 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Character-Word Compositional Neural Language Model for Finnish
Dec 10, 2016
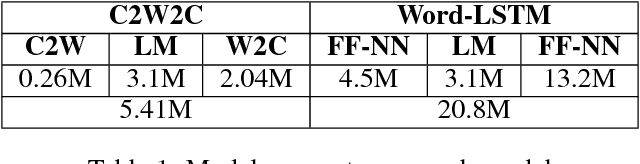


Inspired by recent research, we explore ways to model the highly morphological Finnish language at the level of characters while maintaining the performance of word-level models. We propose a new Character-to-Word-to-Character (C2W2C) compositional language model that uses characters as input and output while still internally processing word level embeddings. Our preliminary experiments, using the Finnish Europarl V7 corpus, indicate that C2W2C can respond well to the challenges of morphologically rich languages such as high out of vocabulary rates, the prediction of novel words, and growing vocabulary size. Notably, the model is able to correctly score inflectional forms that are not present in the training data and sample grammatically and semantically correct Finnish sentences character by character.
Scalable Gradient-Based Tuning of Continuous Regularization Hyperparameters
Jun 17, 2016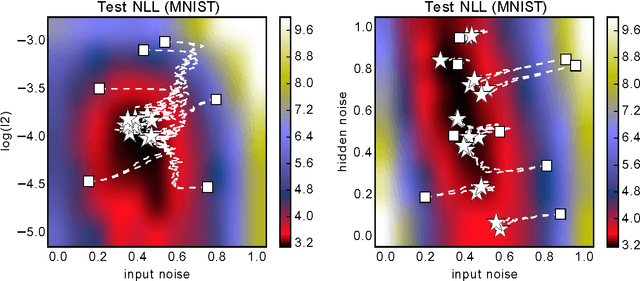

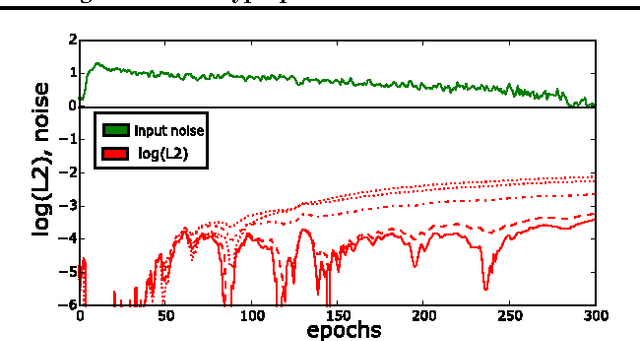
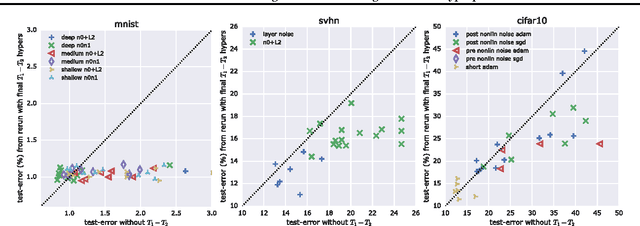
Hyperparameter selection generally relies on running multiple full training trials, with selection based on validation set performance. We propose a gradient-based approach for locally adjusting hyperparameters during training of the model. Hyperparameters are adjusted so as to make the model parameter gradients, and hence updates, more advantageous for the validation cost. We explore the approach for tuning regularization hyperparameters and find that in experiments on MNIST, SVHN and CIFAR-10, the resulting regularization levels are within the optimal regions. The additional computational cost depends on how frequently the hyperparameters are trained, but the tested scheme adds only 30% computational overhead regardless of the model size. Since the method is significantly less computationally demanding compared to similar gradient-based approaches to hyperparameter optimization, and consistently finds good hyperparameter values, it can be a useful tool for training neural network models.
DopeLearning: A Computational Approach to Rap Lyrics Generation
Jun 09, 2016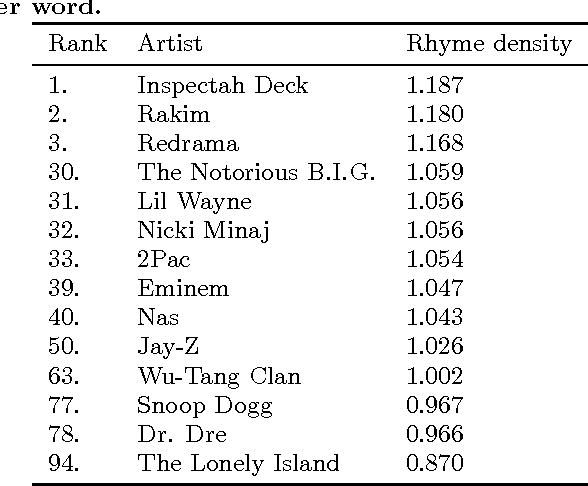
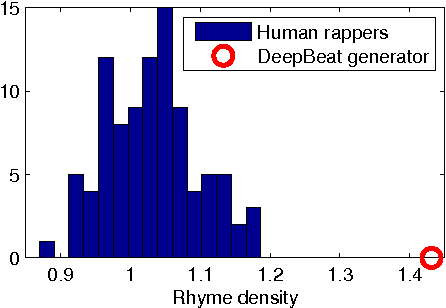

