 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Domain Adaptation for Weakly Labeled Semantic Video Object Segmentation
Paper and Code
Jun 07, 2016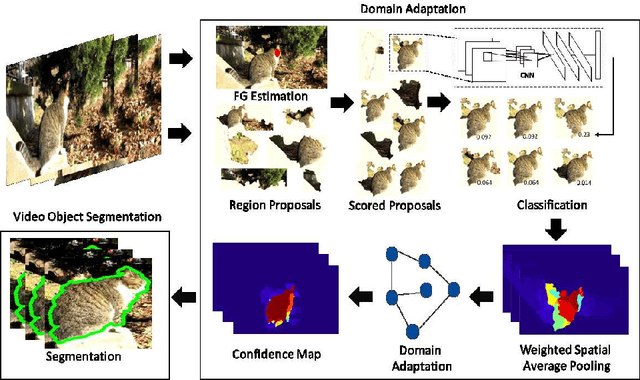
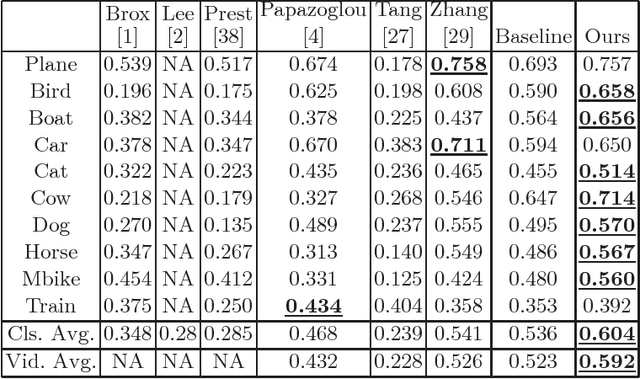


Deep convolutional neural networks (CNNs) have been immensely successful in many high-level computer vision tasks given large labeled datasets. However, for video semantic object segmentation, a domain where labels are scarce, effectively exploiting the representation power of CNN with limited training data remains a challenge. Simply borrowing the existing pretrained CNN image recognition model for video segmentation task can severely hurt performance. We propose a semi-supervised approach to adapting CNN image recognition model trained from labeled image data to the target domain exploiting both semantic evidence learned from CNN, and the intrinsic structures of video data. By explicitly modeling and compensating for the domain shift from the source domain to the target domain, this proposed approach underpins a robust semantic object segmentation method against the changes in appearance, shape and occlusion in natural videos. We present extensive experiments on challenging datasets that demonstrate the superior performance of our approach compared with the state-of-the-art methods.