 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPAR: Dynamic Patchification for Efficient Autoregressive Visual Generation
Dec 26, 2025Decoder-only autoregressive image generation typically relies on fixed-length tokenization schemes whose token counts grow quadratically with resolution, substantially increasing the computational and memory demands of attention. We present DPAR, a novel decoder-only autoregressive model that dynamically aggregates image tokens into a variable number of patches for efficient image generation. Our work is the first to demonstrate that next-token prediction entropy from a lightweight and unsupervised autoregressive model provides a reliable criterion for merging tokens into larger patches based on information content. DPAR makes minimal modifications to the standard decoder architecture, ensuring compatibility with multimodal generation frameworks and allocating more compute to generation of high-information image regions. Further, we demonstrate that training with dynamically sized patches yields representations that are robust to patch boundaries, allowing DPAR to scale to larger patch sizes at inference. DPAR reduces token count by 1.81x and 2.06x on Imagenet 256 and 384 generation resolution respectively, leading to a reduction of up to 40% FLOPs in training costs. Further, our method exhibits faster convergence and improves FID by up to 27.1% relative to baseline models.
CompanionCast: A Multi-Agent Conversational AI Framework with Spatial Audio for Social Co-Viewing Experiences
Dec 11, 2025Social presence is central to the enjoyment of watching content together, yet modern media consumption is increasingly solitary. We investigate whether multi-agent conversational AI systems can recreate the dynamics of shared viewing experiences across diverse content types. We present CompanionCast, a general framework for orchestrating multiple role-specialized AI agents that respond to video content using multimodal inputs, speech synthesis, and spatial audio. Distinctly, CompanionCast integrates an LLM-as-a-Judge module that iteratively scores and refines conversations across five dimensions (relevance, authenticity, engagement, diversity, personality consistency). We validate this framework through sports viewing, a domain with rich dynamics and strong social traditions, where a pilot study with soccer fans suggests that multi-agent interaction improves perceived social presence compared to solo viewing. We contribute: (1) a generalizable framework for orchestrating multi-agent conversations around multimodal video content, (2) a novel evaluator-agent pipeline for conversation quality control, and (3) exploratory evidence of increased social presence in AI-mediated co-viewing. We discuss challenges and future directions for applying this approach to diverse viewing contexts including entertainment, education, and collaborative watching experiences.
Towards modeling evolving longitudinal health trajectories with a transformer-based deep learning model
