margins, (b) the visualized loss surfaces are smoother, (c) the modified peak signal-to-noise ratio (mPSNR) values at the output of the ANF are higher, (d) high-frequency components are more attenuated, and (e) architectures incorporating ANF exhibit better denoising in Gaussian noise compared to baseline architectures. Code for all our experiments are available at \url{https://github.com/janani-suresh-97/first-line-defence.git}.
Energy Efficient Fair STAR-RIS for Mobile Users
Jul 09, 2024



In this work, we propose a method to improve the energy efficiency and fairness of simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RIS) for mobile users, ensuring reduced power consumption while maintaining reliable communication. To achieve this, we introduce a new parameter known as the subsurface assignment variable, which determines the number of STAR-RIS elements allocated to each user. We then formulate a novel optimization problem by concurrently optimizing the phase shifts of the STAR-RIS and subsurface assignment variable. We leverage the deep reinforcement learning (DRL) technique to address this optimization problem. The DRL model predicts the phase shifts of the STAR-RIS and efficiently allocates elements of STAR-RIS to the users. Additionally, we incorporate a penalty term in the DRL model to facilitate intelligent deactivation of STAR-RIS elements when not in use to enhance energy efficiency. Through extensive experiments, we show that the proposed method can achieve fairly high and nearly equal data rates for all users in both the transmission and reflection spaces in an energy-efficient manner.
A DRL Approach for RIS-Assisted Full-Duplex UL and DL Transmission: Beamforming, Phase Shift and Power Optimization
Dec 28, 2022



In this work, a two-stage deep reinforcement learning (DRL) approach is presented for a full-duplex (FD) transmission scenario that does not depend on the channel state information (CSI) knowledge to predict the phase-shifts of reconfigurable intelligent surface (RIS), beamformers at the base station (BS), and the transmit powers of BS and uplink users in order to maximize the weighted sum rate of uplink and downlink users. As the self-interference (SI) cancellation and beamformer design are coupled problems, the first stage uses a least squares method to partially cancel self-interference (SI) and initiate learning, while the second stage uses DRL to make predictions and achieve performance close to methods with perfect CSI knowledge. Further, to reduce the signaling from BS to the RISs, a DRL framework is proposed that predicts quantized RIS phase-shifts and beamformers using $32$ times fewer bits than the continuous version. The quantized methods have reduced action space and therefore faster convergence; with sufficient training, the UL and DL rates for the quantized phase method are $8.14\%$ and $2.45\%$ better than the continuous phase method respectively. The RIS elements can be grouped to have similar phase-shifts to further reduce signaling, at the cost of reduced performance.
Rotate the ReLU to implicitly sparsify deep networks
Jun 01, 2022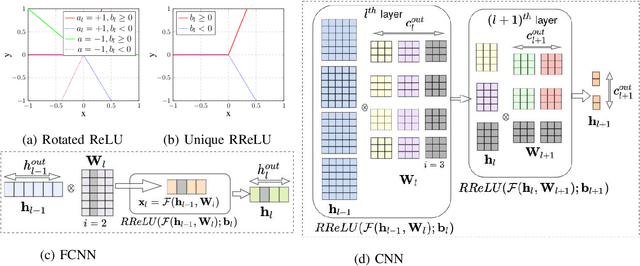
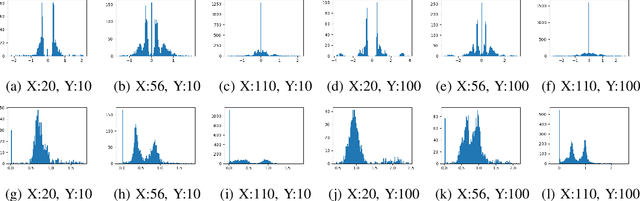

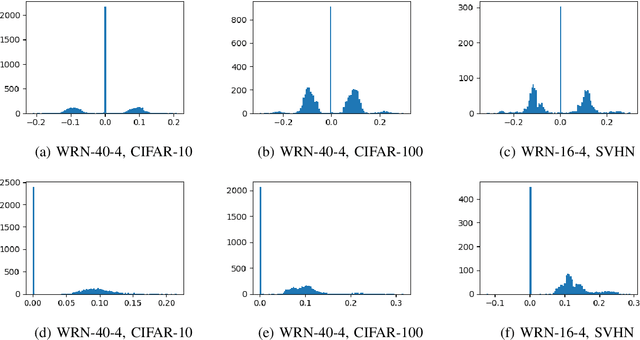
In the era of Deep Neural Network based solutions for a variety of real-life tasks, having a compact and energy-efficient deployable model has become fairly important. Most of the existing deep architectures use Rectifier Linear Unit (ReLU) activation. In this paper, we propose a novel idea of rotating the ReLU activation to give one more degree of freedom to the architecture. We show that this activation wherein the rotation is learned via training results in the elimination of those parameters/filters in the network which are not important for the task. In other words, rotated ReLU seems to be doing implicit sparsification. The slopes of the rotated ReLU activations act as coarse feature extractors and unnecessary features can be eliminated before retraining. Our studies indicate that features always choose to pass through a lesser number of filters in architectures such as ResNet and its variants. Hence, by rotating the ReLU, the weights or the filters that are not necessary are automatically identified and can be dropped thus giving rise to significant savings in memory and computation. Furthermore, in some cases, we also notice that along with saving in memory and computation we also obtain improvement over the reported performance of the corresponding baseline work in the popular datasets such as MNIST, CIFAR-10, CIFAR-100, and SVHN.
