 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Knowledge, Not Just Facts via Multi-Step Reasoning over Background Stories
Feb 02, 2026Enabling artificial intelligence systems, particularly large language models, to integrate new knowledge and flexibly apply it during reasoning remains a central challenge. Existing knowledge editing approaches emphasize atomic facts, improving factual recall but often failing to integrate new information into a coherent framework usable across contexts. In this work, we argue that knowledge internalization is fundamentally a reasoning problem rather than a memorization problem. Consequently, a model should be trained in situations where the new information is instrumental to solving a task, combined with pre-existing knowledge, and exercised through multi-step reasoning. Based on this insight, we propose a training strategy based on three principles. First, new knowledge is introduced as a coherent background story that contextualizes novel facts and explains their relation to existing knowledge. Second, models are trained using self-generated multi-hop questions that require multi-step reasoning involving the new information. Third, training is done using knowledge distillation, forcing a student model to internalize the teacher's reasoning behavior without access to the novel information. Experiments show that models trained with this strategy effectively leverage newly acquired knowledge during reasoning and achieve remarkable performance on challenging questions that require combining multiple new facts.
MiniLingua: A Small Open-Source LLM for European Languages
Dec 15, 2025Large language models are powerful but often limited by high computational cost, privacy concerns, and English-centric training. Recent progress demonstrates that small, efficient models with around one billion parameters can deliver strong results and enable on-device use. This paper introduces MiniLingua, a multilingual open-source LLM of one billion parameters trained from scratch for 13 European languages, designed to balance coverage and instruction-following capabilities. Based on evaluation results, the instruction-tuned version of MiniLingua outperforms EuroLLM, a model with a similar training approach but a larger training budget, on summarization, classification and both open- and closed-book question answering. Moreover, it remains competitive with more advanced state-of-the-art models on open-ended generation tasks. We release model weights, tokenizer and source code used for data processing and model training.
Adaptive Residual-Update Steering for Low-Overhead Hallucination Mitigation in Large Vision Language Models
Nov 13, 2025Large Vision-Language Models (LVLMs) often suffer from object hallucination, generating text inconsistent with visual inputs, which can critically undermine their reliability. Existing inference-time interventions to mitigate this issue present a challenging trade-off: while methods that steer internal states or adjust output logits can be effective, they often incur substantial computational overhead, typically requiring extra forward passes. This efficiency bottleneck can limit their practicality for real-world, latency-sensitive deployments. In this work, we aim to address this trade-off with Residual-Update Directed DEcoding Regulation (RUDDER), a low-overhead framework that steers LVLMs towards visually-grounded generation. RUDDER is built on two key innovations: (1) Contextual Activation Residual Direction (CARD) vector, a per-sample visual evidence vector extracted from the residual update of a self-attention layer during a single, standard forward pass. (2) A Bayesian-inspired adaptive gate that performs token-wise injection, applying a corrective signal whose strength is conditioned on the model's deviation from the visual context. Extensive experiments on key hallucination benchmarks, including POPE and CHAIR, indicate that RUDDER achieves performance comparable to state-of-the-art methods while introducing negligible computational latency, validating RUDDER as a pragmatic and effective approach for improving LVLMs' reliability without a significant compromise on efficiency.
POEMS: Product of Experts for Interpretable Multi-omic Integration using Sparse Decoding
Nov 05, 2025Integrating different molecular layers, i.e., multiomics data, is crucial for unraveling the complexity of diseases; yet, most deep generative models either prioritize predictive performance at the expense of interpretability or enforce interpretability by linearizing the decoder, thereby weakening the network's nonlinear expressiveness. To overcome this tradeoff, we introduce POEMS: Product Of Experts for Interpretable Multiomics Integration using Sparse Decoding, an unsupervised probabilistic framework that preserves predictive performance while providing interpretability. POEMS provides interpretability without linearizing any part of the network by 1) mapping features to latent factors using sparse connections, which directly translates to biomarker discovery, 2) allowing for cross-omic associations through a shared latent space using product of experts model, and 3) reporting contributions of each omic by a gating network that adaptively computes their influence in the representation learning. Additionally, we present an efficient sparse decoder. In a cancer subtyping case study, POEMS achieves competitive clustering and classification performance while offering our novel set of interpretations, demonstrating that biomarker based insight and predictive accuracy can coexist in multiomics representation learning.
