 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Knowledge, Not Just Facts via Multi-Step Reasoning over Background Stories
Feb 02, 2026Enabling artificial intelligence systems, particularly large language models, to integrate new knowledge and flexibly apply it during reasoning remains a central challenge. Existing knowledge editing approaches emphasize atomic facts, improving factual recall but often failing to integrate new information into a coherent framework usable across contexts. In this work, we argue that knowledge internalization is fundamentally a reasoning problem rather than a memorization problem. Consequently, a model should be trained in situations where the new information is instrumental to solving a task, combined with pre-existing knowledge, and exercised through multi-step reasoning. Based on this insight, we propose a training strategy based on three principles. First, new knowledge is introduced as a coherent background story that contextualizes novel facts and explains their relation to existing knowledge. Second, models are trained using self-generated multi-hop questions that require multi-step reasoning involving the new information. Third, training is done using knowledge distillation, forcing a student model to internalize the teacher's reasoning behavior without access to the novel information. Experiments show that models trained with this strategy effectively leverage newly acquired knowledge during reasoning and achieve remarkable performance on challenging questions that require combining multiple new facts.
Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization
Feb 03, 2025As the general capabilities of artificial intelligence (AI) agents continue to evolve, their ability to learn to master multiple complex tasks through experience remains a key challenge. Current LLM agents, particularly those based on proprietary language models, typically rely on prompts to incorporate knowledge about the target tasks. This approach does not allow the agent to internalize this information and instead relies on ever-expanding prompts to sustain its functionality in diverse scenarios. This resembles a system of notes used by a person affected by anterograde amnesia, the inability to form new memories. In this paper, we propose a novel method to train AI agents to incorporate knowledge and skills for multiple tasks without the need for either cumbersome note systems or prior high-quality demonstration data. Our approach employs an iterative process where the agent collects new experiences, receives corrective feedback from humans in the form of hints, and integrates this feedback into its weights via a context distillation training procedure. We demonstrate the efficacy of our approach by implementing it in a Llama-3-based agent which, after only a few rounds of feedback, outperforms advanced models GPT-4o and DeepSeek-V3 in a taskset requiring correct sequencing of information retrieval, tool use, and question answering.
Knowledge Injection via Prompt Distillation
Dec 19, 2024


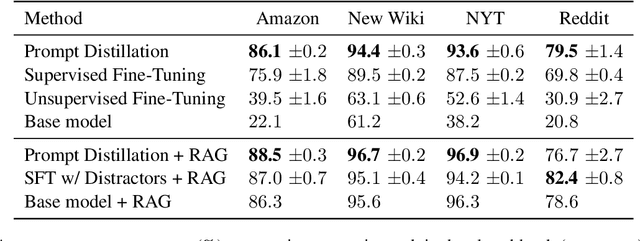
In many practical applications, large language models (LLMs) need to incorporate new knowledge not present in their pre-training data. The primary methods for this are fine-tuning and retrieval-augmented generation (RAG). Although RAG has emerged as the industry standard for knowledge injection, fine-tuning has not yet achieved comparable success. In this paper, we propose a new fine-tuning technique for learning new knowledge and show that it can reach the performance of RAG. The proposed method is based on the self-distillation approach, which we call prompt distillation. First, we generate question-answer pairs about the new knowledge. Then, we fine-tune a student model on the question-answer pairs to imitate the output distributions of a teacher model, which additionally receives the new knowledge in its prompt. The student model is identical to the teacher, except it is equipped with a LoRA adapter. This training procedure facilitates distilling the new knowledge from the teacher's prompt into the student's weights.
Regularizing Trajectory Optimization with Denoising Autoencoders
Mar 28, 2019

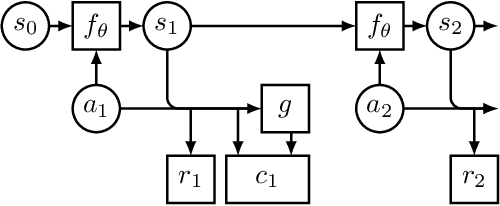

Trajectory optimization with learned dynamics models can often suffer from erroneous predictions of out-of-distribution trajectories. We propose to regularize trajectory optimization by means of a denoising autoencoder that is trained on the same trajectories as the dynamics model. We visually demonstrate the effectiveness of the regularization in gradient-based trajectory optimization for open-loop control of an industrial process. We compare with recent model-based reinforcement learning algorithms on a set of popular motor control tasks to demonstrate that the denoising regularization enables state-of-the-art sample-efficiency. We demonstrate the efficacy of the proposed method in regularizing both gradient-based and gradient-free trajectory optimization.
Improving Model-Based Control and Active Exploration with Reconstruction Uncertainty Optimization
Dec 10, 2018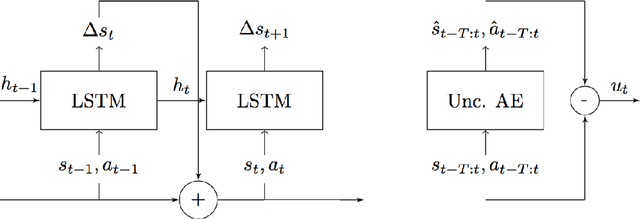