Binarized ResNet: Enabling Automatic Modulation Classification at the resource-constrained Edge
Oct 27, 2021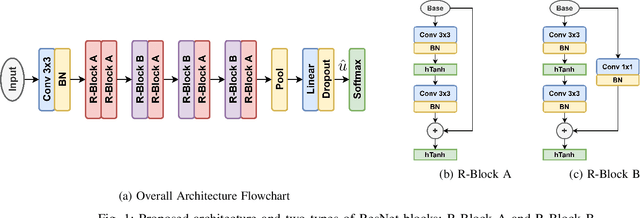
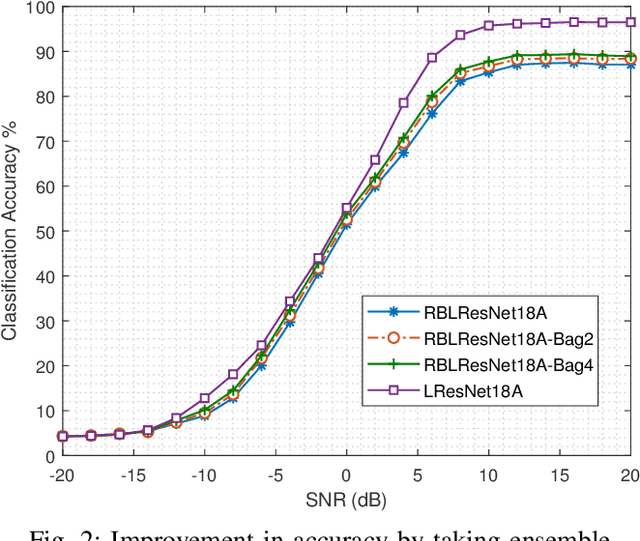
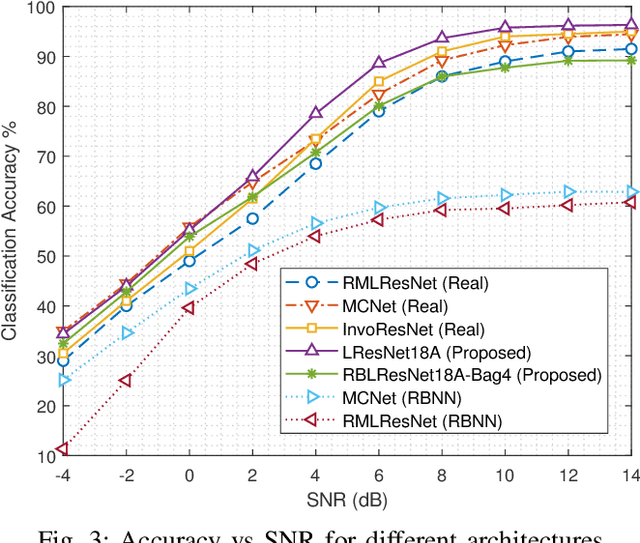
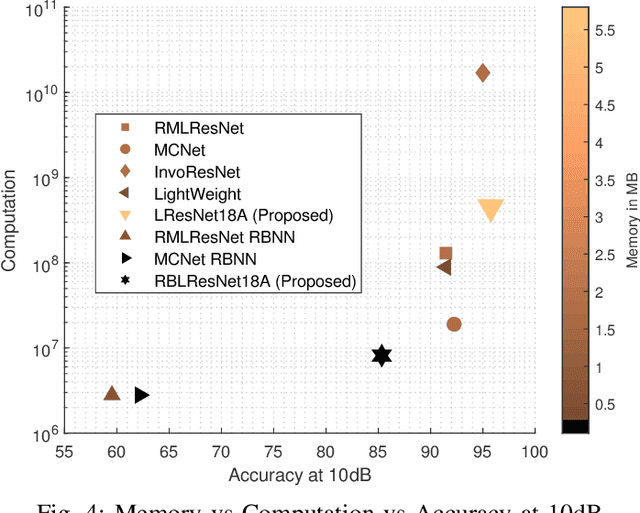
In this paper, we propose a ResNet based neural architecture to solve the problem of Automatic Modulation Classification. We showed that our architecture outperforms the state-of-the-art (SOTA) architectures. We further propose to binarize the network to deploy it in the Edge network where the devices are resource-constrained i.e. have limited memory and computing power. Instead of simple binarization, rotated binarization is applied to the network which helps to close the significant performance gap between the real and the binarized network. Because of the immense representation capability or the real network, its rotated binarized version achieves $85.33\%$ accuracy compared to $95.76\%$ accuracy of the proposed real network with $2.33$ and $16$ times lesser computing power than two of the SOTA architectures, MCNet and RMLResNet respectively, and approximately $16$ times less memory than both. The performance can be improved further to $87.74\%$ by taking an ensemble of four such rotated binarized networks.
