 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqDeepRx: Learning a Scalable MIMO Receiver
Feb 12, 2026While machine learning (ML)-based receiver algorithms have received a great deal of attention in the recent literature, they often suffer from poor scaling with increasing spatial multiplexing order and lack of explainability and generalization. This paper presents EqDeepRx, a practical deep-learning-aided multiple-input multiple-output (MIMO) receiver, which is built by augmenting linear receiver processing with carefully engineered ML blocks. At the core of the receiver model is a shared-weight DetectorNN that operates independently on each spatial stream or layer, enabling near-linear complexity scaling with respect to multiplexing order. To ensure better explainability and generalization, EqDeepRx retains conventional channel estimation and augments it with a lightweight DenoiseNN that learns frequency-domain smoothing. To reduce the dimensionality of the DetectorNN inputs, the receiver utilizes two linear equalizers in parallel: a linear minimum mean-square error (LMMSE) equalizer with interference-plus-noise covariance estimation and a regularized zero-forcing (RZF) equalizer. The parallel equalized streams are jointly consumed by the DetectorNN, after which a compact DemapperNN produces bit log-likelihood ratios for channel decoding. 5G/6G-compliant end-to-end simulations across multiple channel scenarios, pilot patterns, and inter-cell interference conditions show improved error rate and spectral efficiency over a conventional baseline, while maintaining low-complexity inference and support for different MIMO configurations without retraining.
Low-Complexity Inference in Continual Learning via Compressed Knowledge Transfer
May 13, 2025Continual learning (CL) aims to train models that can learn a sequence of tasks without forgetting previously acquired knowledge. A core challenge in CL is balancing stability -- preserving performance on old tasks -- and plasticity -- adapting to new ones. Recently, large pre-trained models have been widely adopted in CL for their ability to support both, offering strong generalization for new tasks and resilience against forgetting. However, their high computational cost at inference time limits their practicality in real-world applications, especially those requiring low latency or energy efficiency. To address this issue, we explore model compression techniques, including pruning and knowledge distillation (KD), and propose two efficient frameworks tailored for class-incremental learning (CIL), a challenging CL setting where task identities are unavailable during inference. The pruning-based framework includes pre- and post-pruning strategies that apply compression at different training stages. The KD-based framework adopts a teacher-student architecture, where a large pre-trained teacher transfers downstream-relevant knowledge to a compact student. Extensive experiments on multiple CIL benchmarks demonstrate that the proposed frameworks achieve a better trade-off between accuracy and inference complexity, consistently outperforming strong baselines. We further analyze the trade-offs between the two frameworks in terms of accuracy and efficiency, offering insights into their use across different scenarios.
Adapting to Reality: Over-the-Air Validation of AI-Based Receivers Trained with Simulated Channels
Aug 08, 2024Recent research has shown that integrating artificial intelligence (AI) into wireless communication systems can significantly improve spectral efficiency. However, the prevalent use of simulated radio channel data for training and validating neural network-based radios raises concerns about their generalization capability to diverse real-world environments. To address this, we conducted empirical over-the-air (OTA) experiments using software-defined radio (SDR) technology to test the performance of an NN-based orthogonal frequency division multiplexing (OFDM) receiver in a real-world small cell scenario. Our assessment reveals that the performance of receivers trained on diverse 3GPP TS38.901 channel models and broad parameter ranges significantly surpasses conventional receivers in our testing environment, demonstrating strong generalization to a new environment. Conversely, setting simulation parameters to narrowly reflect the actual measurement environment led to suboptimal OTA performance, highlighting the crucial role of rich and randomized training data in improving the NN-based receiver's performance. While our empirical test results are promising, they also suggest that developing new channel models tailored for training these learned receivers would enhance their generalization capability and reduce training time. Our testing was limited to a relatively narrow environment, and we encourage further testing in more complex environments.
