Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Non-stationary Bandits: A Bayesian Approach
Paper and Code
Jul 31, 2017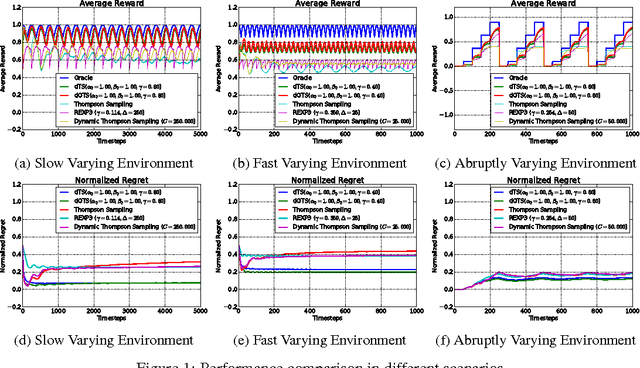



We consider the multi armed bandit problem in non-stationary environments. Based on the Bayesian method, we propose a variant of Thompson Sampling which can be used in both rested and restless bandit scenarios. Applying discounting to the parameters of prior distribution, we describe a way to systematically reduce the effect of past observations. Further, we derive the exact expression for the probability of picking sub-optimal arms. By increasing the exploitative value of Bayes' samples, we also provide an optimistic version of the algorithm. Extensive empirical analysis is conducted under various scenarios to validate the utility of proposed algorithms. A comparison study with various state-of-the-arm algorithms is also included.
* Submitted to NIPS 2017
View paper on