BayesAoA: A Bayesian method for Computation Efficient Angle of Arrival Estimation
Oct 15, 2021
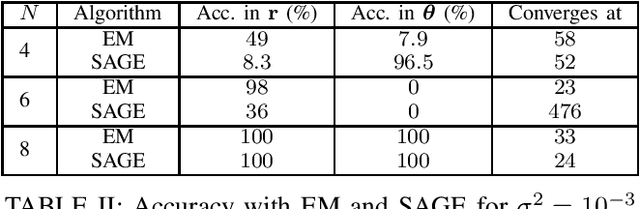


The angle of Arrival (AoA) estimation is of great interest in modern communication systems. Traditional maximum likelihood-based iterative algorithms are sensitive to initialization and cannot be used online. We propose a Bayesian method to find AoA that is insensitive towards initialization. The proposed method is less complex and needs fewer computing resources than traditional deep learning-based methods. It has a faster convergence than the brute-force methods. Further, a Hedge type solution is proposed that helps to deploy the method online to handle the situations where the channel noise and antenna configuration in the receiver change over time. The proposed method achieves $92\%$ accuracy in a channel of noise variance $10^{-6}$ with $19.3\%$ of the brute-force method's computation.
Realizing Neural Decoder at the Edge with Ensembled BNN
Jun 18, 2021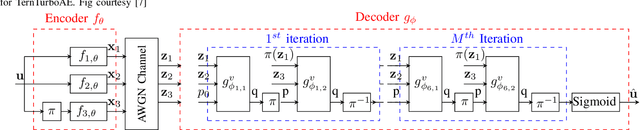
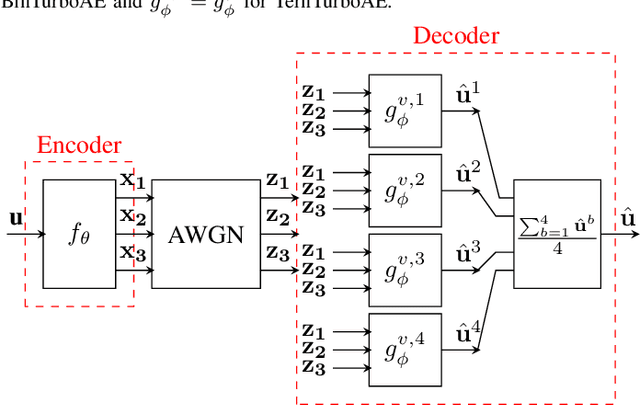
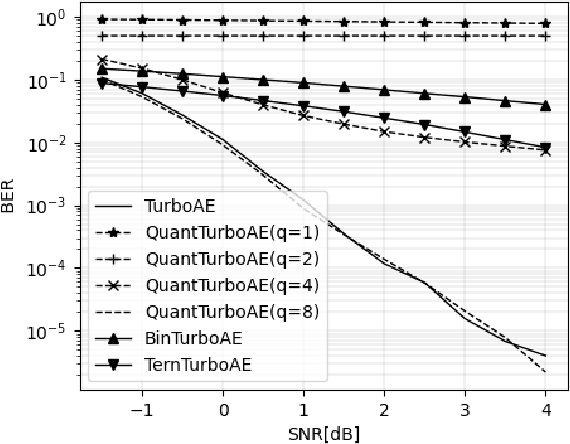
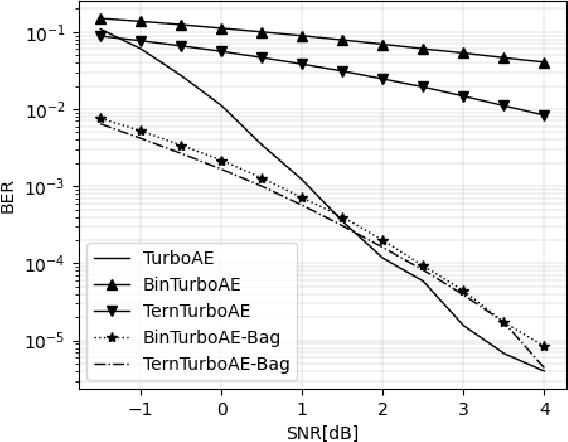
In this work, we propose extreme compression techniques like binarization, ternarization for Neural Decoders such as TurboAE. These methods reduce memory and computation by a factor of 64 with a performance better than the quantized (with 1-bit or 2-bits) Neural Decoders. However, because of the limited representation capability of the Binary and Ternary networks, the performance is not as good as the real-valued decoder. To fill