Deep Learning-Based Pilotless Spatial Multiplexing
Dec 08, 2023This paper investigates the feasibility of machine learning (ML)-based pilotless spatial multiplexing in multiple-input and multiple-output (MIMO) communication systems. Especially, it is shown that by training the transmitter and receiver jointly, the transmitter can learn such constellation shapes for the spatial streams which facilitate completely blind separation and detection by the simultaneously learned receiver. To the best of our knowledge, this is the first time ML-based spatial multiplexing without channel estimation pilots is demonstrated. The results show that the learned pilotless scheme can outperform a conventional pilot-based system by as much as 15-20% in terms of spectral efficiency, depending on the modulation order and signal-to-noise ratio.
DeepTx: Deep Learning Beamforming with Channel Prediction
Feb 21, 2022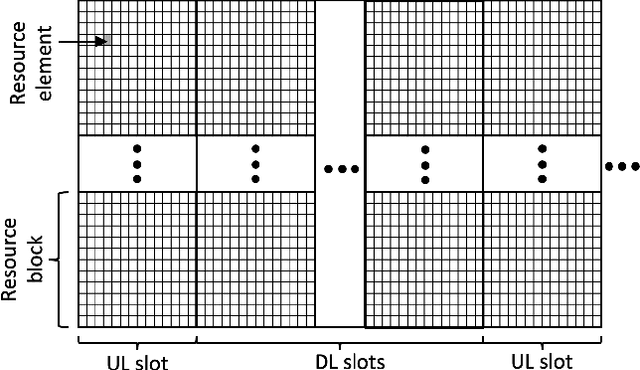
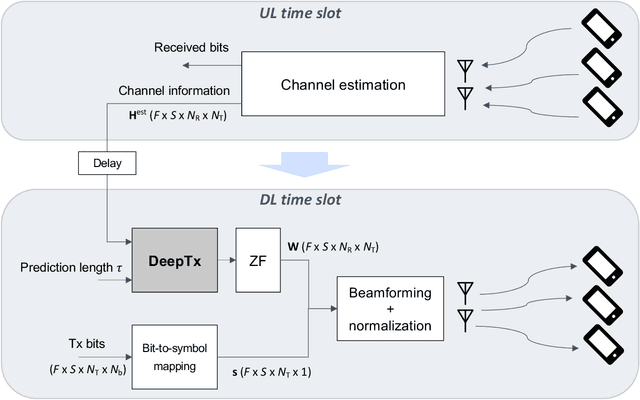
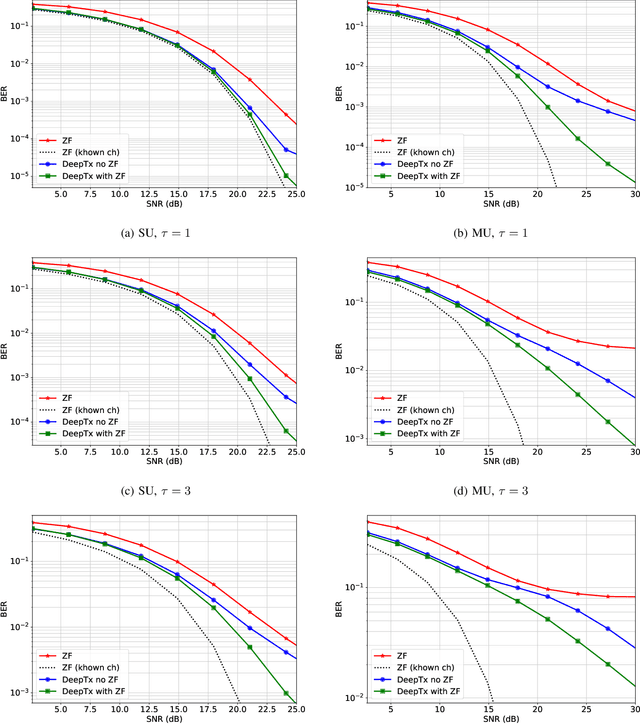
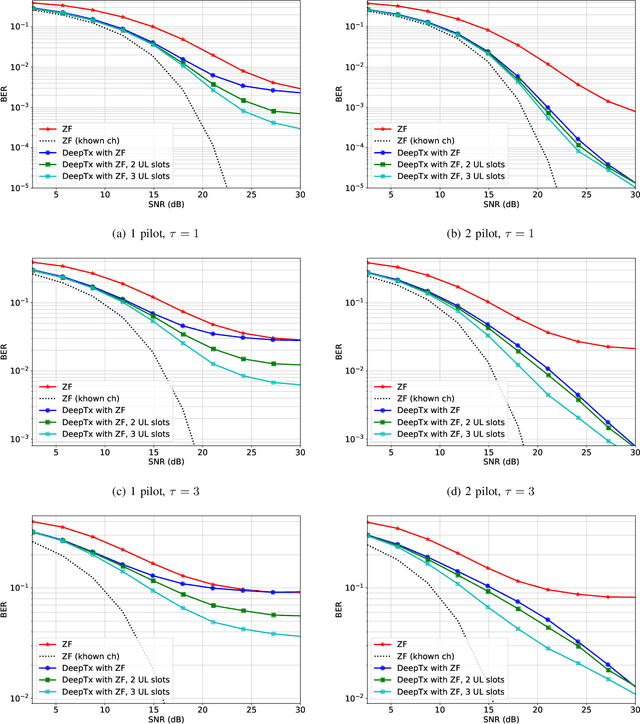
Machine learning algorithms have recently been considered for many tasks in the field of wireless communications. Previously, we have proposed the use of a deep fully convolutional neural network (CNN) for receiver processing and shown it to provide considerable performance gains. In this study, we focus on machine learning algorithms for the transmitter. In particular, we consider beamforming and propose a CNN which, for a given uplink channel estimate as input, outputs downlink channel information to be used for beamforming. The CNN is trained in a supervised manner considering both uplink