Dec 12, 2024Health registers contain rich information about individuals' health histories. Here our interest lies in understanding how individuals' health trajectories evolve in a nationwide longitudinal dataset with coded features, such as clinical codes, procedures, and drug purchases. We introduce a straightforward approach for training a Transformer-based deep learning model in a way that lets us analyze how individuals' trajectories change over time. This is achieved by modifying the training objective and by applying a causal attention mask. We focus here on a general task of predicting the onset of a range of common diseases in a given future forecast interval. However, instead of providing a single prediction about diagnoses that could occur in this forecast interval, our approach enable the model to provide continuous predictions at every time point up until, and conditioned on, the time of the forecast period. We find that this model performs comparably to other models, including a bi-directional transformer model, in terms of basic prediction performance while at the same time offering promising trajectory modeling properties. We explore a couple of ways to use this model for analyzing health trajectories and aiding in early detection of events that forecast possible later disease onsets. We hypothesize that this method may be helpful in continuous monitoring of peoples' health trajectories and enabling interventions in ongoing health trajectories, as well as being useful in retrospective analyses.
Look beyond labels: Incorporating functional summary information in Bayesian neural networks
Jul 04, 2022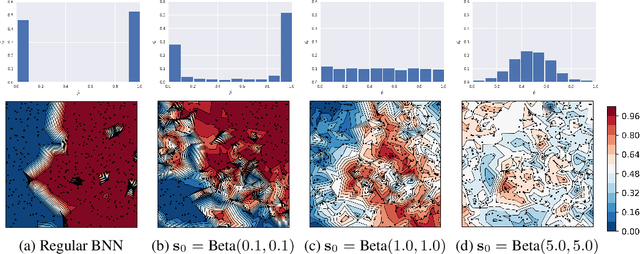
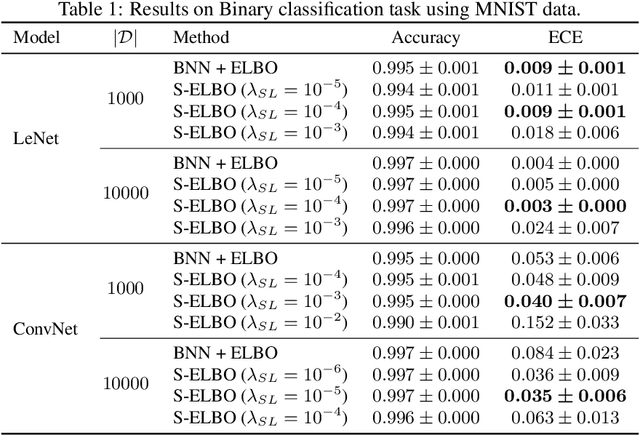
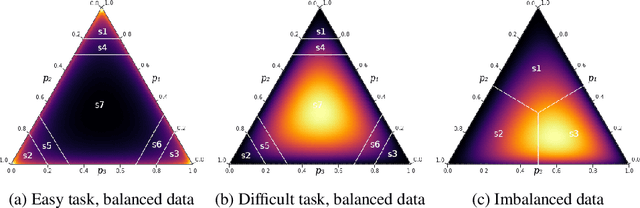
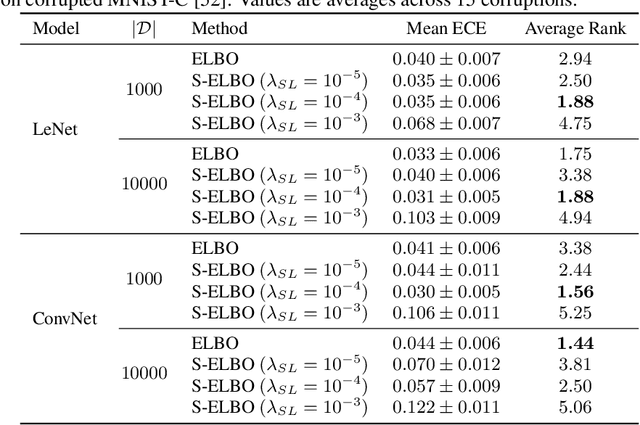
Bayesian deep learning offers a principled approach to train neural networks that accounts for both aleatoric and epistemic uncertainty. In variational inference, priors are often specified over the weight parameters, but they do not capture the true prior knowledge in large and complex neural network architectures. We present a simple approach to incorporate summary information about the predicted probability (such as sigmoid or softmax score) outputs in Bayesian neural networks (BNNs). The available summary information is incorporated as augmented data and modeled with a Dirichlet process, and we derive the corresponding \emph{Summary Evidence Lower BOund}. We show how the method can inform the model about task difficulty or class imbalance. Extensive empirical experiments show that, with negligible computational overhead, the proposed method yields a BNN with a better calibration of uncertainty.
Understanding Learning Dynamics of Binary Neural Networks via Information Bottleneck
Jun 13, 2020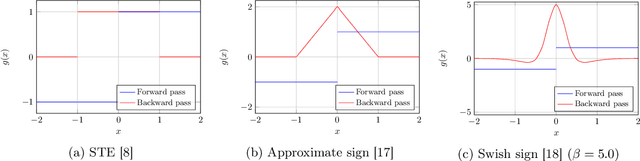
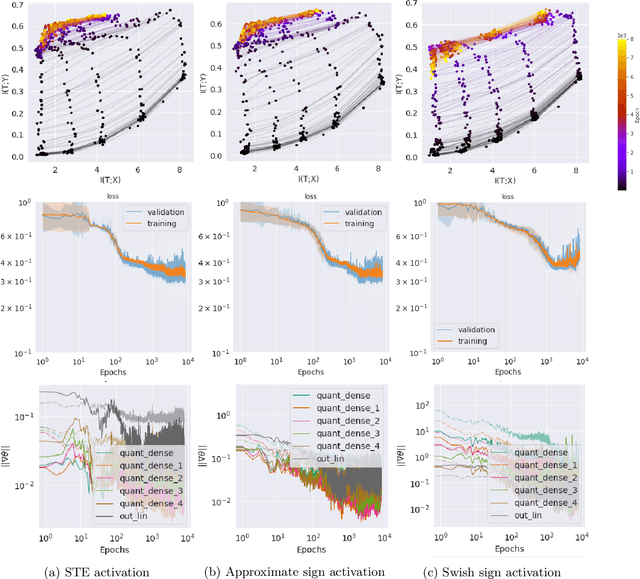
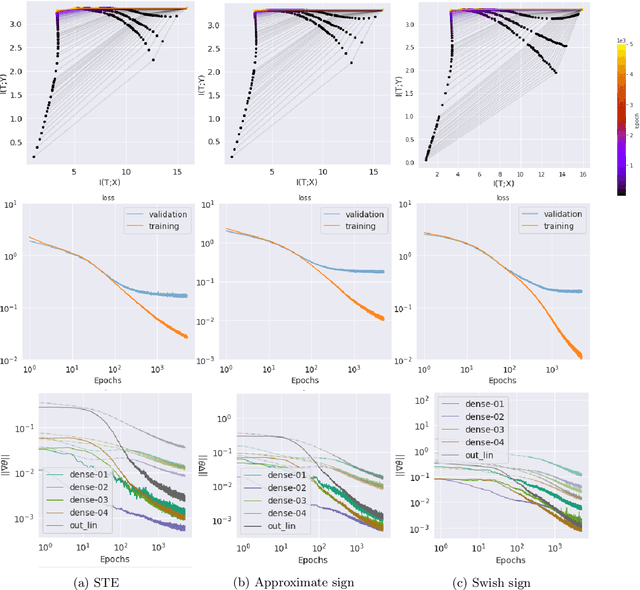