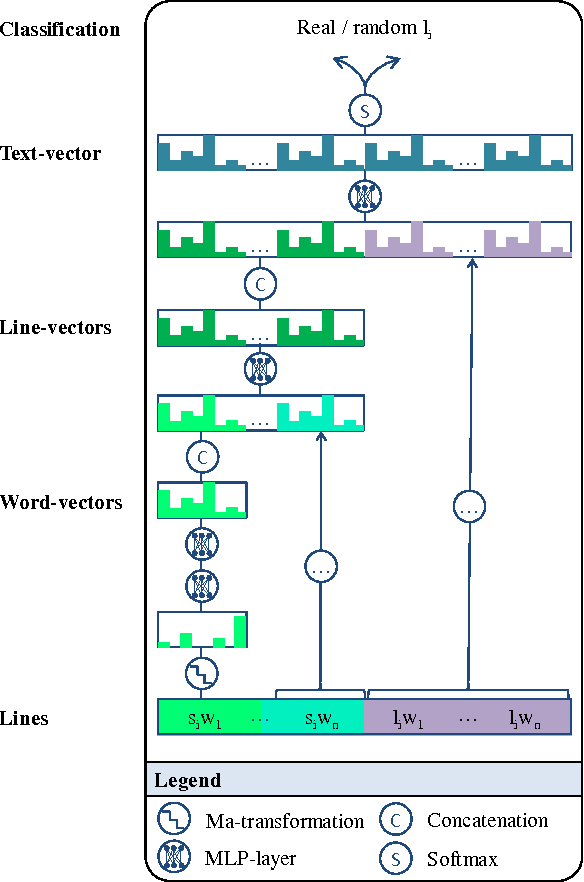
Writing rap lyrics requires both creativity to construct a meaningful, interesting story and lyrical skills to produce complex rhyme patterns, which form the cornerstone of good flow. We present a rap lyrics generation method that captures both of these aspects. First, we develop a prediction model to identify the next line of existing lyrics from a set of candidate next lines. This model is based on two machine-learning techniques: the RankSVM algorithm and a deep neural network model with a novel structure. Results show that the prediction model can identify the true next line among 299 randomly selected lines with an accuracy of 17%, i.e., over 50 times more likely than by random. Second, we employ the prediction model to combine lines from existing songs, producing lyrics with rhyme and a meaning. An evaluation of the produced lyrics shows that in terms of quantitative rhyme density, the method outperforms the best human rappers by 21%. The rap lyrics generator has been deployed as an online tool called DeepBeat, and the performance of the tool has been assessed by analyzing its usage logs. This analysis shows that machine-learned rankings correlate with user preferences.
Semi-Supervised Domain Adaptation for Weakly Labeled Semantic Video Object Segmentation
Jun 07, 2016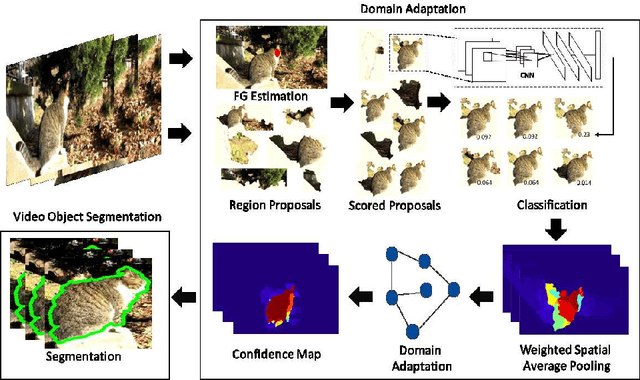
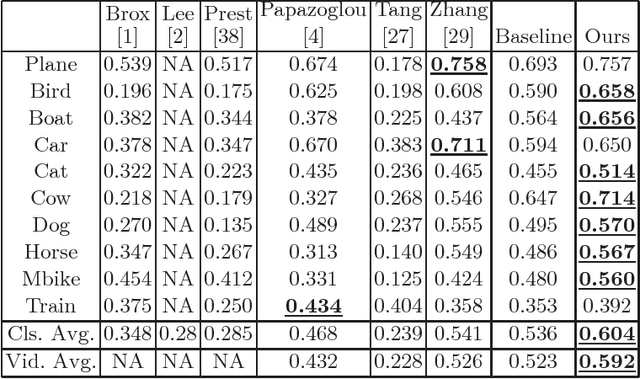


