 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Binary Neural Networks: Enabling Low-Cost Inference
Mar 16, 2026Federated Learning (FL) preserves privacy by distributing training across devices. However, using DNNs is computationally intensive at the low-powered edge during inference. Edge deployment demands models that simultaneously optimize memory footprint and computational efficiency, a dilemma where conventional DNNs fail by exceeding resource limits. Traditional post-training binarization reduces model size but suffers from severe accuracy loss due to quantization errors. To address these challenges, we propose FedBNN, a rotation-aware binary neural network framework that learns binary representations directly during local training. By encoding each weight as a single bit $\{+1, -1\}$ instead of a $32$-bit float, FedBNN shrinks the model footprint, significantly reducing runtime (during inference) FLOPs and memory requirements in comparison to federated methods using real models. Evaluations across multiple benchmark datasets demonstrate that FedBNN significantly reduces resource consumption while performing similarly to existing federated methods using real-valued models.
Structured Sparsity and Weight-adaptive Pruning for Memory and Compute efficient Whisper models
Oct 14, 2025

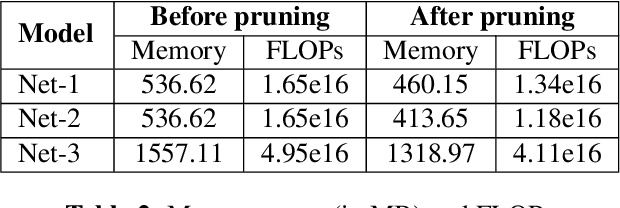

Whisper models have achieved remarkable progress in speech recognition; yet their large size remains a bottleneck for deployment on resource-constrained edge devices. This paper proposes a framework to design fine-tuned variants of Whisper which address the above problem. Structured sparsity is enforced via the Sparse Group LASSO penalty as a loss regularizer, to reduce the number of FLOating Point operations (FLOPs). Further, a weight statistics aware pruning algorithm is proposed. We also design our custom text normalizer for WER evaluation. On Common Voice 11.0 Hindi dataset, we obtain, without degrading WER, (a) 35.4% reduction in model parameters, 14.25% lower memory consumption and 18.5% fewer FLOPs on Whisper-small, and (b) 31% reduction in model parameters, 15.29% lower memory consumption and 16.95% fewer FLOPs on Whisper-medium; and, (c) substantially outperform the state-of-the-art Iterative Magnitude Pruning based method by pruning 18.7% more parameters along with a 12.31 reduction in WER.
Online waveform selection for cognitive radar
Oct 14, 2024



Designing a cognitive radar system capable of adapting its parameters is challenging, particularly when tasked with tracking a ballistic missile throughout its entire flight. In this work, we focus on proposing adaptive algorithms that select waveform parameters in an online fashion. Our novelty lies in formulating the learning problem using domain knowledge derived from the characteristics of ballistic trajectories. We propose three reinforcement learning algorithms: bandwidth scaling, Q-learning, and Q-learning lookahead. These algorithms dynamically choose the bandwidth for each transmission based on received feedback. Through experiments on synthetically generated ballistic trajectories, we demonstrate that our proposed algorithms achieve the dual objectives of minimizing range error and maintaining continuous tracking without losing the target.
Golden Ratio Search: A Low-Power Adversarial Attack for Deep Learning based Modulation Classification
Sep 17, 2024