Strategies for Robust Deep Learning Based Deformable Registration
Oct 27, 2025Deep learning based deformable registration methods have become popular in recent years. However, their ability to generalize beyond training data distribution can be poor, significantly hindering their usability. LUMIR brain registration challenge for Learn2Reg 2025 aims to advance the field by evaluating the performance of the registration on contrasts and modalities different from those included in the training set. Here we describe our submission to the challenge, which proposes a very simple idea for significantly improving robustness by transforming the images into MIND feature space before feeding them into the model. In addition, a special ensembling strategy is proposed that shows a small but consistent improvement.
Object-level Self-Distillation for Vision Pretraining
Jun 04, 2025State-of-the-art vision pretraining methods rely on image-level self-distillation from object-centric datasets such as ImageNet, implicitly assuming each image contains a single object. This assumption does not always hold: many ImageNet images already contain multiple objects. Further, it limits scalability to scene-centric datasets that better mirror real-world complexity. We address these challenges by introducing Object-level Self-DIStillation (ODIS), a pretraining approach that shifts the self-distillation granularity from whole images to individual objects. Using object-aware cropping and masked attention, ODIS isolates object-specific regions, guiding the transformer toward semantically meaningful content and transforming a noisy, scene-level task into simpler object-level sub-tasks. We show that this approach improves visual representations both at the image and patch levels. Using masks at inference time, our method achieves an impressive $82.6\%$ $k$-NN accuracy on ImageNet1k with ViT-Large.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025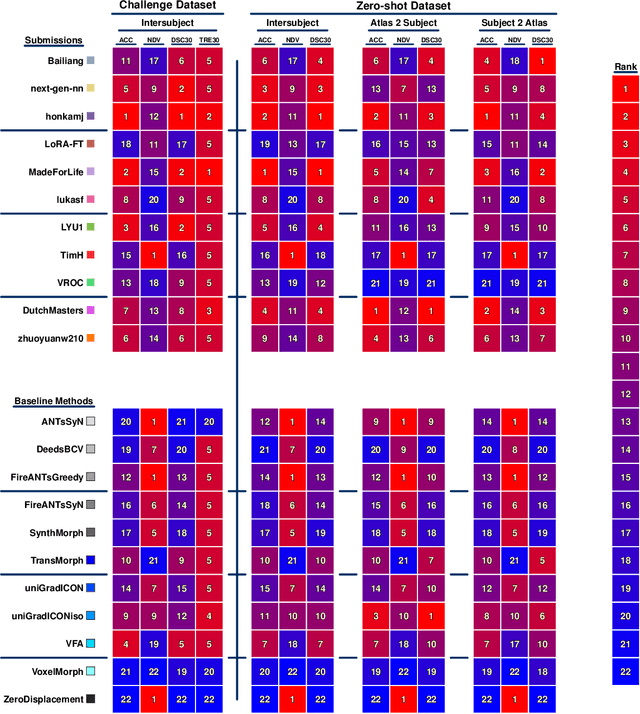
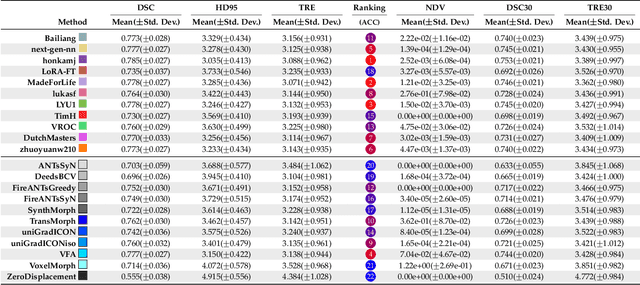

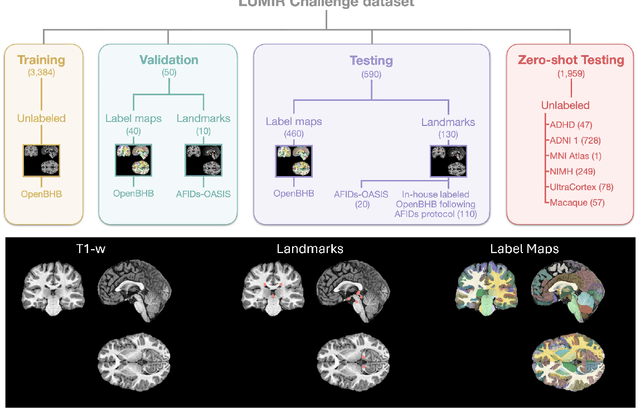
Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
ViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
May 19, 2025Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.