and downlink transmissions with a loss function that is based on UE receiver performance. The main task of the neural network is to predict the channel evolution between uplink and downlink slots, but it can also learn to handle inefficiencies and errors in the whole chain, including the actual beamforming phase. The provided numerical experiments demonstrate the improved beamforming performance.
Waveform Learning for Reduced Out-of-Band Emissions Under a Nonlinear Power Amplifier
Jan 14, 2022
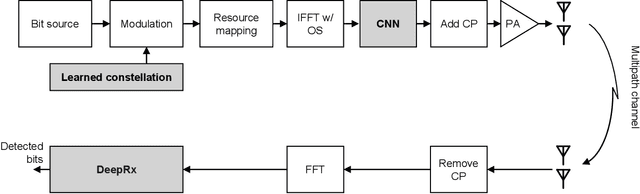
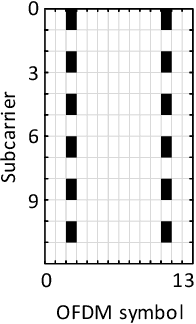
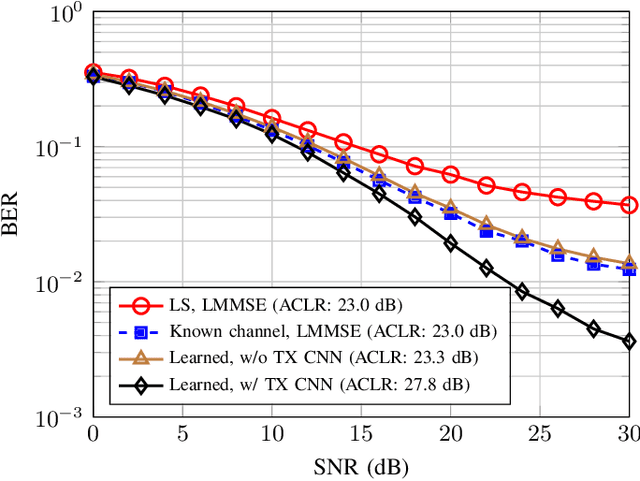
Machine learning (ML) has shown great promise in optimizing various aspects of the physical layer processing in wireless communication systems. In this paper, we use ML to learn jointly the transmit waveform and the frequency-domain receiver. In particular, we consider a scenario where the transmitter power amplifier is operating in a nonlinear manner, and ML is used to optimize the waveform to minimize the out-of-band emissions. The system also learns a constellation shape that facilitates pilotless detection by the simultaneously learned receiver. The simulation results show that such an end-to-end optimized system can communicate data more accurately and with less out-of-band emissions than conventional systems, thereby demonstrating the potential of ML in optimizing the air interface. To the best of our knowledge, there are no prior works considering the power amplifier induced emissions in an end-to-end learned system. These findings pave the way towards an ML-native air interface, which could be one of the building blocks of 6G.