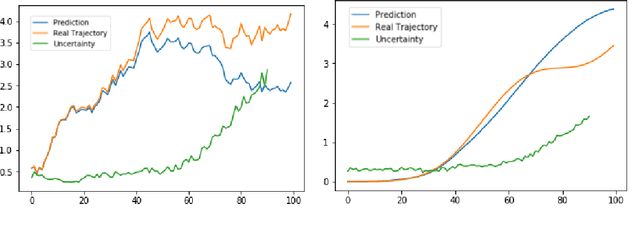
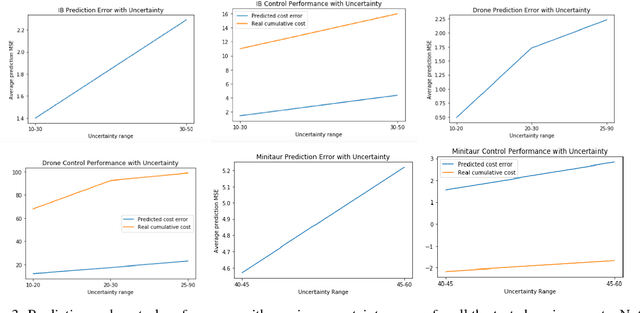
Model based predictions of future trajectories of a dynamical system often suffer from inaccuracies, forcing model based control algorithms to re-plan often, thus being computationally expensive, suboptimal and not reliable. In this work, we propose a model agnostic method for estimating the uncertainty of a model?s predictions based on reconstruction error, using it in control and exploration. As our experiments show, this uncertainty estimation can be used to improve control performance on a wide variety of environments by choosing predictions of which the model is confident. It can also be used for active learning to explore more efficiently the environment by planning for trajectories with high uncertainty, allowing faster model learning.
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Apr 16, 2018
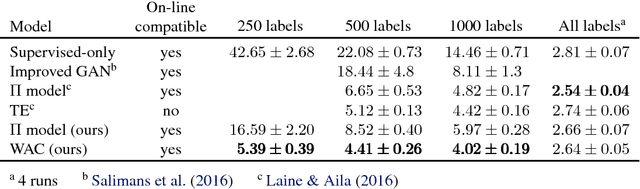
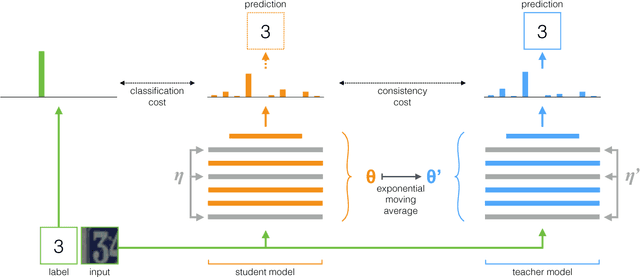
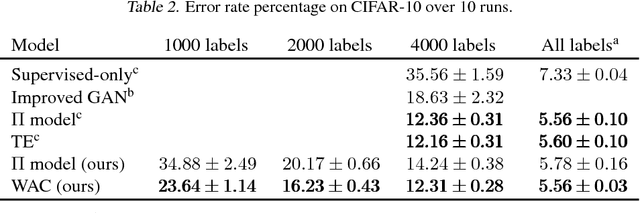
The recently proposed Temporal Ensembling has achieved state-of-the-art results in several semi-supervised learning benchmarks. It maintains an exponential moving average of label predictions on each training example, and penalizes predictions that are inconsistent with this target. However, because the targets change only once per epoch, Temporal Ensembling becomes unwieldy when learning large datasets. To overcome this problem, we propose Mean Teacher, a method that averages model weights instead of label predictions. As an additional benefit, Mean Teacher improves test accuracy and enables training with fewer labels than Temporal Ensembling. Without changing the network architecture, Mean Teacher achieves an error rate of 4.35% on SVHN with 250 labels, outperforming Temporal Ensembling trained with 1000 labels. We also show that a good network architecture is crucial to performance. Combining Mean Teacher and Residual Networks, we improve the state of the art on CIFAR-10 with 4000 labels from 10.55% to 6.28%, and on ImageNet 2012 with 10% of the labels from 35.24% to 9.11%.
Recurrent Ladder Networks
Dec 18, 2017
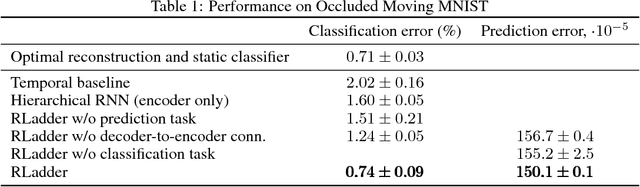
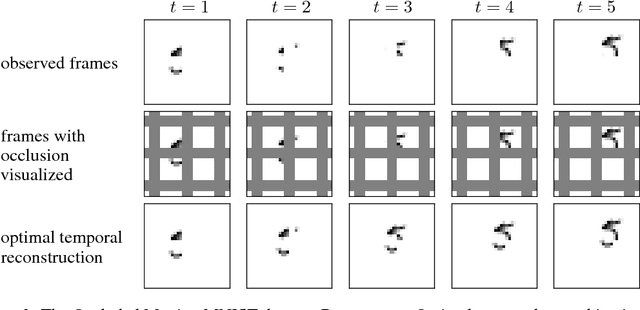