this gap, we further propose to ensemble 4 such weak performers to deploy in the edge to achieve a performance similar to the real-valued network. These ensemble decoders give 16 and 64 times saving in memory and computation respectively and help to achieve performance similar to real-valued TurboAE.
Understanding Learning Dynamics of Binary Neural Networks via Information Bottleneck
Jun 13, 2020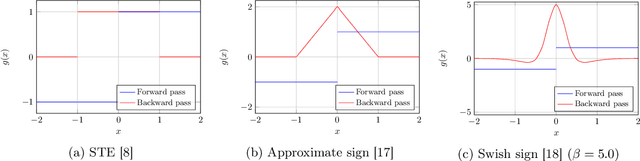
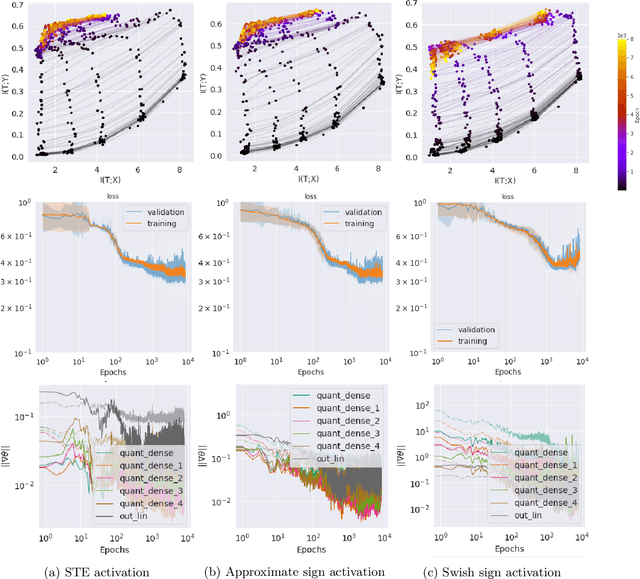
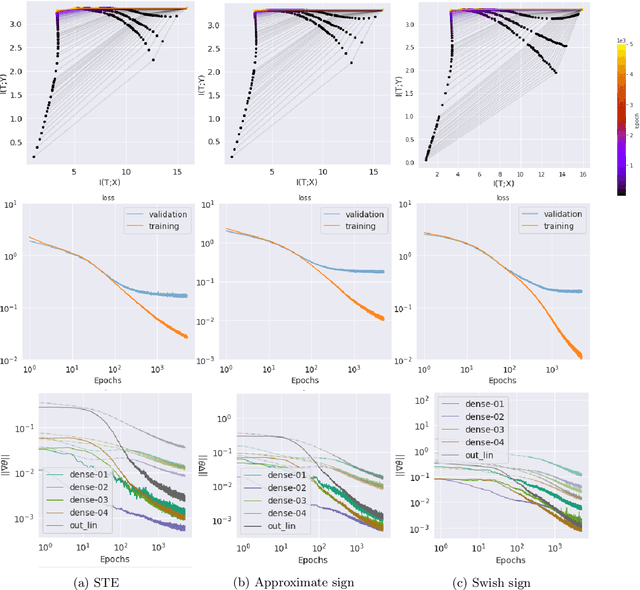

Compact neural networks are essential for affordable and power efficient deep learning solutions. Binary Neural Networks (BNNs) take compactification to the extreme by constraining both weights and activations to two levels, $\{+1, -1\}$. However, training BNNs are not easy due to the discontinuity in activation functions, and the training dynamics of BNNs is not well understood. In this paper, we present an information-theoretic perspective of BNN training. We analyze BNNs through the Information Bottleneck principle and observe that the training dynamics of BNNs is considerably different from that of Deep Neural Networks (DNNs). While DNNs have a separate empirical risk minimization and representation compression phases, our numerical experiments show that in BNNs, both these phases are simultaneous. Since BNNs have a less expressive capacity, they tend to find efficient hidden representations concurrently with label fitting. Experiments in multiple datasets support these observations, and we see a consistent behavior across different activation functions in BNNs.