HybridDeepRx: Deep Learning Receiver for High-EVM Signals
Jun 30, 2021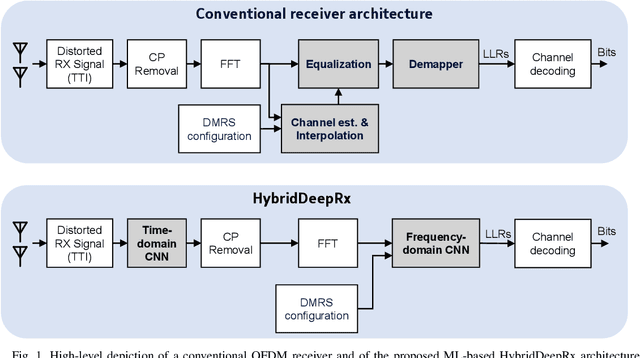
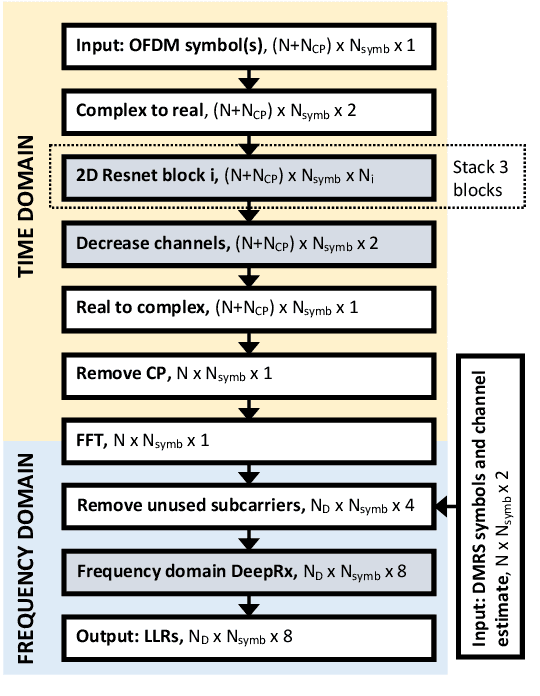
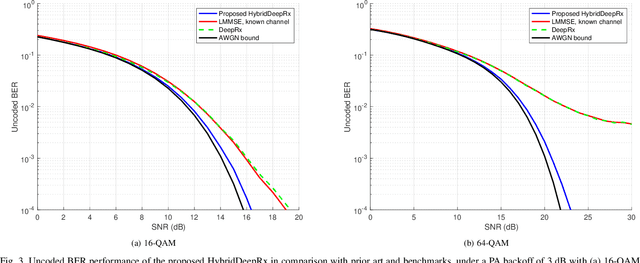
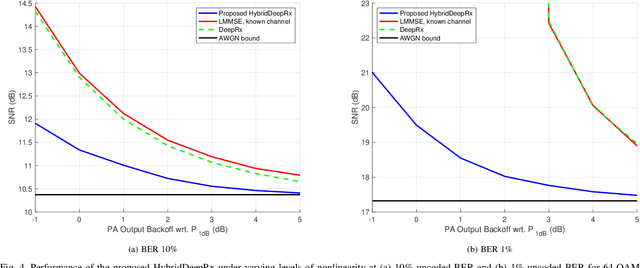
In this paper, we propose a machine learning (ML) based physical layer receiver solution for demodulating OFDM signals that are subject to a high level of nonlinear distortion. Specifically, a novel deep learning based convolutional neural network receiver is devised, containing layers in both time- and frequency domains, allowing to demodulate and decode the transmitted bits reliably despite the high error vector magnitude (EVM) in the transmit signal. Extensive set of numerical results is provided, in the context of 5G NR uplink incorporating also measured terminal power amplifier characteristics. The obtained results show that the proposed receiver system is able to clearly outperform classical linear receivers as well as existing ML receiver approaches, especially when the EVM is high in comparison with modulation order. The proposed ML receiver can thus facilitate pushing the terminal power amplifier (PA) systems deeper into saturation, and thereon improve the terminal power-efficiency, radiated power and network coverage.