Deep convolutional neural networks (CNNs) have been immensely successful in many high-level computer vision tasks given large labeled datasets. However, for video semantic object segmentation, a domain where labels are scarce, effectively exploiting the representation power of CNN with limited training data remains a challenge. Simply borrowing the existing pretrained CNN image recognition model for video segmentation task can severely hurt performance. We propose a semi-supervised approach to adapting CNN image recognition model trained from labeled image data to the target domain exploiting both semantic evidence learned from CNN, and the intrinsic structures of video data. By explicitly modeling and compensating for the domain shift from the source domain to the target domain, this proposed approach underpins a robust semantic object segmentation method against the changes in appearance, shape and occlusion in natural videos. We present extensive experiments on challenging datasets that demonstrate the superior performance of our approach compared with the state-of-the-art methods.
Ladder Variational Autoencoders
May 27, 2016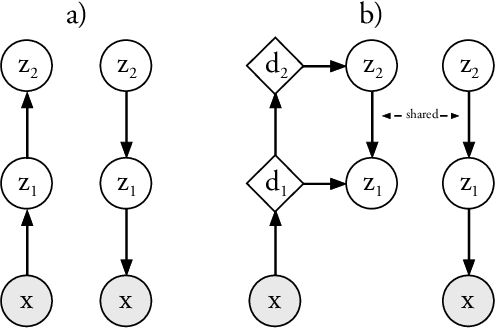

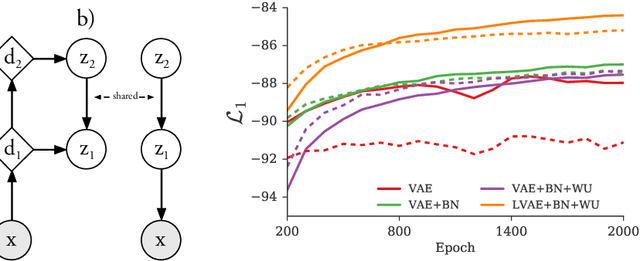
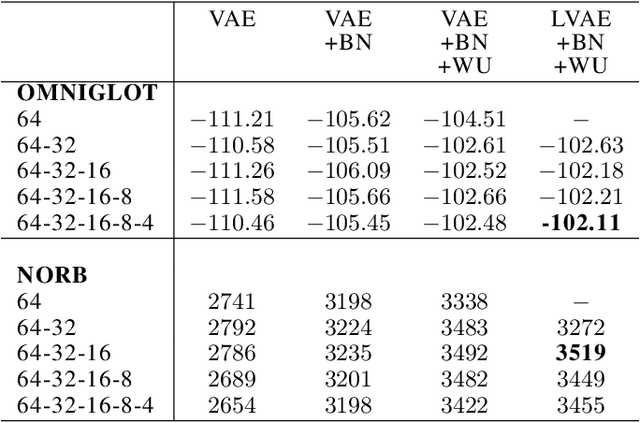
Variational Autoencoders are powerful models for unsupervised learning. However deep models with several layers of dependent stochastic variables are difficult to train which limits the improvements obtained using these highly expressive models. We propose a new inference model, the Ladder Variational Autoencoder, that recursively corrects the generative distribution by a data dependent approximate likelihood in a process resembling the recently proposed Ladder Network. We show that this model provides state of the art predictive log-likelihood and tighter log-likelihood lower bound compared to the purely bottom-up inference in layered Variational Autoencoders and other generative models. We provide a detailed analysis of the learned hierarchical latent representation and show that our new inference model is qualitatively different and utilizes a deeper more distributed hierarchy of latent variables. Finally, we observe that batch normalization and deterministic warm-up (gradually turning on the KL-term) are crucial for training variational models with many stochastic layers.
Semi-Supervised Learning with Ladder Networks
Nov 24, 2015
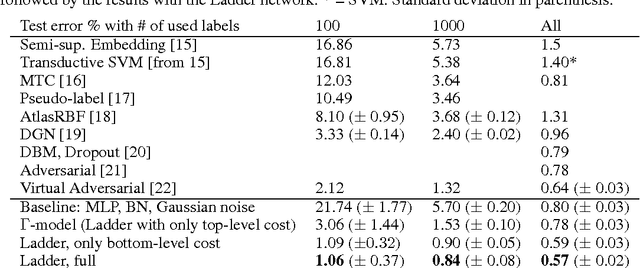