Recursive Decomposition with Dependencies for Generic Divide-and-Conquer Reasoning
May 05, 2025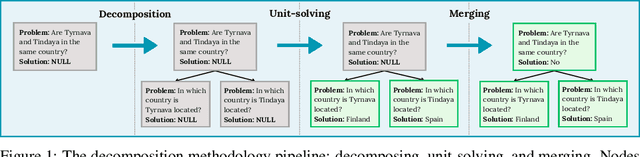
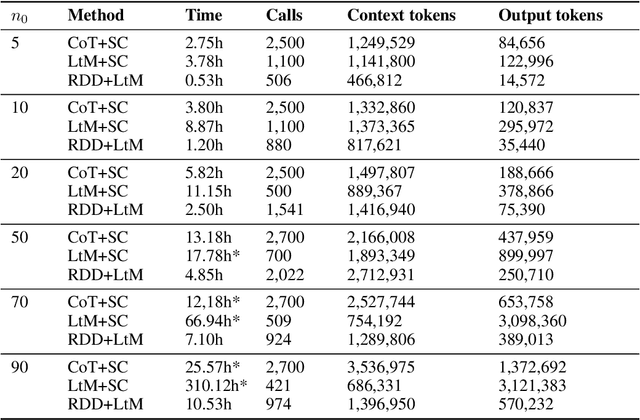
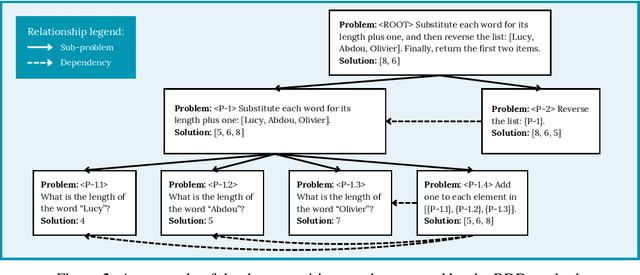
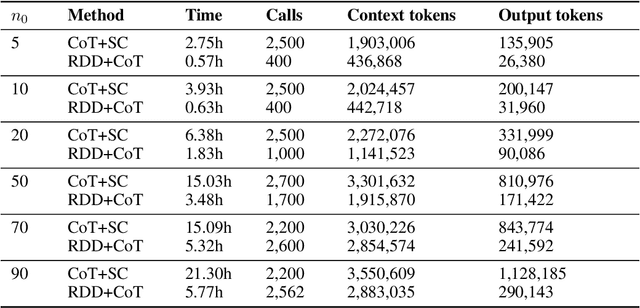
Reasoning tasks are crucial in many domains, especially in science and engineering. Although large language models (LLMs) have made progress in reasoning tasks using techniques such as chain-of-thought and least-to-most prompting, these approaches still do not effectively scale to complex problems in either their performance or execution time. Moreover, they often require additional supervision for each new task, such as in-context examples. In this work, we introduce Recursive Decomposition with Dependencies (RDD), a scalable divide-and-conquer method for solving reasoning problems that requires less supervision than prior approaches. Our method can be directly applied to a new problem class even in the absence of any task-specific guidance. Furthermore, RDD supports sub-task dependencies, allowing for ordered execution of sub-tasks, as well as an error recovery mechanism that can correct mistakes made in previous steps. We evaluate our approach on two benchmarks with six difficulty levels each and in two in-context settings: one with task-specific examples and one without. Our results demonstrate that RDD outperforms other methods in a compute-matched setting as task complexity increases, while also being more computationally efficient.
New multimodal similarity measure for image registration via modeling local functional dependence with linear combination of learned basis functions
Mar 07, 2025


The deformable registration of images of different modalities, essential in many medical imaging applications, remains challenging. The main challenge is developing a robust measure for image overlap despite the compared images capturing different aspects of the underlying tissue. Here, we explore similarity metrics based on functional dependence between intensity values of registered images. Although functional dependence is too restrictive on the global scale, earlier work has shown competitive performance in deformable registration when such measures are applied over small enough contexts. We confirm this finding and further develop the idea by modeling local functional dependence via the linear basis function model with the basis functions learned jointly with the deformation. The measure can be implemented via convolutions, making it efficient to compute on GPUs. We release the method as an easy-to-use tool and show good performance on three datasets compared to well-established baseline and earlier functional dependence-based methods.