DeepRx MIMO: Convolutional MIMO Detection with Learned Multiplicative Transformations
Oct 30, 2020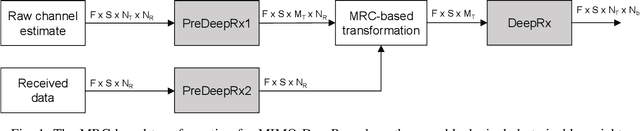
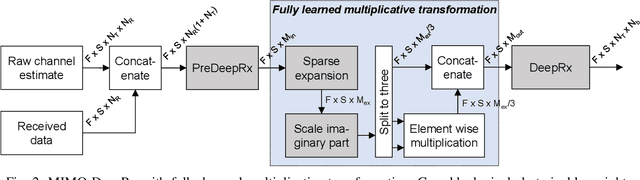
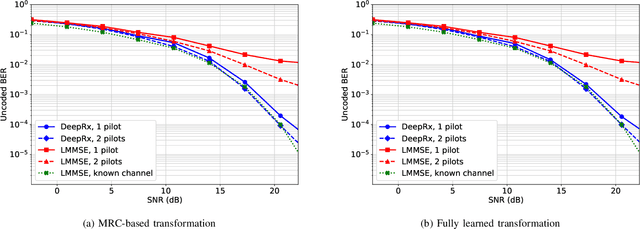

Recently, deep learning has been proposed as a potential technique for improving the physical layer performance of radio receivers. Despite the large amount of encouraging results, most works have not considered spatial multiplexing in the context of multiple-input and multiple-output (MIMO) receivers. In this paper, we present a deep learning-based MIMO receiver architecture that consists of a ResNet-based convolutional neural network, also known as DeepRx, combined with a so-called transformation layer, all trained together. We propose two novel alternatives for the transformation layer: a maximal ratio combining-based transformation, or a fully learned transformation. The former relies more on expert knowledge, while the latter utilizes learned multiplicative layers. Both proposed transformation layers are shown to clearly outperform the conventional baseline receiver, especially with sparse pilot configurations. To the best of our knowledge, these are some of the first results showing such high performance for a fully learned MIMO receiver.
DeepRx: Fully Convolutional Deep Learning Receiver
May 04, 2020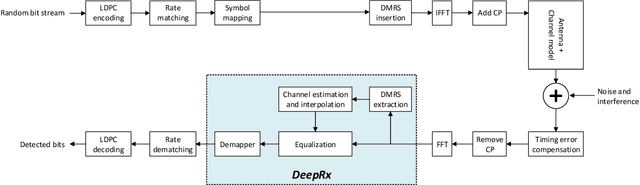

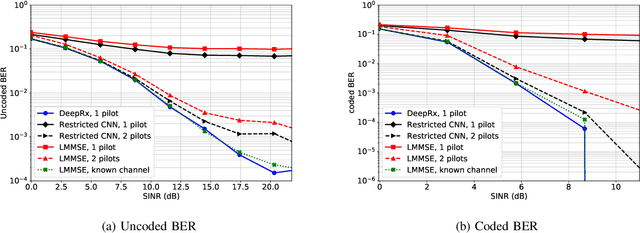
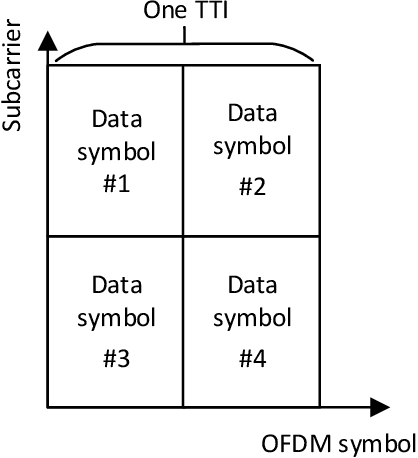
Deep learning has solved many problems that are out of reach of heuristic algorithms. It has also been successfully applied in wireless communications, even though the current radio systems are well-understood and optimal algorithms exist for many tasks. While some gains have been obtained by learning individual parts of a receiver, a better approach is to jointly learn the whole receiver. This, however, often results in a challenging nonlinear problem, for which the