We propose a minimal power white box adversarial attack for Deep Learning based Automatic Modulation Classification (AMC). The proposed attack uses the Golden Ratio Search (GRS) method to find powerful attacks with minimal power. We evaluate the efficacy of the proposed method by comparing it with existing adversarial attack approaches. Additionally, we test the robustness of the proposed attack against various state-of-the-art architectures, including defense mechanisms such as adversarial training, binarization, and ensemble methods. Experimental results demonstrate that the proposed attack is powerful, requires minimal power, and can be generated in less time, significantly challenging the resilience of current AMC methods.
Geometry Aware Meta-Learning Neural Network for Joint Phase and Precoder Optimization in RIS
Sep 17, 2024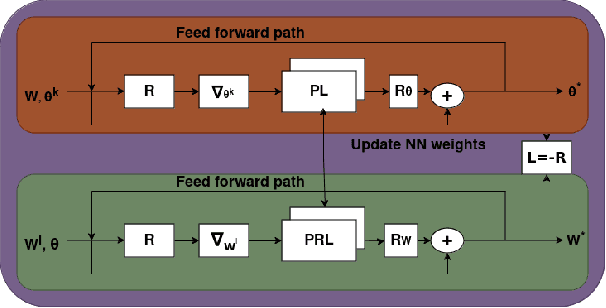
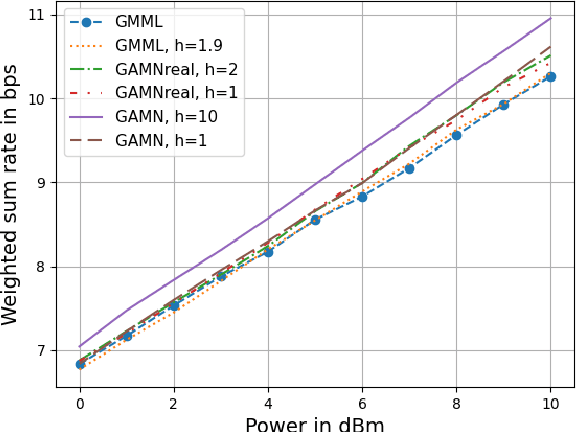
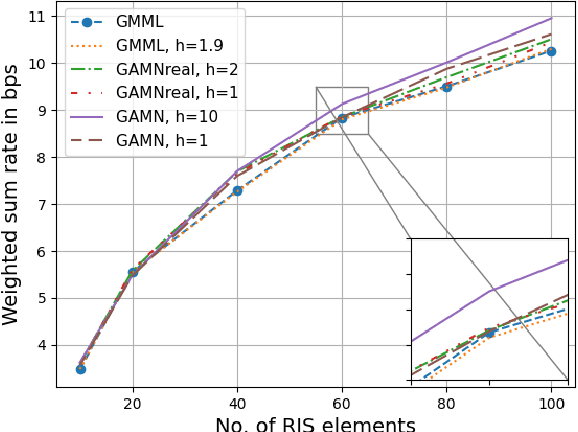
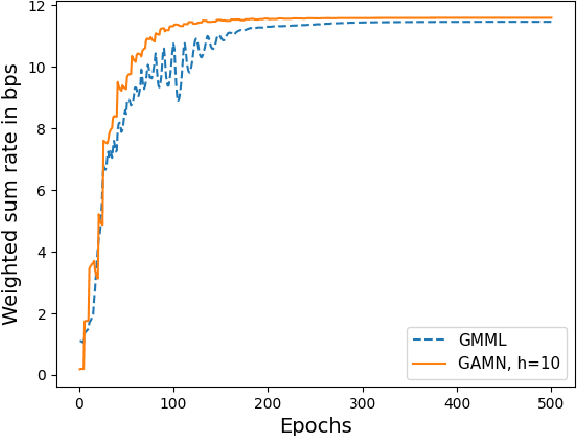
In reconfigurable intelligent surface (RIS) aided systems, the joint optimization of the precoder matrix at the base station and the phase shifts of the RIS elements involves significant complexity. In this paper, we propose a complex-valued, geometry aware meta-learning neural network that maximizes the weighted sum rate in a multi-user multiple input single output system. By leveraging the complex circle geometry for phase shifts and spherical geometry for the precoder, the optimization occurs on Riemannian manifolds, leading to faster convergence. We use a complex-valued neural network for phase shifts and an Euler inspired update for the precoder network. Our approach outperforms existing neural network-based algorithms, offering higher weighted sum rates, lower power consumption, and significantly faster convergence. Specifically, it converges faster by nearly 100 epochs, with a 0.7 bps improvement in weighted sum rate and a 1.8 dBm power gain when compared with existing work.
Learning Rate Optimization for Deep Neural Networks Using Lipschitz Bandits
Sep 15, 2024