What is the optimal depth for deep-unfolding architectures at deployment?
Mar 20, 2020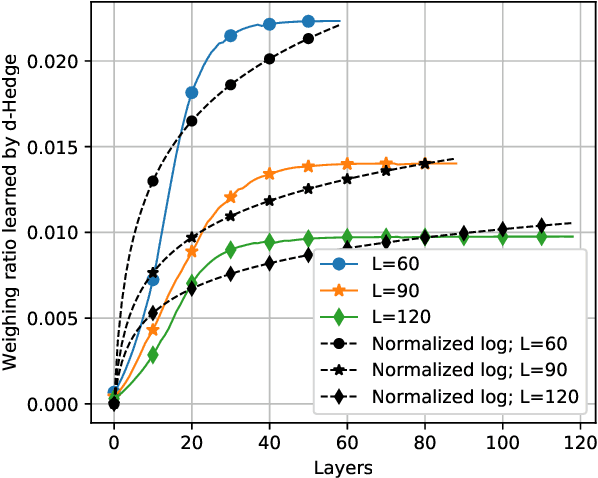
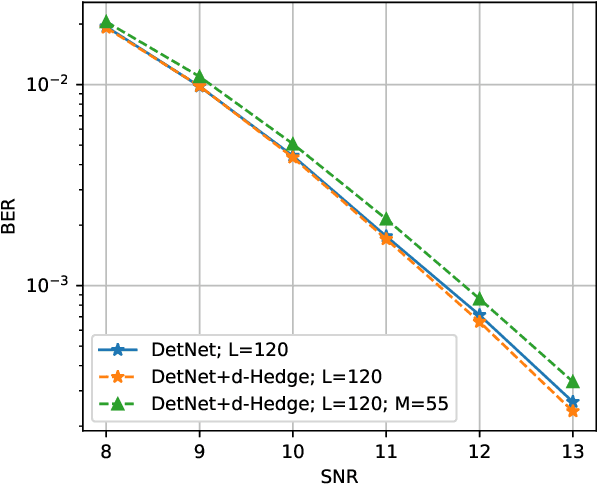
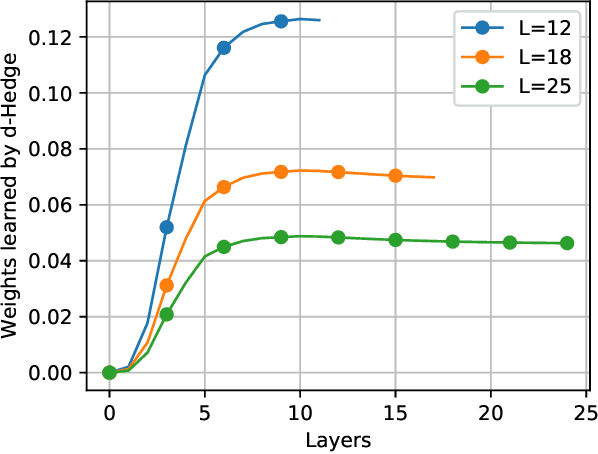
Recently, many iterative algorithms proposed for various applications such as compressed sensing, MIMO Detection, etc. have been unfolded and presented as deep networks; these networks are shown to produce better results than the algorithms in their iterative forms. However, deep networks are highly sensitive to the hyperparameters chosen. Especially for a deep unfolded network, using more layers may lead to redundancy and hence, excessive computation during deployment. In this work, we consider the problem of determining the optimal number of layers required for such unfolded architectures. We propose a method that treats the networks as experts and measures the relative importance of the expertise provided by layers using a variant of the popular Hedge algorithm. Based on the importance of the different layers, we determine the optimal layers required for deployment. We study the effectiveness of this method by applying it to two recent and popular deep-unfolding architectures, namely DetNet and TISTANet.