 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
May 19, 2025Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.
Recursive Decomposition with Dependencies for Generic Divide-and-Conquer Reasoning
May 05, 2025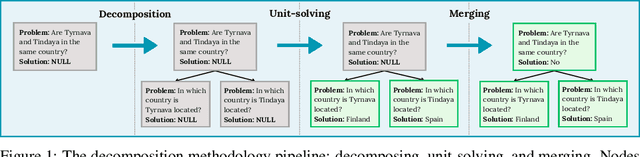
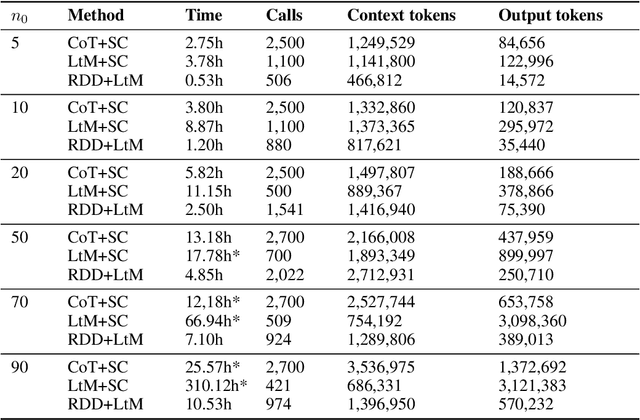
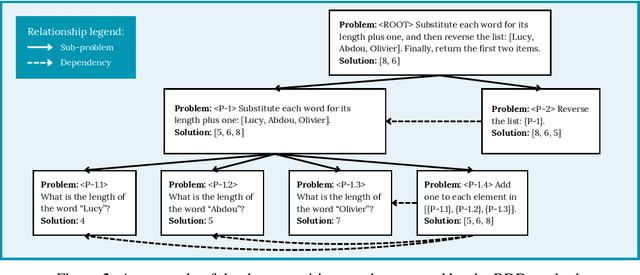
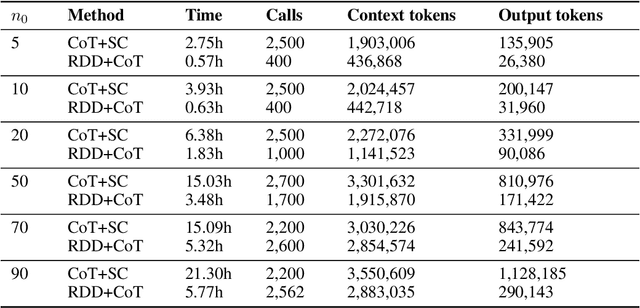
Reasoning tasks are crucial in many domains, especially in science and engineering. Although large language models (LLMs) have made progress in reasoning tasks using techniques such as chain-of-thought and least-to-most prompting, these approaches still do not effectively scale to complex problems in either their performance or execution time. Moreover, they often require additional supervision for each new task, such as in-context examples. In this work, we introduce Recursive Decomposition with Dependencies (RDD), a scalable divide-and-conquer method for solving reasoning problems that requires less supervision than prior approaches. Our method can be directly applied to a new problem class even in the absence of any task-specific guidance. Furthermore, RDD supports sub-task dependencies, allowing for ordered execution of sub-tasks, as well as an error recovery mechanism that can correct mistakes made in previous steps. We evaluate our approach on two benchmarks with six difficulty levels each and in two in-context settings: one with task-specific examples and one without. Our results demonstrate that RDD outperforms other methods in a compute-matched setting as task complexity increases, while also being more computationally efficient.
Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization
Feb 03, 2025As the general capabilities of artificial intelligence (AI) agents continue to evolve, their ability to learn to master multiple complex tasks through experience remains a key challenge. Current LLM agents, particularly those based on proprietary language models, typically rely on prompts to incorporate knowledge about the target tasks. This approach does not allow the agent to internalize this information and instead relies on ever-expanding prompts to sustain its functionality in diverse scenarios. This resembles a system of notes used by a person affected by anterograde amnesia, the inability to form new memories. In this paper, we propose a novel method to train AI agents to incorporate knowledge and skills for multiple tasks without the need for either cumbersome note systems or prior high-quality demonstration data. Our approach employs an iterative process where the agent collects new experiences, receives corrective feedback from humans in the form of hints, and integrates this feedback into its weights via a context distillation training procedure. We demonstrate the efficacy of our approach by implementing it in a Llama-3-based agent which, after only a few rounds of feedback, outperforms advanced models GPT-4o and DeepSeek-V3 in a taskset requiring correct sequencing of information retrieval, tool use, and question answering.
Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics
May 30, 2024Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate reinforcement learning actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.
Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search
May 24, 2024In this work we consider Code World Models, world models generated by a Large Language Model (LLM) in the form of Python code for model-based Reinforcement Learning (RL). Calling code instead of LLMs for planning has the advantages of being precise, reliable, interpretable, and extremely efficient. However, writing appropriate Code World Models requires the ability to understand complex instructions, to generate exact code with non-trivial logic and to self-debug a long program with feedback from unit tests and environment trajectories. To address these challenges, we propose Generate, Improve and Fix with Monte Carlo Tree Search (GIF-MCTS), a new code generation strategy for LLMs. To test our approach, we introduce the Code World Models Benchmark (CWMB), a suite of program synthesis and planning tasks comprised of 18 diverse RL environments paired with corresponding textual descriptions and curated trajectories. GIF-MCTS surpasses all baselines on the CWMB and two other benchmarks, and we show that the Code World Models synthesized with it can be successfully used for planning, resulting in model-based RL agents with greatly improved sample efficiency and inference speed.
Learning Reward Functions for Robotic Manipulation by Observing Humans
Nov 16, 2022Observing a human demonstrator manipulate objects provides a rich, scalable and inexpensive source of data for learning robotic policies. However, transferring skills from human videos to a robotic manipulator poses several challenges, not least a difference in action and observation spaces. In this work, we use unlabeled videos of humans solving a wide range of manipulation tasks to learn a task-agnostic reward function for robotic manipulation policies. Thanks to the diversity of this training data, the learned reward function sufficiently generalizes to image observations from a previously unseen robot embodiment and environment to provide a meaningful prior for directed exploration in reinforcement learning. The learned rewards are based on distances to a goal in an embedding space learned using a time-contrastive objective. By conditioning the function on a goal image, we are able to reuse one model across a variety of tasks. Unlike prior work on leveraging human videos to teach robots, our method, Human Offline Learned Distances (HOLD) requires neither a priori data from the robot environment, nor a set of task-specific human demonstrations, nor a predefined notion of correspondence across morphologies, yet it is able to accelerate training of several manipulation tasks on a simulated robot arm compared to using only a sparse reward obtained from task completion.
Residual Reinforcement Learning from Demonstrations
Jun 15, 2021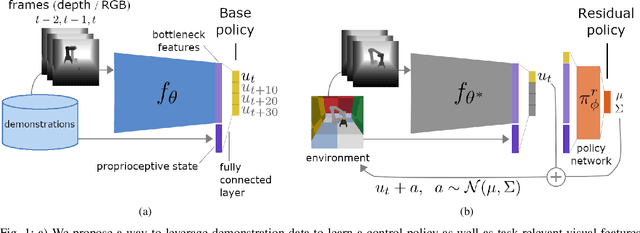



Residual reinforcement learning (RL) has been proposed as a way to solve challenging robotic tasks by adapting control actions from a conventional feedback controller to maximize a reward signal. We extend the residual formulation to learn from visual inputs and sparse rewards using demonstrations. Learning from images, proprioceptive inputs and a sparse task-completion reward relaxes the requirement of accessing full state features, such as object and target positions. In addition, replacing the base controller with a policy learned from demonstrations removes the dependency on a hand-engineered controller in favour of a dataset of demonstrations, which can be provided by non-experts. Our experimental evaluation on simulated manipulation tasks on a 6-DoF UR5 arm and a 28-DoF dexterous hand demonstrates that residual RL from demonstrations is able to generalize to unseen environment conditions more flexibly than either behavioral cloning or RL fine-tuning, and is capable of solving high-dimensional, sparse-reward tasks out of reach for RL from scratch.