 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Learning Dynamics of Binary Neural Networks via Information Bottleneck
Paper and Code
Jun 13, 2020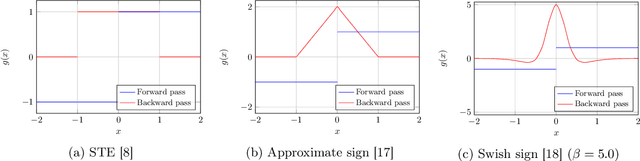
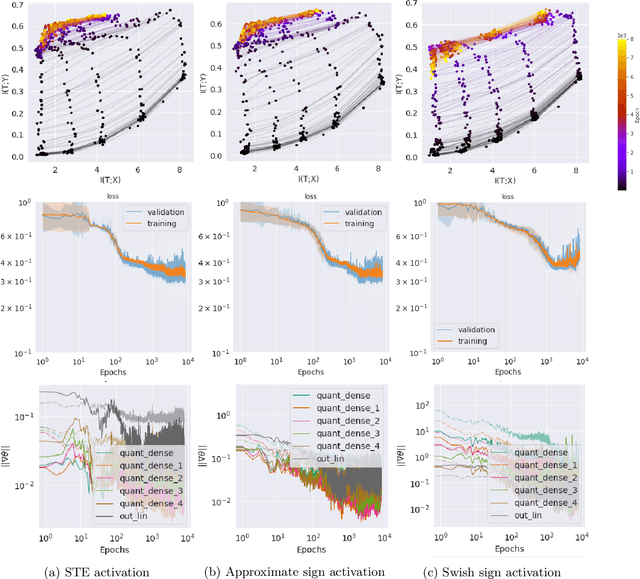
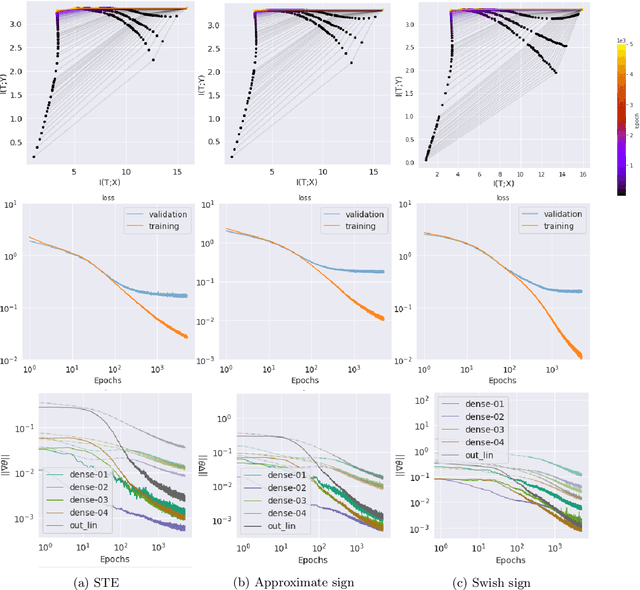

Compact neural networks are essential for affordable and power efficient deep learning solutions. Binary Neural Networks (BNNs) take compactification to the extreme by constraining both weights and activations to two levels, $\{+1, -1\}$. However, training BNNs are not easy due to the discontinuity in activation functions, and the training dynamics of BNNs is not well understood. In this paper, we present an information-theoretic perspective of BNN training. We analyze BNNs through the Information Bottleneck principle and observe that the training dynamics of BNNs is considerably different from that of Deep Neural Networks (DNNs). While DNNs have a separate empirical risk minimization and representation compression phases, our numerical experiments show that in BNNs, both these phases are simultaneous. Since BNNs have a less expressive capacity, they tend to find efficient hidden representations concurrently with label fitting. Experiments in multiple datasets support these observations, and we see a consistent behavior across different activation functions in BNNs.