We combine supervised learning with unsupervised learning in deep neural networks. The proposed model is trained to simultaneously minimize the sum of supervised and unsupervised cost functions by backpropagation, avoiding the need for layer-wise pre-training. Our work builds on the Ladder network proposed by Valpola (2015), which we extend by combining the model with supervision. We show that the resulting model reaches state-of-the-art performance in semi-supervised MNIST and CIFAR-10 classification, in addition to permutation-invariant MNIST classification with all labels.
Bidirectional Recurrent Neural Networks as Generative Models - Reconstructing Gaps in Time Series
Nov 02, 2015

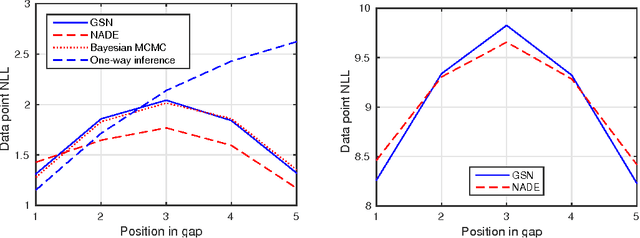
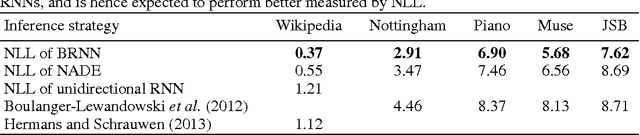
Bidirectional recurrent neural networks (RNN) are trained to predict both in the positive and negative time directions simultaneously. They have not been used commonly in unsupervised tasks, because a probabilistic interpretation of the model has been difficult. Recently, two different frameworks, GSN and NADE, provide a connection between reconstruction and probabilistic modeling, which makes the interpretation possible. As far as we know, neither GSN or NADE have been studied in the context of time series before. As an example of an unsupervised task, we study the problem of filling in gaps in high-dimensional time series with complex dynamics. Although unidirectional RNNs have recently been trained successfully to model such time series, inference in the negative time direction is non-trivial. We propose two probabilistic interpretations of bidirectional RNNs that can be used to reconstruct missing gaps efficiently. Our experiments on text data show that both proposed methods are much more accurate than unidirectional reconstructions, although a bit less accurate than a computationally complex bidirectional Bayesian inference on the unidirectional RNN. We also provide results on music data for which the Bayesian inference is computationally infeasible, demonstrating the scalability of the proposed methods.
Lateral Connections in Denoising Autoencoders Support Supervised Learning
Apr 30, 2015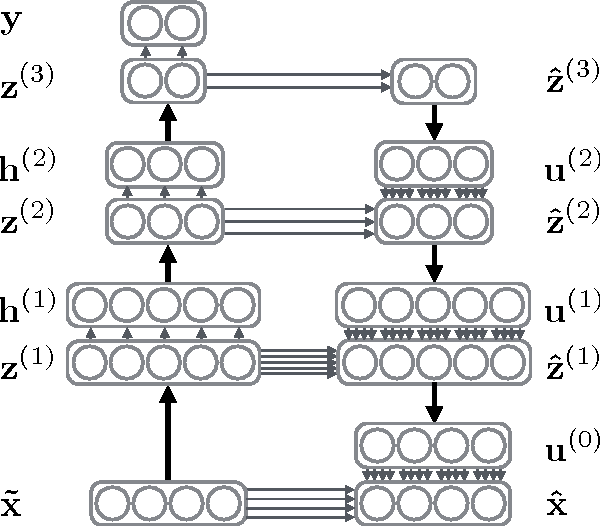