We propose a recurrent extension of the Ladder networks whose structure is motivated by the inference required in hierarchical latent variable models. We demonstrate that the recurrent Ladder is able to handle a wide variety of complex learning tasks that benefit from iterative inference and temporal modeling. The architecture shows close-to-optimal results on temporal modeling of video data, competitive results on music modeling, and improved perceptual grouping based on higher order abstractions, such as stochastic textures and motion cues. We present results for fully supervised, semi-supervised, and unsupervised tasks. The results suggest that the proposed architecture and principles are powerful tools for learning a hierarchy of abstractions, learning iterative inference and handling temporal information.
On the exact relationship between the denoising function and the data distribution
Sep 06, 2017We prove an exact relationship between the optimal denoising function and the data distribution in the case of additive Gaussian noise, showing that denoising implicitly models the structure of data allowing it to be exploited in the unsupervised learning of representations. This result generalizes a known relationship [2], which is valid only in the limit of small corruption noise.
Tagger: Deep Unsupervised Perceptual Grouping
Nov 28, 2016

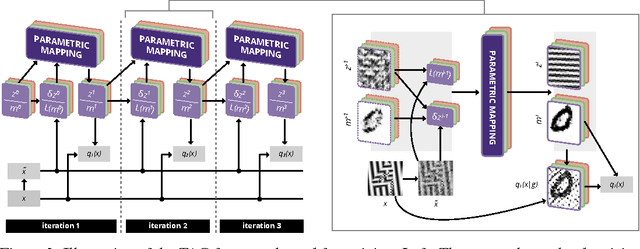
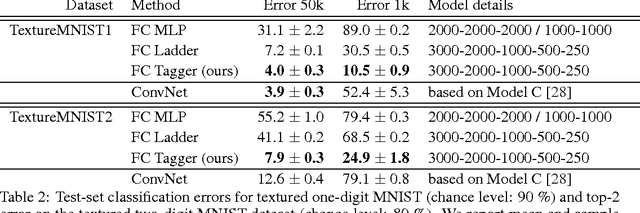
We present a framework for efficient perceptual inference that explicitly reasons about the segmentation of its inputs and features. Rather than being trained for any specific segmentation, our framework learns the grouping process in an unsupervised manner or alongside any supervised task. By enriching the representations of a neural network, we enable it to group the representations of different objects in an iterative manner. By allowing the system to amortize the iterative inference of the groupings, we achieve very fast convergence. In contrast to many other recently proposed methods for addressing multi-object scenes, our system does not assume the inputs to be images and can therefore directly handle other modalities. For multi-digit classification of very cluttered images that require texture segmentation, our method offers improved classification performance over convolutional networks despite being fully connected. Furthermore, we observe that our system greatly improves on the semi-supervised result of a baseline Ladder network on our dataset, indicating that segmentation can also improve sample efficiency.
Semi-Supervised Learning with Ladder Networks
Nov 24, 2015
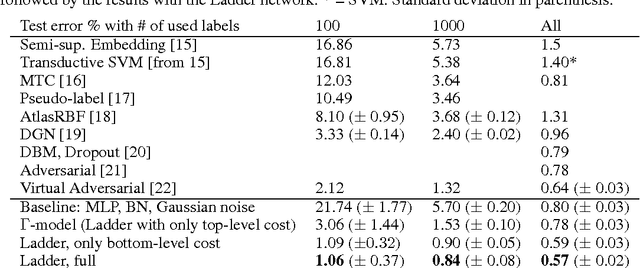


We combine supervised learning with unsupervised learning in deep neural networks. The proposed model is trained to simultaneously minimize the sum of supervised and unsupervised cost functions by backpropagation, avoiding the need for layer-wise pre-training. Our work builds on the Ladder network proposed by Valpola (2015), which we extend by combining the model with supervision. We show that the resulting model reaches state-of-the-art performance in semi-supervised MNIST and CIFAR-10 classification, in addition to permutation-invariant MNIST classification with all labels.