Compact neural networks are essential for affordable and power efficient deep learning solutions. Binary Neural Networks (BNNs) take compactification to the extreme by constraining both weights and activations to two levels, $\{+1, -1\}$. However, training BNNs are not easy due to the discontinuity in activation functions, and the training dynamics of BNNs is not well understood. In this paper, we present an information-theoretic perspective of BNN training. We analyze BNNs through the Information Bottleneck principle and observe that the training dynamics of BNNs is considerably different from that of Deep Neural Networks (DNNs). While DNNs have a separate empirical risk minimization and representation compression phases, our numerical experiments show that in BNNs, both these phases are simultaneous. Since BNNs have a less expressive capacity, they tend to find efficient hidden representations concurrently with label fitting. Experiments in multiple datasets support these observations, and we see a consistent behavior across different activation functions in BNNs.
Deep Reinforcement Learning based Blind mmWave MIMO Beam Alignment
Jan 25, 2020



Directional beamforming is a crucial component for realizing robust wireless communication systems using millimeter wave (mmWave) technology. Beam alignment using brute-force search of the space introduces time overhead while location aided blind beam alignment adds additional hardware requirements to the system. In this paper, we introduce a method for blind alignment based on the RF fingerprints of user equipment obtained by the base stations. The proposed system performs blind beamforming on a multiple base station cellular environment with multiple mobile users using deep reinforcement learning. We present a novel neural network architecture that can handle a mix of both continuous and discrete actions and use policy gradient methods to train the model. Our results show that the proposed model is able to give a considerable improvement in data rates over traditional methods.
Beyond 5G: Leveraging Cell Free TDD Massive MIMO using Cascaded Deep learning
Oct 13, 2019



Cell Free Massive MIMO is a solution for improving the spectral efficiency of next generation communication systems and a crucial aspect for realizing the gains of the technology is the availability of accurate Channel State Information (CSI). Time Division Duplexing (TDD) mode is popular for Cell Free Massive MIMO since the physical wireless channel's assumed reciprocity facilitates channel estimation. However, the availability of accurate CSI in the TDD mode is hindered by the non reciprocity of the end to end channel, due to the presence of RF components, as well as the non availability of CSI in the subcarriers that do not have reference signals. Hence, the prediction of the Downlink CSI in the subcarriers without reference signals becomes an even more complicated problem. In this work, we consider TDD non-reciprocity with limited availability of resource elements for CSI estimation and propose a deep learning based approach using cascaded Deep Neural Networks (DNNs) to attain a one shot prediction of the reverse channel across the entire bandwidth. The proposed method is able to estimate downlink CSI at all subcarriers from the uplink CSI at selected subcarriers and hence does not require downlink CSI feedback.
Design of Communication Systems using Deep Learning: A Variational Inference Perspective
Apr 18, 2019



An approach to design end to end communication system using deep learning leveraging the generative modeling capabilities of autoencoders is presented. The system models are designed using Deep Neural Networks (DNNs) and the objective function for optimizing these models are derived using variational inference. Through experimental validation, the proposed method is shown to produce better models consistently in terms of error rate performance as well as constellation packing density as compared to previous works.
A Non-parametric Multi-stage Learning Framework for Cognitive Spectrum Access in IoT Networks
Apr 30, 2018



Given the increasing number of devices that is going to get connected to wireless networks with the advent of Internet of Things, spectrum scarcity will present a major challenge. Application of opportunistic spectrum access mechanisms to IoT networks will become increasingly important to solve this. In this paper, we present a cognitive radio network architecture which uses multi-stage online learning techniques for spectrum assignment to devices, with the aim of improving the throughput and energy efficiency of the IoT devices. In the first stage, we use an AI technique to learn the quality of a user-channel pairing. The next stage utilizes a non-parametric Bayesian learning algorithm to estimate the Primary User OFF time in each channel. The third stage augments the Bayesian learner with implicit exploration to accelerate the learning procedure. The proposed method leads to significant improvement in throughput and energy efficiency of the IoT devices while keeping the interference to the primary users minimal. We provide comprehensive empirical validation of the method with other learning based approaches.
An aggregating strategy for shifting experts in discrete sequence prediction
Aug 05, 2017



We study how we can adapt a predictor to a non-stationary environment with advises from multiple experts. We study the problem under complete feedback when the best expert changes over time from a decision theoretic point of view. Proposed algorithm is based on popular exponential weighing method with exponential discounting. We provide theoretical results bounding regret under the exponential discounting setting. Upper bound on regret is derived for finite time horizon problem. Numerical verification of different real life datasets are provided to show the utility of proposed algorithm.