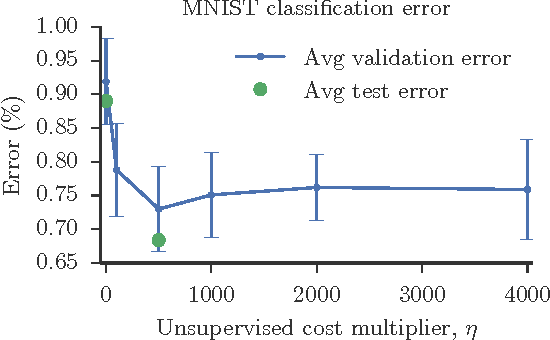
We show how a deep denoising autoencoder with lateral connections can be used as an auxiliary unsupervised learning task to support supervised learning. The proposed model is trained to minimize simultaneously the sum of supervised and unsupervised cost functions by back-propagation, avoiding the need for layer-wise pretraining. It improves the state of the art significantly in the permutation-invariant MNIST classification task.
Techniques for Learning Binary Stochastic Feedforward Neural Networks
Apr 09, 2015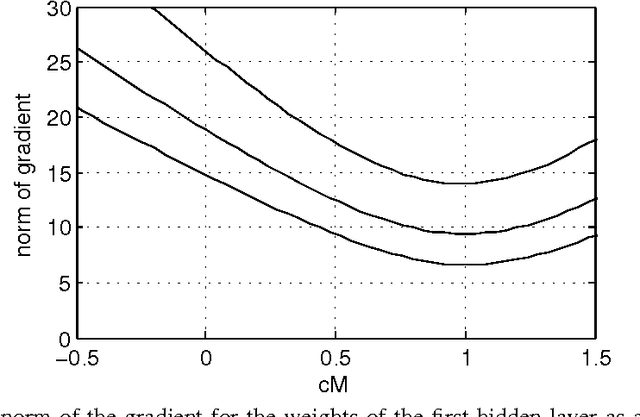
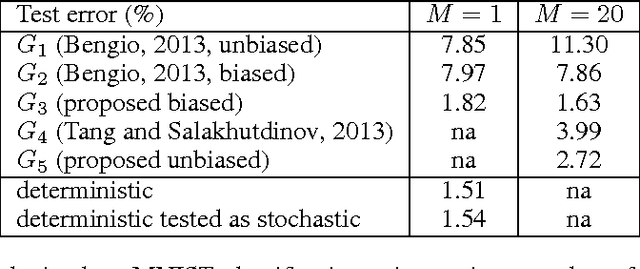
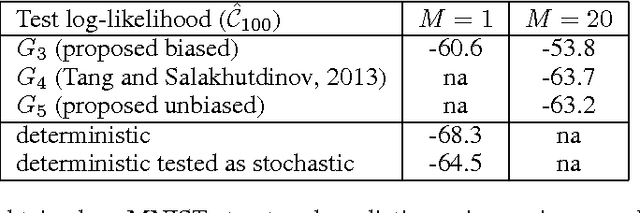
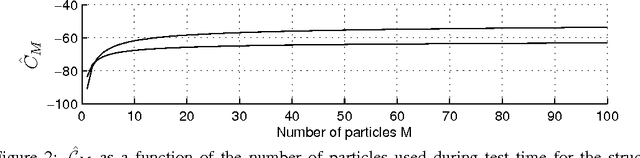
Stochastic binary hidden units in a multi-layer perceptron (MLP) network give at least three potential benefits when compared to deterministic MLP networks. (1) They allow to learn one-to-many type of mappings. (2) They can be used in structured prediction problems, where modeling the internal structure of the output is important. (3) Stochasticity has been shown to be an excellent regularizer, which makes generalization performance potentially better in general. However, training stochastic networks is considerably more difficult. We study training using M samples of hidden activations per input. We show that the case M=1 leads to a fundamentally different behavior where the network tries to avoid stochasticity. We propose two new estimators for the training gradient and propose benchmark tests for comparing training algorithms. Our experiments confirm that training stochastic networks is difficult and show that the proposed two estimators perform favorably among all the five known estimators.
Denoising autoencoder with modulated lateral connections learns invariant representations of natural images
Mar 31, 2015
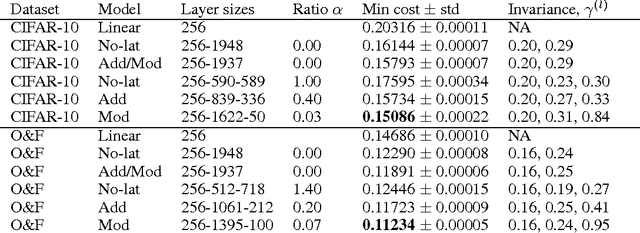

Suitable lateral connections between encoder and decoder are shown to allow higher layers of a denoising autoencoder (dAE) to focus on invariant representations. In regular autoencoders, detailed information needs to be carried through the highest layers but lateral connections from encoder to decoder relieve this pressure. It is shown that abstract invariant features can be translated to detailed reconstructions when invariant features are allowed to modulate the strength of the lateral connection. Three dAE structures with modulated and additive lateral connections, and without lateral connections were compared in experiments using real-world images. The experiments verify that adding modulated lateral connections to the model 1) improves the accuracy of the probability model for inputs, as measured by denoising performance; 2) results in representations whose degree of invariance grows faster towards the higher layers; and 3) supports the formation of diverse invariant poolings.