optimal solution is infeasible to implement. To this end, we propose a deep fully convolutional neural network, DeepRx, which executes the whole receiver pipeline from frequency domain signal stream to uncoded bits in a 5G-compliant fashion. We facilitate accurate channel estimation by constructing the input of the convolutional neural network in a very specific manner using both the data and pilot symbols. Also, DeepRx outputs soft bits that are compatible with the channel coding used in 5G systems. Using 3GPP-defined channel models, we demonstrate that DeepRx outperforms traditional methods. We also show that the high performance can likely be attributed to DeepRx learning to utilize the known constellation points of the unknown data symbols, together with the local symbol distribution, for improved detection accuracy.
Video Ladder Networks
Dec 30, 2016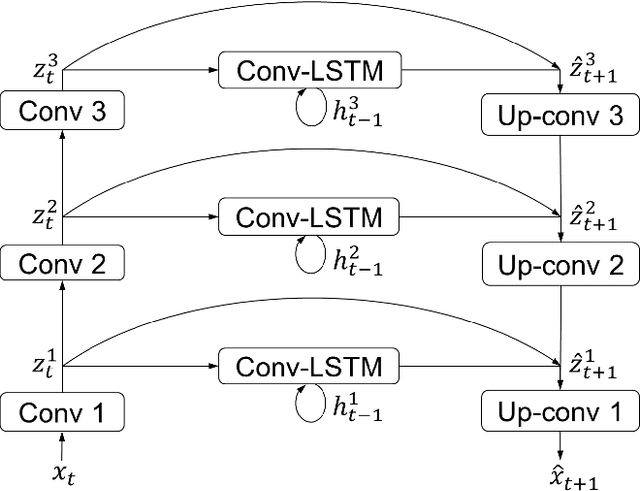
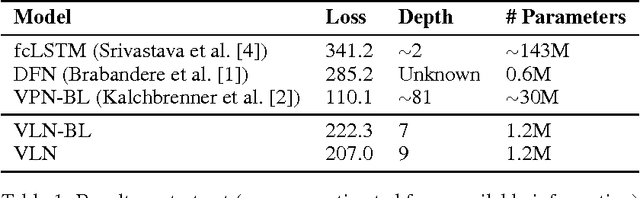
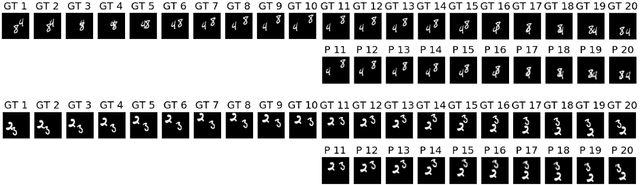
We present the Video Ladder Network (VLN) for efficiently generating future video frames. VLN is a neural encoder-decoder model augmented at all layers by both recurrent and feedforward lateral connections. At each layer, these connections form a lateral recurrent residual block, where the feedforward connection represents a skip connection and the recurrent connection represents the residual. Thanks to the recurrent connections, the decoder can exploit temporal summaries generated from all layers of the encoder. This way, the top layer is relieved from the pressure of modeling lower-level spatial and temporal details. Furthermore, we extend the basic version of VLN to incorporate ResNet-style residual blocks in the encoder and decoder, which help improving the prediction results. VLN is trained in self-supervised regime on the Moving MNIST dataset, achieving competitive results while having very simple structure and providing fast inference.