Learning rate is a crucial parameter in training of neural networks. A properly tuned learning rate leads to faster training and higher test accuracy. In this paper, we propose a Lipschitz bandit-driven approach for tuning the learning rate of neural networks. The proposed approach is compared with the popular HyperOpt technique used extensively for hyperparameter optimization and the recently developed bandit-based algorithm BLiE. The results for multiple neural network architectures indicate that our method finds a better learning rate using a) fewer evaluations and b) lesser number of epochs per evaluation, when compared to both HyperOpt and BLiE. Thus, the proposed approach enables more efficient training of neural networks, leading to lower training time and lesser computational cost.
Tuning-Free Online Robust Principal Component Analysis through Implicit Regularization
Sep 11, 2024

The performance of the standard Online Robust Principal Component Analysis (OR-PCA) technique depends on the optimum tuning of the explicit regularizers and this tuning is dataset sensitive. We aim to remove the dependency on these tuning parameters by using implicit regularization. We propose to use the implicit regularization effect of various modified gradient descents to make OR-PCA tuning free. Our method incorporates three different versions of modified gradient descent that separately but naturally encourage sparsity and low-rank structures in the data. The proposed method performs comparable or better than the tuned OR-PCA for both simulated and real-world datasets. Tuning-free ORPCA makes it more scalable for large datasets since we do not require dataset-dependent parameter tuning.
Source Enumeration using the Distribution of Angles: A Robust and Parameter-Free Approach
Sep 10, 2024Source enumeration, the task of estimating the number of sources from the signal received by the array of antennas, is a critical problem in array signal processing. Numerous methods have been proposed to estimate the number of sources under white or colored Gaussian noise. However, their performance degrades significantly in the presence of a limited number of observations and/or a large number of sources. In this work, we propose a method based on the distribution of angles that performs well in (a) independent Gaussian, (b) spatially colored Gaussian, and (c) heavy-tailed noise, even when the number of sources is large. We support the supremacy of our algorithm over state-of-the-art methods with extensive simulation results.
First line of defense: A robust first layer mitigates adversarial attacks
Aug 21, 2024



Adversarial training (AT) incurs significant computational overhead, leading to growing interest in designing inherently robust architectures. We demonstrate that a carefully designed first layer of the neural network can serve as an implicit adversarial noise filter (ANF). This filter is created using a combination of large kernel size, increased convolution filters, and a maxpool operation. We show that integrating this filter as the first layer in architectures such as ResNet, VGG, and EfficientNet results in adversarially robust networks. Our approach achieves higher adversarial accuracies than existing natively robust architectures without AT and is competitive with adversarial-trained architectures across a wide range of datasets. Supporting our findings, we show that (a) the decision regions for our method have better margins, (b) the visualized loss surfaces are smoother, (c) the modified peak signal-to-noise ratio (mPSNR) values at the output of the ANF are higher, (d) high-frequency components are more attenuated, and (e) architectures incorporating ANF exhibit better denoising in Gaussian noise compared to baseline architectures. Code for all our experiments are available at \url{https://github.com/janani-suresh-97/first-line-defence.git}.
Probabilistic learning rate scheduler with provable convergence
Jul 10, 2024



Learning rate schedulers have shown great success in speeding up the convergence of learning algorithms in practice. However, their convergence to a minimum has not been proven theoretically. This difficulty mainly arises from the fact that, while traditional convergence analysis prescribes to monotonically decreasing (or constant) learning rates, schedulers opt for rates that often increase and decrease through the training epochs. In this work, we aim to bridge the gap by proposing a probabilistic learning rate scheduler (PLRS), that does not conform to the monotonically decreasing condition, with provable convergence guarantees. In addition to providing detailed convergence proofs, we also show experimental results where the proposed PLRS performs competitively as other state-of-the-art learning rate schedulers across a variety of datasets and architectures.